
Text categorization and tag suggestion in a single model
In this post, I would like to explain the topic of my work during the 2018 Internship, continuing the research I did in 2017 and explained in another post. The problem we try to solve is the joint classification and tag prediction for short texts.
Tag prediction and classification
This machine learning problem arises in practical applications such as categorizing product descriptions in ecommerce sites, classifying names of shops in business datasets or organizing titles / questions in online discussion forums. In applications related to banking, this problem can appear in transaction categorization engines, for instance as part of personal finance management applications, where the problem is to assign a category, and possibly tags, to an account transaction based on the words appearing in the transaction.
In all those cases, text strings describing products, shops or post titles can normally be classified in a main category (e.g. Joan’s Coffee Shop belongs to the category “Bars and Restaurants”), but it might want to infer other informative tags (such as “coffee” or “take-away”) as well.
Predicting categorical outputs, or predicting an open set of tags based on a short text can be tackled with deep learning techniques. However, both problems are not fully independent, since one may want to impose consistency on category and tags. Therefore, a challenge is how to design a model able to jointly learn tags and categories, given some input sentences (and possibly some known tags).
Additionally, there are situations where explainability is required, and thus we need insights of why a short text was assigned a given class. In the case of text classification, one example is pointing to the words that carried most of the information for classification, typically achieved through attention models. Again, a challenge would be how to add explainability to joint category and tag prediction. The final goal was to explore a neural network architecture that takes as input a sentence and optionally set of known tags, and is able to fulfill these three properties -we were not aware of any existing short sentence classification method with the three above properties-:
- Classify the sentence, taking into account the observed words and tags
- Predict missing tags, based on observed words and the other tags
- Score the input words and tags by importance; i.e. quantify or explain how much each observed word or tag contributes to the decision.
The model I present here uses a first attention model to build an embedding of a sentence in terms of the input words and tags. This embedding is used to score concepts from a fixed concept vocabulary. Finally, the embeddings of the scored concepts are pooled into a final sentence representation that can be used for scoring. The concept scoring can be interpreted as a second attention mechanism, where the input sentence is ”reconstructed” in terms of a vocabulary of known concepts. An illustration of this network is depicted below:
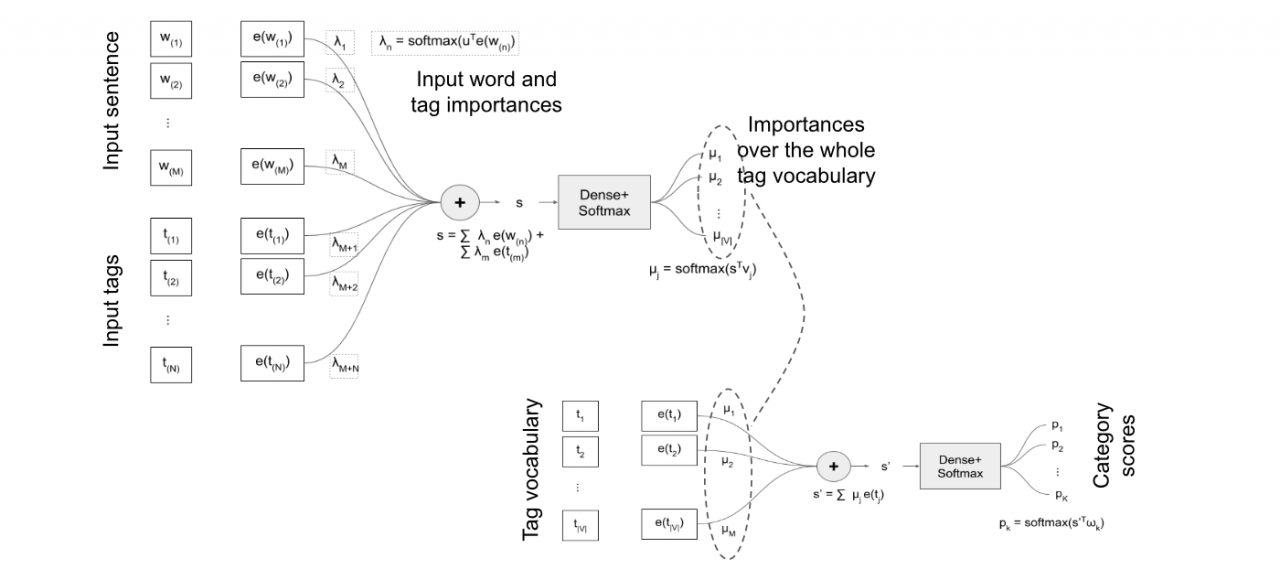
Therefore, with this model we obtain classification, but also interpretability in terms of input words and tags, and induced tags. We have applied this model to a dataset of classifying Stack Overflow questions and to the industrial task of classifying names of shopping establishments in transactional data. A technical report of the internship can be found here.