
Mercury-Robust: ensuring the reliability of our ML models
The importance of ensuring the robustness of machine learning models and accurately monitoring them once they are deployed in production environments is becoming increasingly evident. Therefore, it is highly recommended to incorporate analytical elements that can help us evaluate our models and measure their performance and reliability.
The demand for such caution is proportional to the maturity of companies in developing machine learning-based solutions, as well as to the potential impact these solutions could have on people’s lives. At BBVA AI Factory, we create solutions integrated into the bank’s production environments and then implement them in actual use cases. Consequently, we must exercise rigor and caution to prevent any circumstances affecting model performance.
Since our models operate in real life, it is not enough to develop them as in academia, where environments are controlled and data is not realistic. In real-world scenarios, these models must be prepared for contingencies. This explains the increasing interest in implementing techniques that measure and optimize the performance of machine learning models, along with the use of many MLOps tools available on the market.
What is Machine Learning Operations (MLOps)?
MLOps is a set of practices and tools used to manage and automate the lifecycle of machine learning models, from their training phase to their entry into production. It focuses on improving models’ efficiency, scalability, and reliability in production environments to ensure they align with business objectives and facilitate their integration with other systems.
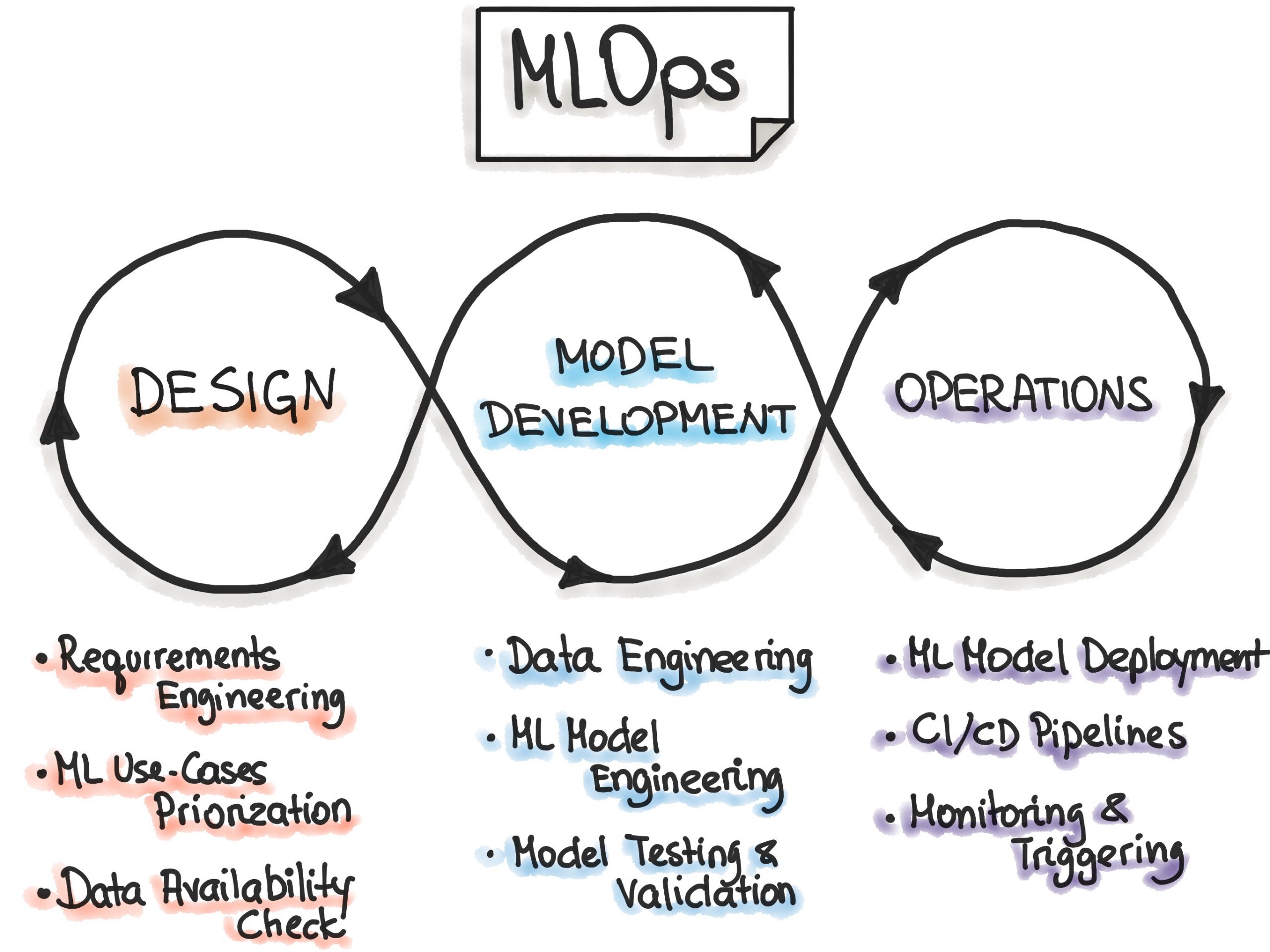
Although often associated with a methodological practice, the term MLOps is used to name the tools that support the machine learning model’s development infrastructure. This is a prominent area today and is considered critical to deriving business value from data-driven products and ensuring their proper operation.
Commercially, multiple MLOps solutions are created by data platforms and Cloud service providers, such as AWS’s SageMaker MLOps, Google Cloud Platform’s VertexAI, and Azure Machine Learning.
While MLOps comprises other elements, monitoring and robustness are essential aspects of this tool suite. On one hand, monitoring refers to the ability to supervise model performance in real time and quickly detect any problems that may arise, such as drift (changes in distribution) in the input data.
On the other hand, robustness refers to the ability of machine learning models to maintain high-performance levels even under adverse or unexpected conditions. For example, a robust machine learning model should be able to handle new data even when it differs from the data used during training.
Mercury-robust: A framework for testing the robustness of ML models at BBVA
In an industrial environment, ensuring that a trained machine learning model behaves correctly in the real world when deployed is crucial. To this end, it must be resilient to adverse situations and environmental changes. Additionally, it is essential to ensure that future updates to the model do not introduce potential points of failure in the system, which could compromise its reliability and performance.
Mercury-robust was created as a framework within BBVA’s data science library, Mercury, to address these issues. Its purpose is to perform tests on models or datasets, and it takes inspiration from traditional software unit tests.
Whenever a test fails, it raises an exception that must be handled at the user’s discretion. The library also provides several predefined and configurable test cases, which help ensure the robustness of machine learning pipelines. For instance, you can quickly verify whether a model discriminates against a group or check if re-training the model with the same data yields the exact predictions.
Mercury-robust has proven to be a valuable analytical component in our day-to-day work. Its potential as open-source software is excellent, so we have made it available to everyone. By doing so, we aim to make it easier for others to use, eventually leading to its functionalities’ growth.
At a high level, mercury-robust is divided into two types of components: Model Test and Data Test, depending on whether they involve a model or just the data.
Data Test
| Same Schema → |  |
Ensures that a DataFrame has the same columns and feature types as those specified in the DataSchema. |
| Data Drift → |  |
Verifies that the individual feature distributions have not significantly changed between a reference DataSchema and a pandas.DataFrame. |
| Linear Combinations → |  |
Checks that your pandas.DataFrame does not have redundant or unnecessary columns. |
| No Duplicates → |  |
Corroborates that you do not have repeated samples in your dataset, which can add bias to your performance metrics. |
| Sample Leaking → |  |
Checks if the test or validation dataset contains samples that are already included in the training dataset. |
| Label Leaking → |  |
Ensures that your data has no feature that leaks information about the target variable. |
| Noisy Labels → |  |
Examines the labels of your dataset to guarantee they have a minimum quality. We consider labels low-quality when there are many incorrectly labeled samples or when the separation between labels is not evident. |
| Cohort Performance → |  |
Checks whether a specified metric is worse for a particular group of your data. For example, it can be configured to check if the accuracy of a model is lower in one gender than the other. |
Data Test
Same Schema →
Ensures that a DataFrame has the same columns and feature types as those specified in the DataSchema.
Data Drift →
Verifies that the individual feature distributions have not significantly changed between a reference DataSchema and a pandas.DataFrame.
Linear Combinations →
Checks that your pandas.DataFrame does not have redundant or unnecessary columns.
No Duplicates →
Corroborates that you do not have repeated samples in your dataset, which can add bias to your performance metrics.
Sample Leaking →
Checks if the test or validation dataset contains samples that are already included in the training dataset.
Label Leaking →
Ensures that your data has no feature that leaks information about the target variable.
Noisy Labels →
Examines the labels of your dataset to guarantee they have a minimum quality. We consider labels low-quality when there are many incorrectly labeled samples or when the separation between labels is not evident.
Cohort Performance →
Checks whether a specified metric is worse for a particular group of your data. For example, it can be configured to check if the accuracy of a model is lower in one gender than the other.
Model Test
| Model Reproducibility → |  |
Trains a model twice and checks that the two versions’ predictions (or a particular metric) are not too different. |
| Feature Checker → |  |
Estimates the importance of the features and retrains your model by eliminating the less important ones one by one. |
| Tree Coverage → |  |
Works only with tree-based models (mainly those of scikit-learn). It checks that, given a test dataset and a trained model, the samples “activate” a minimum amount of branches in their tree(s). |
| Model Simplicity → |  |
Compares your model’s performance to a more straightforward baseline (by default, a linear model, although you can specify your custom baseline). |
| Classification Invariance → |  |
Verifies that the model’s prediction remains unchanged when a perturbation is applied that should not impact the label of the samples. |
| Drift Resistance → |  |
Checks the resistance of a model to drift in the data. |
Model Test
Model Reproducibility →
Trains a model twice and checks that the two versions’ predictions (or a particular metric) are not too different.
Feature Checker →
Estimates the importance of the features and retrains your model by eliminating the less important ones one by one.
Tree Coverage →
Works only with tree-based models (mainly those of scikit-learn). It checks that, given a test dataset and a trained model, the samples “activate” a minimum amount of branches in their tree(s).
Model Simplicity →
Compares your model’s performance to a more straightforward baseline (by default, a linear model, although you can specify your custom baseline).
Classification Invariance →
Verifies that the model’s prediction remains unchanged when a perturbation is applied that should not impact the label of the samples.
Drift Resistance →
Checks the resistance of a model to drift in the data.
Hands-on!
To begin using the mercury-robust framework, visit the documentation and the repository we have opened on GitHub. From there, you can install the package from Pypi.
pip install mercury-robustWe can generally use this framework in two steps:
- Create the tests you want to execute.
- Create a test suite with these tests and run it.
Below, we can see an example:
from mercury.robust.data_tests import LinearCombinationsTest, LabelLeakingTest
from mercury.robust import TestSuite
# Create tests
linear_combinations = LinearCombinationsTest(df[features], dataset_schema=schema)
label_leaking = LabelLeakingTest(
df,
label_name = label,
dataset_schema=schema,
)
# Create Test Suite
test_suite = TestSuite(tests=[linear_combinations, label_leaking])
test_results = test_suite.run()
test_suite.get_results_as_df()Outcome:
| name | state | error | |
| 0 | LinearCombinationsTest | TestStateSUCCESS | |
| 1 | LabelLeakingTest | TestState.FAIL | Test failed because high importance features were detected: [‘WARNING_SENT’]. Check for possible target leaking. |
| name | state | error | |
| 0 | LinearCombinationsTest | TestStateSUCCESS | |
| 1 | LabelLeakingTest | TestState.FAIL | Test failed because high importance features were detected: [‘WARNING_SENT’]. Check for possible target leaking. |
After running the test suite, we can quickly identify which tests have failed and why. In this particular case, one of the tests failed because our dataset contains a variable that may cause “leakage” concerning the target.
Conclusions
In summary, this framework provides tools to ensure a high-quality standard for models and facilitate their internal audit. Thanks to its functionalities, biases have been detected in performance metrics by subgroups of sensitive variables, data drift has been prevented, and errors in the labels assigned by experts, which are subsequently used for ML models, have been detected.