
Top 10 papers we discovered at NeurIPS 2022
Two weeks ago we had the opportunity to attend NeurIPS 2022, a premier Conference in Artificial Intelligence and Machine Learning, which was held in New Orleans, United States. Many of the techniques and tools that we take for granted today, both in industry and academia, were presented in some editions of that Conference. For example, the famous and influential AlexNet paper from 2012 (which introduced the first convolutional neural network trained on the ImageNet database) was unanimously selected for the NeurIPS 2022 Test of Time award.
Although many of the works presented in the Conference are mainly theoretical and show their utility and potential in the long term, it is also possible to find works which are very applied and that provide implementations ready to use and try. As ML practitioners in industry, we pay special attention to these kinds of works. In this post we highlight a list of top-10 papers with code we discovered at NeurIPS 2022, and which we are excited to try and share.
Gradient Descent: The Ultimate Optimizer
This work was honored as an Outstanding Paper. The authors present a novel technique that enables gradient descent optimizers such as SGD and Adam to tune their hyperparameters automatically. The method requires no manual differentiation and can be stacked recursively to many levels.

|
|---|
.
Top-10 papers of NeurIPS 2022
1. Gradient Descent: The Ultimate Optimizer
This work was honored as an Outstanding Paper. In this work, the authors present a novel technique that enables gradient descent optimizers such as SGD and Adam to tune their hyperparameters automatically. The method requires no manual differentiation and can be stacked recursively to many levels.
⎋ Poster
⎋ Paper
⎋ Repository
⎋ Press Release
2. MABSplit: Faster Forest Training Using Multi-Armed Bandits
The authors present an algorithm that accelerates the training of random forests and other tree-based learning methods. At the core of the algorithm there is a novel node-splitting subroutine used to efficiently find split points when constructing decision trees. The algorithm borrows techniques from the multi-armed bandit literature to determine how to allocate samples and computational power across candidate split points.
3. Beyond L1: Faster and Better Sparse Models with skglm
The authors present a new fast algorithm to estimate sparse Generalized Linear Models (GLMs) with convex or non-convex separable penalties. The authors release a flexible, scikit-learn compatible package, which easily handles customized penalties.
4. SketchBoost: Fast Gradient Boosted Decision Tree for Multi-Output Problems
The authors present novel methods aiming to accelerate the training process of GBDT in the multi-output scenario, when the output is highly multidimensional. These methods are implemented in SketchBoost, which itself is integrated into the easily customizable Python-based GPU implementation of GBDT called Py-Boost.

⎋ Poster
⎋ Paper
⎋ Repository
⎋ Slides
5. Benchopt: Reproducible, efficient and collaborative optimization benchmarks
The authors present Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. It is written in Python but is available with many programming languages.
6. AutoWS-Bench-101: Benchmarking Automated Weak Supervision with 100 Labels
Weak supervision (WS) is a powerful method to build labeled datasets for training supervised models in the face of little-to-no labeled data. It replaces hand-labeling data with aggregating multiple noisy-but-cheap label estimates. The authors present AutoWS-Bench-101, a framework for evaluating automated WS techniques in challenging WS settings.
7. Pythae: Unifying Generative Autoencoders in Python – A Benchmarking Use Case
The authors present Pythae, a versatile Python library providing both a unified implementation and a dedicated framework allowing straightforward, reproducible and reliable use of generative autoencoder models. In particular, it provides the possibility to perform benchmark experiments and comparisons by training the models with the same autoencoding neural network architecture.
8. SnAKe: Bayesian Optimization with Pathwise Exploration
Inspired by applications to chemistry, the authors propose a method for optimizing black-box functions in a novel setting where the expense of evaluating the function can increase significantly when making large input changes between iterations, and under an asynchronous setting (meaning the algorithm has to decide on new queries before it finishes evaluating previous experiments).
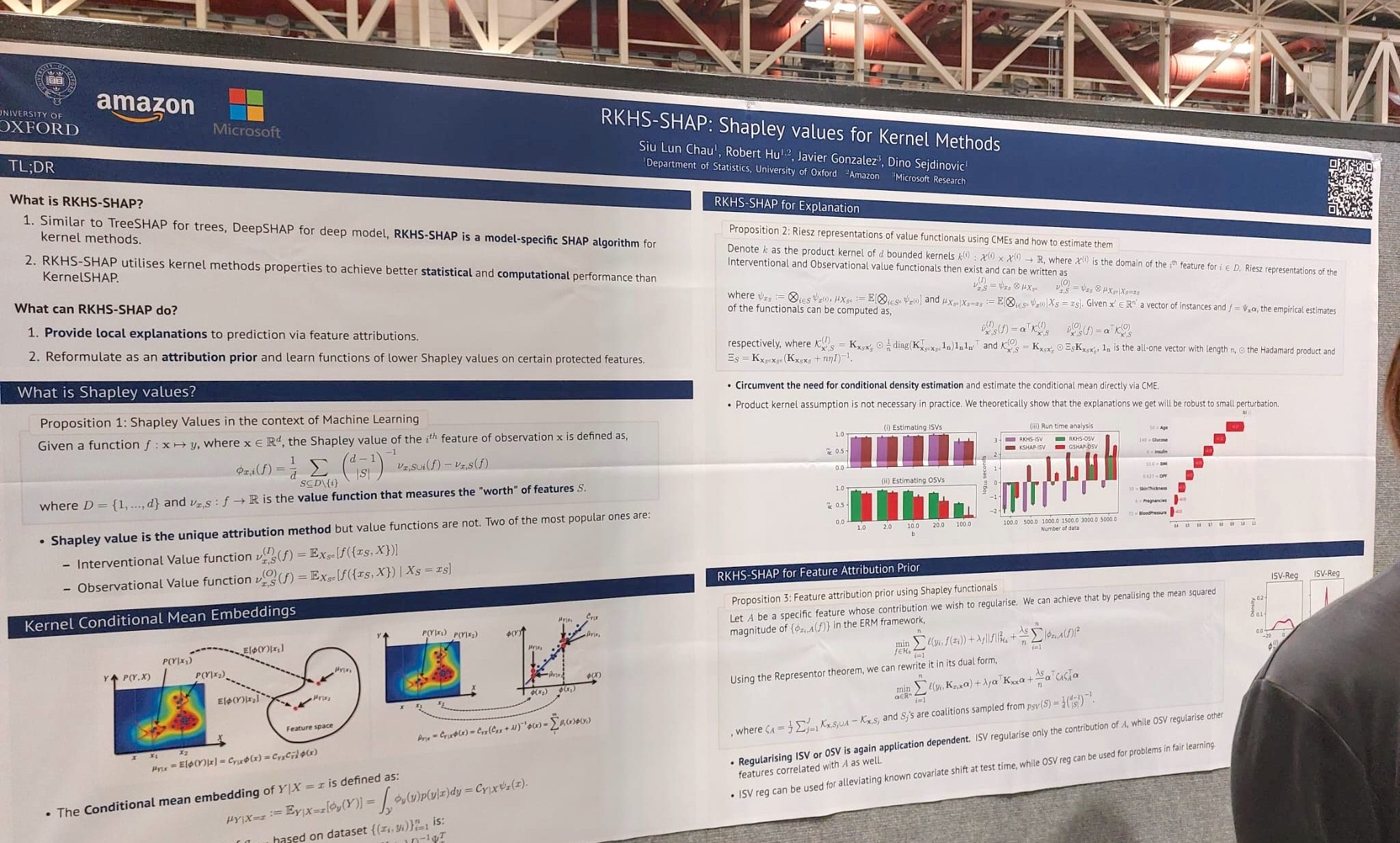
9. RKHS-SHAP: Shapley Values for Kernel Methods
Shapley values have previously been applied to different machine learning model interpretation tasks, such as linear models, tree ensembles and deep networks, but there was a lack of an extension for kernel methods. In this work, the authors propose a novel method for calculating Shapley values for kernel-based models and include both a theoretical analysis and extensive experimental evaluation.
10. Explaining Preferences with Shapley Values
In this work, the authors propose Pref-SHAP, a Shapley value-based model explanation framework for pairwise comparison data. To demonstrate the utility of the method, they apply it to a variety of synthetic and real-world datasets (including data from Pokémon battles!) and show that richer and more insightful explanations can be obtained over the baseline.
BONUS!
In his keynote speech, Geoff Hinton offered his thoughts on the future of machine learning and he talked about his latest research on the “Forward-Forward” (FF) algorithm, an alternative to the Backpropagation algorithm with biological motivations. The main ideas of the paper are cleverly summarized in this twitter thread. It will be interesting to see the influence of this new approach on the ML community in the years to come.
We hope this selection will be useful and makes you want to get down to work to check out the papers and try out the implementations. After three years and two virtual-only editions after the pandemic, it was great to be back in-person at NeurIPS and to feel that rush of exploring the latest advances and lines of research in the ML community by only walking through the halls and moving from session to session. Overall, the interaction with academics and professionals, and the discovery of amazing works have served for intellectual growth, inspiration, and to try to be up-to-date in the thrilling yet fast-moving ML field.