
Money talks: How AI models help us classify our expenses and income
Improving our financial health is now easier thanks to an update of one of the functionalities offered by the BBVA app: the categorization of financial transactions. These categories allow users to group their transactions to better control their income and expenses, and to understand the overall evolution of their finances.
This service is available to all users in Spain, Mexico, Peru, Colombia, and Argentina. It distinguishes between income and spending groups and offers information on savings, investment, and financing, which facilitates taking measures such as defining budgets. In addition, users can see how much they have earned from different items (payroll, Bizum, transfers, etc.) or what types of expenses have had the most significant impact on their financial situation (leisure, fashion, food, etc.).
A classification model to categorize transactions of other entities
This model categorizes transactions in BBVA accounts and those of other entities that any user (whether a customer or not) can add and manage in the BBVA app. This panoramic view of finances has been possible since the entry into force of the European PSD2 directive1.
PSD2 specifies that the information shared on aggregated transactions from other banks must include at least the originating bank, the type of contract, the amount, and a text field describing the transaction. This regulation enabled the categorization of financial transactions from other entities.
For this purpose, a model was developed that processes the textual description of the transaction to assign the most appropriate category from among all those defined in BBVA. The result is homogeneous regardless of the entity of origin.
The model was built as a multi-class classifier following a supervised approach2, which required labeled examples.
New taxonomy: Adapting the model to changing times
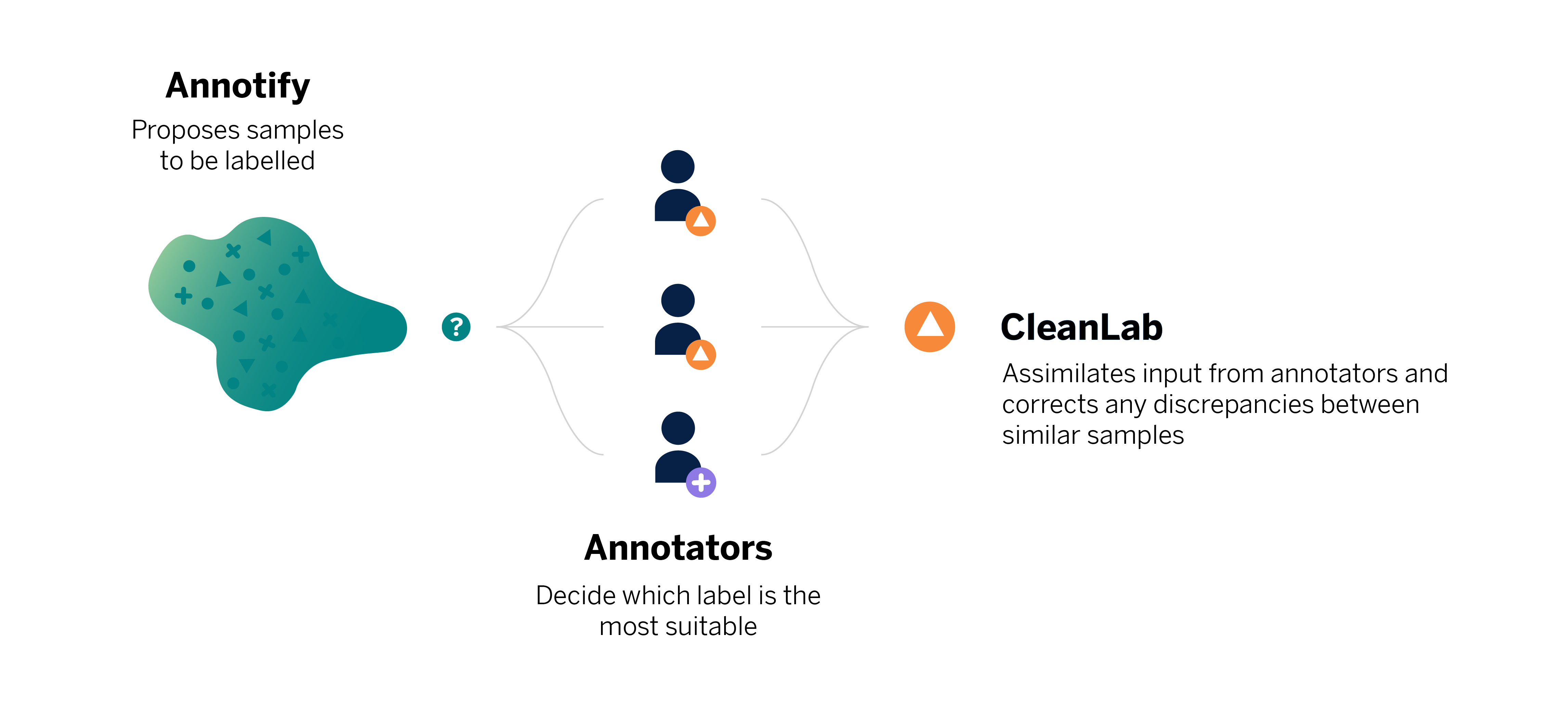
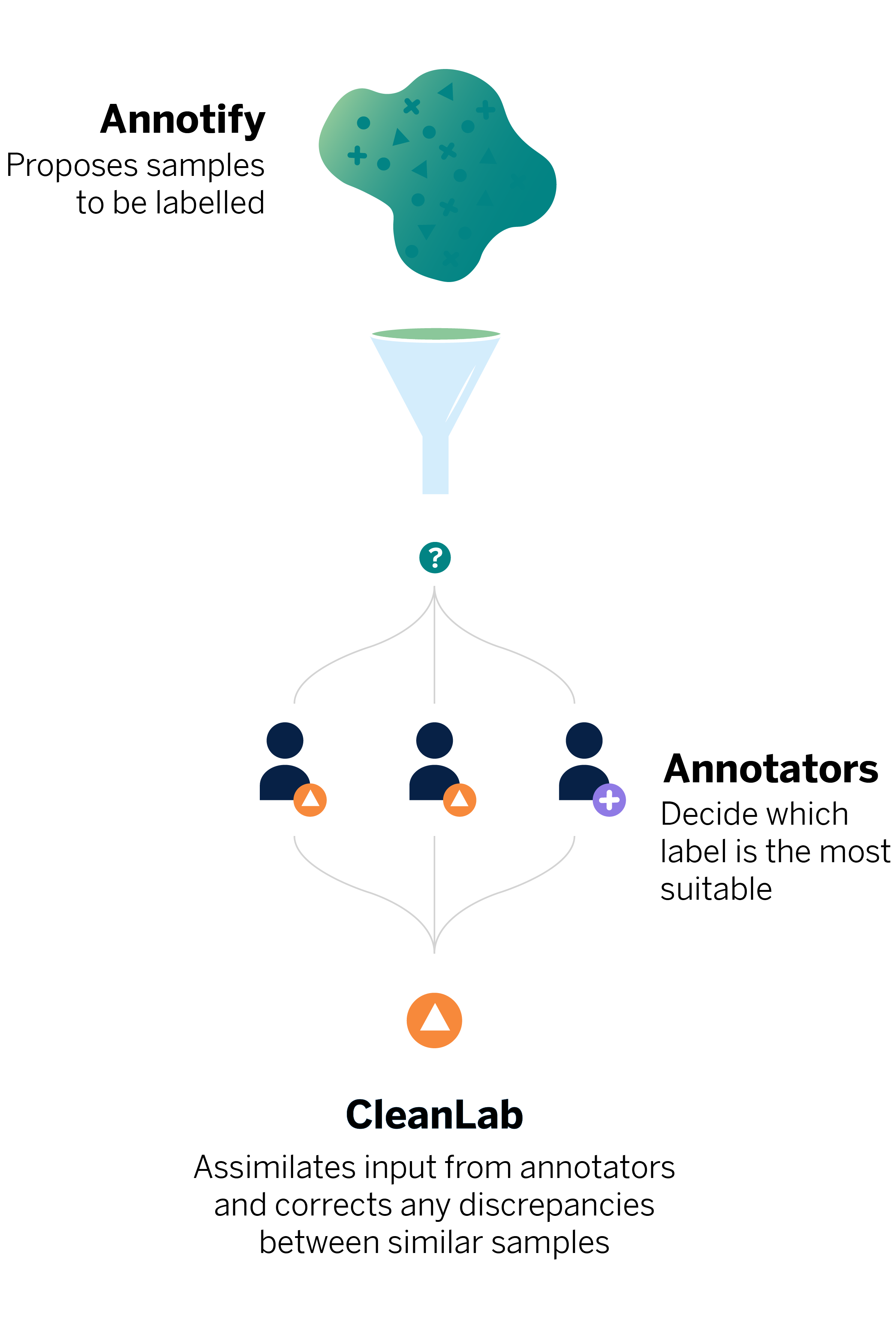
In November 2022 we introduced a new version of our Taxonomy of expenses and income. This enables our clients to gain a better understanding of their financial health and take action to improve it. The change involved updating the model used to classify financial transactions, which was accomplished with the help of Annotify, a tool developed at BBVA AI Factory that allows for the efficient tagging of large datasets.
With the new taxonomy, our clients can gain a more comprehensive view of their finances, including information on new means of payment, investments, or subscriptions. The service provides detailed insights into the types of expenses, income, and investments, grouped into categories and subcategories. Moreover, in line with BBVA’s sustainability commitment, clients can access detailed information on their carbon footprint and take steps to reduce it. For example, the service provides details on the costs associated with private vehicles (taxes, fuel, parking, etc.) and public transport.
The service also identifies monetary transactions associated with other payment methods and investments, such as Bizum payments, PayPal, or cryptocurrency transactions. Clients can also track spending on digital services and subscriptions, such as Netflix or Spotify.
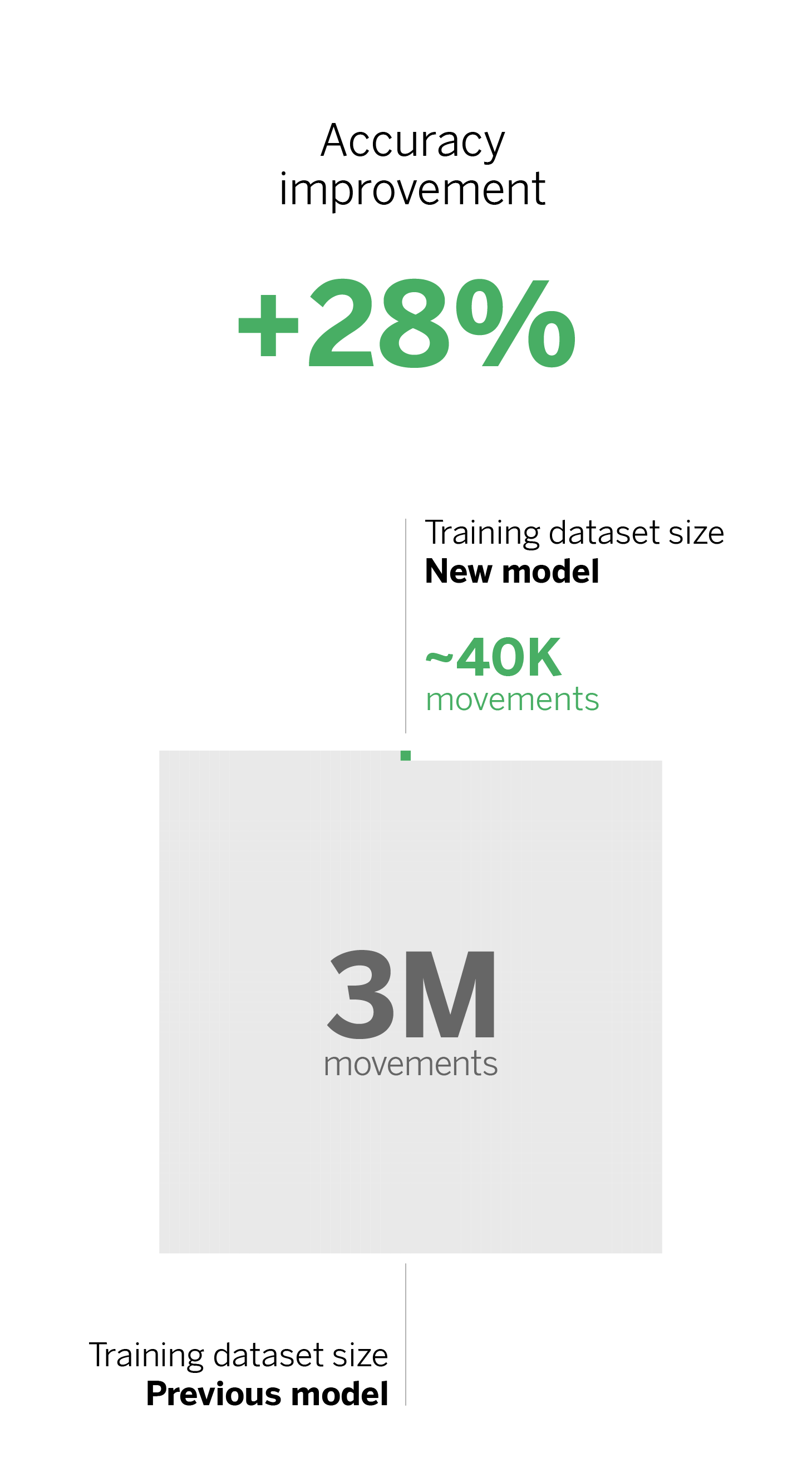
Overall, the new taxonomy has significantly improved the metrics compared to the previous version. We have enhanced both the calculated accuracy and the weighted accuracy, as well as the “macro accuracy”. Additionally, we have reduced the number of transactions used to train the model, from three million to about forty thousand.

The challenge: how did we achieve it?
The new taxonomy has a twofold objective. Firstly, the update aims to improve the model’s results so that our clients have a complete view of their financial transactions and can make better decisions. Secondly, it was used to improve the process of developing the classification model (Machine Learning) for transactions made in other financial institutions, reducing the efforts needed to label data.
The previous model’s development involved labeling three million transactions using different strategies, including manual labeling of sampled data and automatic labeling rules based on similarity to other bank transaction labels. To create the current model, we started with the most recent set of transactions and translated them to the new taxonomy 2.0. We reduced the number of tags from three million to one million, but encountered two drawbacks:
- The data was of a certain age, so some types of expenses, investments, and businesses were not reflected in the dataset.
- The distribution of transactions by subcategories did not represent reality due to the way the first data was labeled. Therefore, we found it necessary to re-label the data.
The Annotify tool played a key role in improving the process, as it allowed us to select the samples used for model training more effectively.
Streamlining and decreasing data labeling
Annotify is a library that uses Active Learning (AL), a specific case of Machine Learning. In AL, a learning algorithm queries a user (or some other source of information) when labeling new data samples. With these techniques, we can reduce the total amount of labeled data needed to obtain good model performance. This is achieved by proposing more valuable samples to be labeled, rather than randomly selecting samples.
We used AL to select financial transactions useful for the model from a dataset of one million records. We selected thirty thousand records from this dataset, which were already representative for the model. Including more transactions did not substantially improve the model’s performance.
However, the model’s performance did not meet our expectations even with this smaller dataset. To improve it, we reused AL by selecting transactions from the last year, as they were the most confusing for the first model. We followed the following workflow:
- Train the model with the labeled dataset we already had;
- Use AL to select new transactions to be labeled;
- Tag the transactions and add them to the labeled dataset;
- We repeated this cycle until we obtained metrics that satisfied us, considering the balance between development cost and improvement obtained in each iteration.


Reducing label noise
We used AL in combination with Cleanlab, an open-source library that detects noise in a dataset’s labels. This was necessary because, although we had defined and unified annotation criteria for transactions, some could be linked to several subcategories depending on the annotator’s interpretation. To reduce the impact of having different subcategories for similar transactions, we used Cleanlab for discrepancy detection. Finally, we obtained a dataset of about forty thousand labeled transactions in total.
Overall, the categorizer provides a more homogeneous experience for customers, regardless of whether transactions occur at BBVA or are aggregated from other entities. It also illustrates the benefits of applying state-of-the-art AL and noisy tag detection techniques in an industrial use case.
Conclusions
Projects related to Machine Learning involve implementing tools already established in the industry, but we also have the possibility to experiment with innovative tools that make the work easier and more efficient. In this particular case, the use of Active Learning techniques included in Annotify helped us select which data to tag, and CleanLab helped us reduce the uncertainty of noise in the tags.
This process enabled us to train the model, update the training set, and optimize its performance. The goal was to reduce the number of labeled transactions and make the model more efficient, requiring less time and dedication. This allows data scientists to focus on tasks that generate greater value for customers and organizations.
Notes
- Since September 2018, PSD2 regulates and harmonizes account information services. This consists of the collection and storage of information from a customer’s various bank accounts in one place, all with their prior authorization. ↩︎
- Specifically, the Multilayer Perceptron model. Previously, it is necessary to use the statistical method Term Frequency – Inverse Document Frequency to convert the text to number vectors and pass them as input to the model. ↩︎
- This article has been written by David Muelas Recuenco, María Ruiz Teixidor (BBVA), Leandro Hidalgo Torres (Huxley – Sthree Consulting) and Aarón Rubio Fernández (BBVA Next Technologies).