
Mercury: Scaling Data Science reusability at BBVA
The development of AI-based products requires a significant amount of time dedicated to designing, implementing, and testing algorithms on data. In a corporation as large as BBVA, which employs over 700 data scientists, it is not uncommon for multiple teams to independently create similar software solutions. Oftentimes, even though the applications may vary, a number of the elements or assets employed are similar, resulting in redundant efforts and a consequent waste of time and resources.
From BBVA AI Factory, we are contributing to solving this problem with Mercury, an internal code library with which we seek to apply the principles of Open Source within BBVA. In addition to our primary objective of streamlining the use of code components and speeding up project development, the innersource approach1 also brings various other benefits.
On the one hand, we achieve a strong community culture by facilitating the sharing of ideas and knowledge. The fact of working as a community fosters professional growth, by contributing components that will have a greater impact, while also allowing us to stay informed of the solutions that other teams are developing. Furthermore, code quality is greatly enhanced as more people can review, comment, document and improve it. As the Linus’s Law states: “given enough eyeballs, all bugs are shallow”2. Additionally, the availability of code components allows teams to explore a wider range of use cases and find solutions to various business challenges.
The birth of Mercury
Mercury was conceived to serve as a powerful tool for contributing and utilizing code components among teams and developers. To achieve this, we developed a Python library, named Mercury, which includes commonly used algorithms for multiple teams, as well as those that have the potential for future reuse.
To maximize its usefulness and streamline project development, Mercury was established as a voluntary and open library for the entire AI Factory community, meaning anyone can view, modify, and submit changes that they believe would be beneficial to others.
Another key requirement is that Mercury should not replicate functionality already provided by popular libraries. The components included in Mercury are unique or offer distinct advantages over existing options. Additionally, while they are general-purpose and not tied to specific business cases, they must be fully functional and have high code quality.
Finally, we employed strategies such as tutorials and thorough documentation to make it easy for users to discover and adopt the features provided by Mercury.
The initial version of Mercury, which had limited features, quickly gained traction in the AI Factory. Data scientists started to reuse components within their projects and contribute new ideas, fostering a sense of community that continues to this day.
Growth throughout BBVA
After two years of successful growth within the AI Factory, we decided to expand access to Mercury to the entire BBVA Advanced Analytics community, in order to replicate this success on a larger scale, across a wider range of countries and business areas. This includes countries such as Mexico, Peru, Argentina, Colombia, and areas such as Finance, Talent & Culture, and Corporate & Investment Banking, among others. This has led to an increasing number of data scientists using and contributing to Mercury, from a wide range of fields.
Following the implementation of the library within BBVA, new opportunities for collaboration and integration with other programs and development lines emerged. For example, components developed through the X-Program, a data experimentation and innovation initiative, have been made available to the Mercury community and are now being reused in different programs.
About Mercury library
Currently, the library has grown into a substantial project (+300K lines of code) with a wide range of functionalities from various domains. To manage this complexity, it was designed to be modular from the outset, enabling users to install only the specific parts of the library they require. Mercury is divided into several micro-packages, which can be used independently
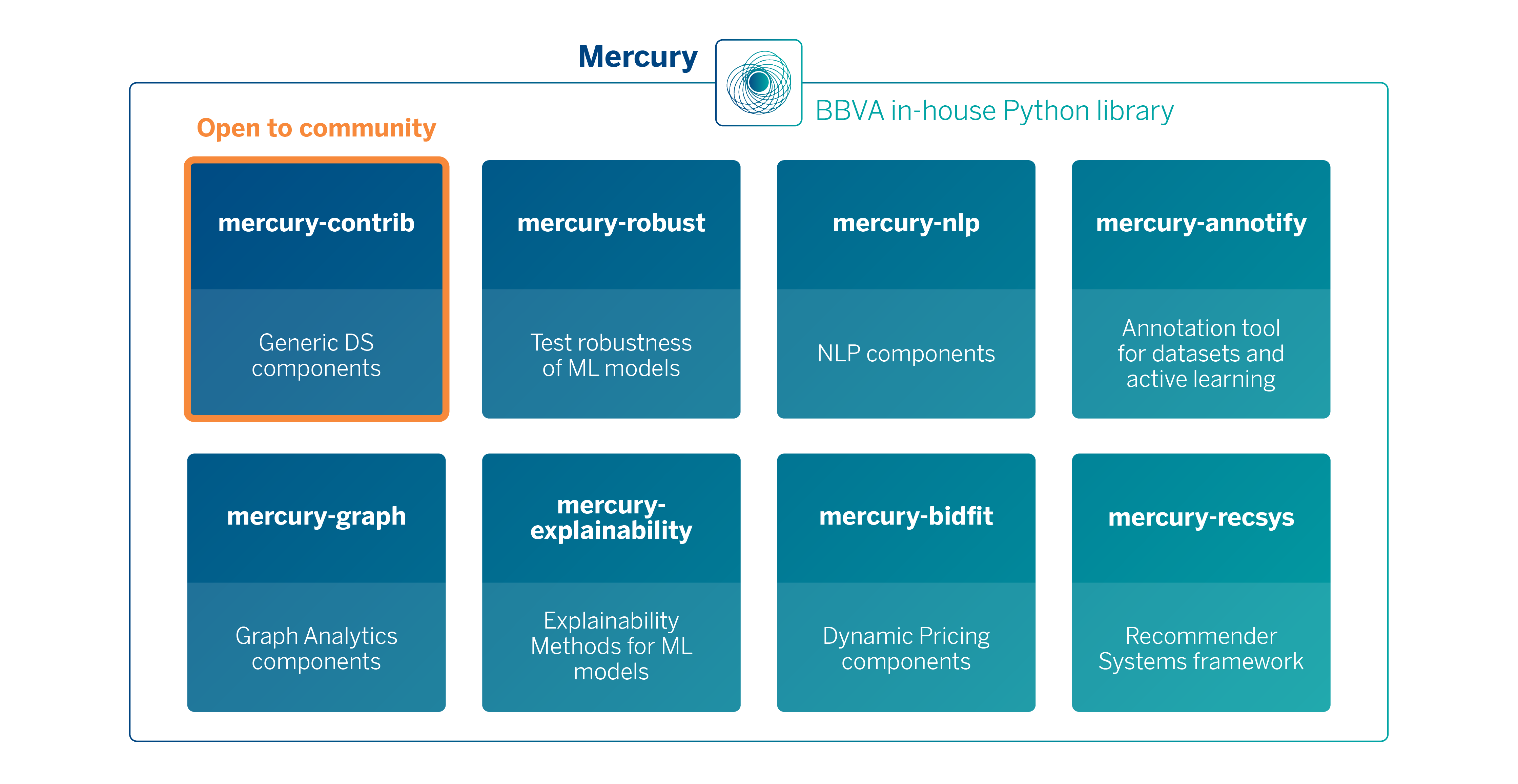
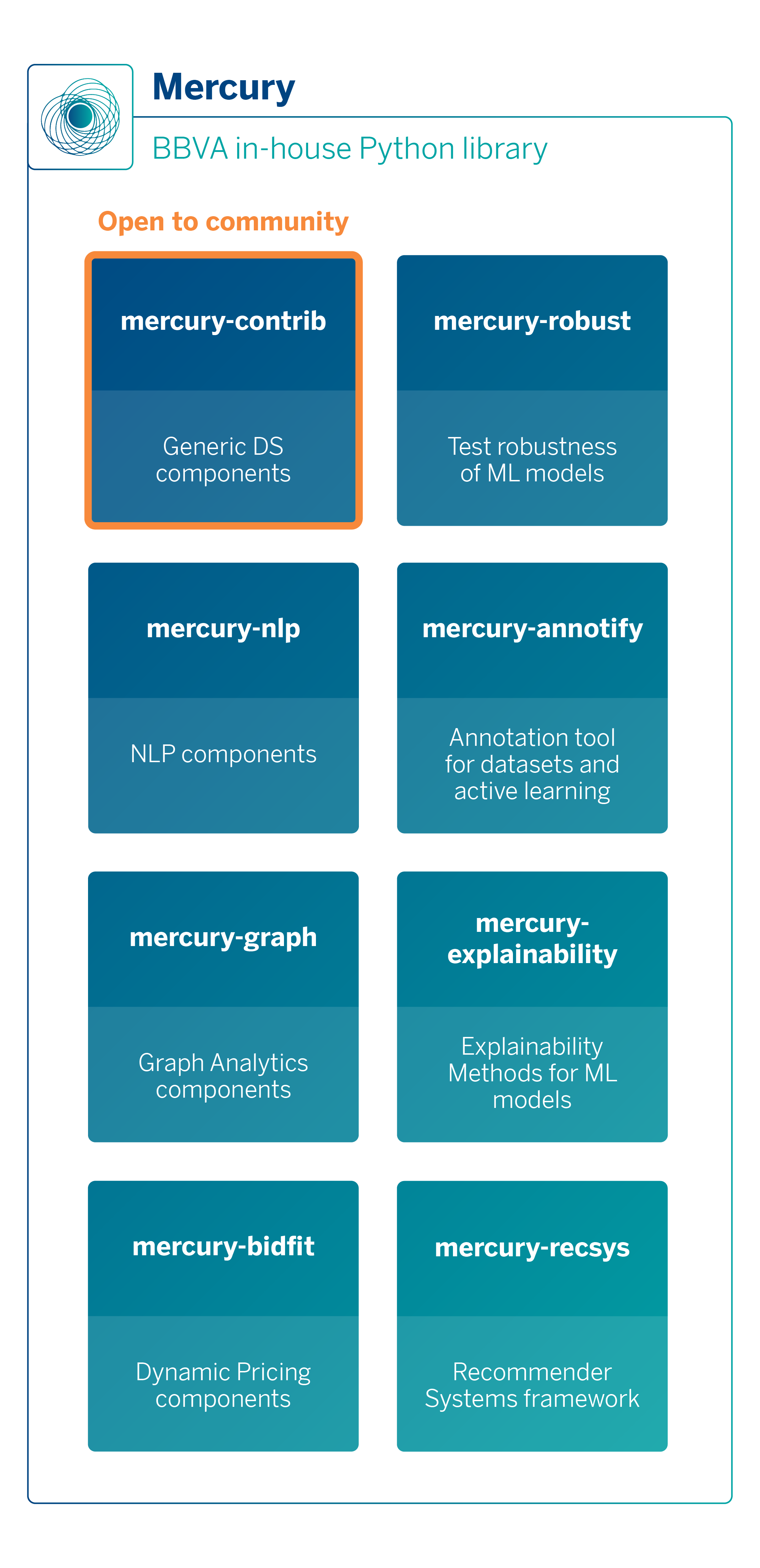
Some examples of pieces that can be found in each of the Mercury packages include: an implementation of Extended Trees (mercury-contrib), algorithms for calculating embeddings in large-scale graphs (mercury-graph3), methods for model explainability (mercury-explainability), advanced hyperparameter optimization algorithms (mercury-contrib), drift detection algorithms (mercury-contrib), a framework for robust testing of ML models (mercury-robust) to assure models and data quality, or a framework for dynamic pricing based on Reinforcement Learning (mercury-bidfit).
Each of the micro-packages has an independent lifecycle, with its own set of tests, continuous integration (CI), and artifact.
Given that these components are used in production processes that affect various business areas, it is crucial to maintain high quality standards similar to those of major Machine Learning libraries (scikit-learn, Tensorflow, PyTorch, etc.). This includes high test coverage (~90%) and integration tests to ensure the library will function properly on the bank’s internal data platform. Mercury has a dedicated team responsible for its development and maintenance, composed of data scientists and ML engineers.
By adhering to this lifecycle, we aim to maintain a fast release schedule. A full library release is generated each month, enabling users to quickly access the latest updates and continue to rely on Mercury for their developments.
Some lessons learned
One of the keys to the success of this type of projects inspired by the ideas of Open Source is to create, grow and maintain a community that uses and contributes to the project. To accomplish this, it is essential to establish a clear organizational structure. In the case of Mercury, this includes three types of roles, with varying degrees of responsibility over the project:
 Core Team Core Team |
 Contributors Contributors |
 Community Community |
|---|
|
|
|
|
|---|---|---|---|
| Core Team | Contributors | Community | |
| Use the library |  |
|
|
| Dissemination | |
|
|
| Contribute ideas or algorithms | |
|
|
| Improve tutorials or documentation | |
|
|
| Manage contributions | |
||
| Maintenance | |
Adopting a new library can be challenging for users, which is why effective communication and dissemination are crucial to promote its usage and overcome any potential resistance. In order to achieve this, the Mercury project places a strong emphasis on various communication efforts, such as newsletters, chat channels, workshops, hackathons, and meetups.
The primary means of learning a software library is through its documentation and usage examples. It is critical that we provide comprehensive documentation and usage tutorials for each component that is added. We currently have over 200 tutorials in the form of notebooks, which are included in our release cycles. Additionally, we generate documentation pages that are similar to those found in popular libraries like Tensorflow, Keras, or Scikit-Learn on a regular basis.
Given the scale of BBVA, having an effective governance and review system enables us to ensure that both potential and regular contributors can add their components to the library.
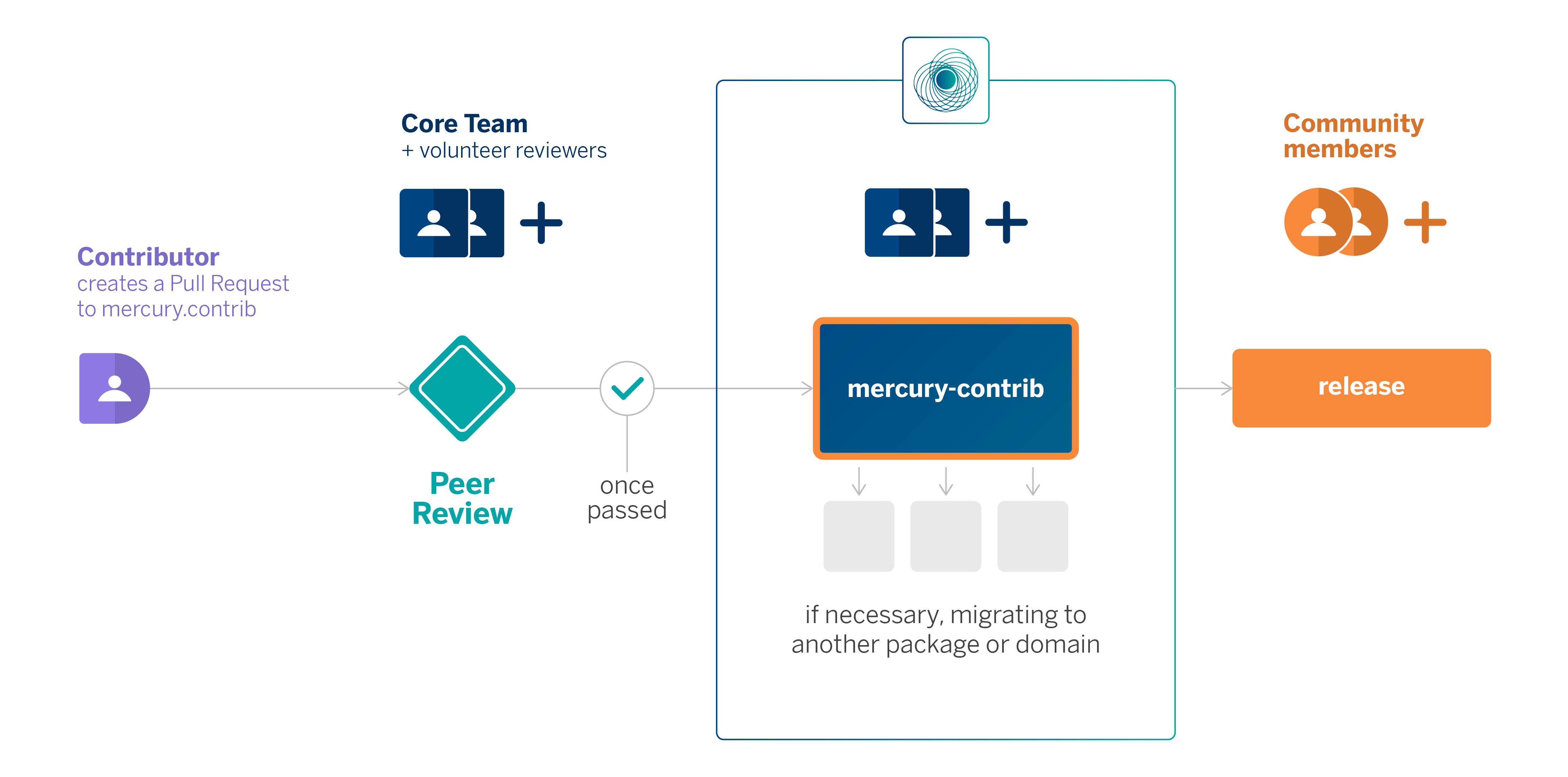
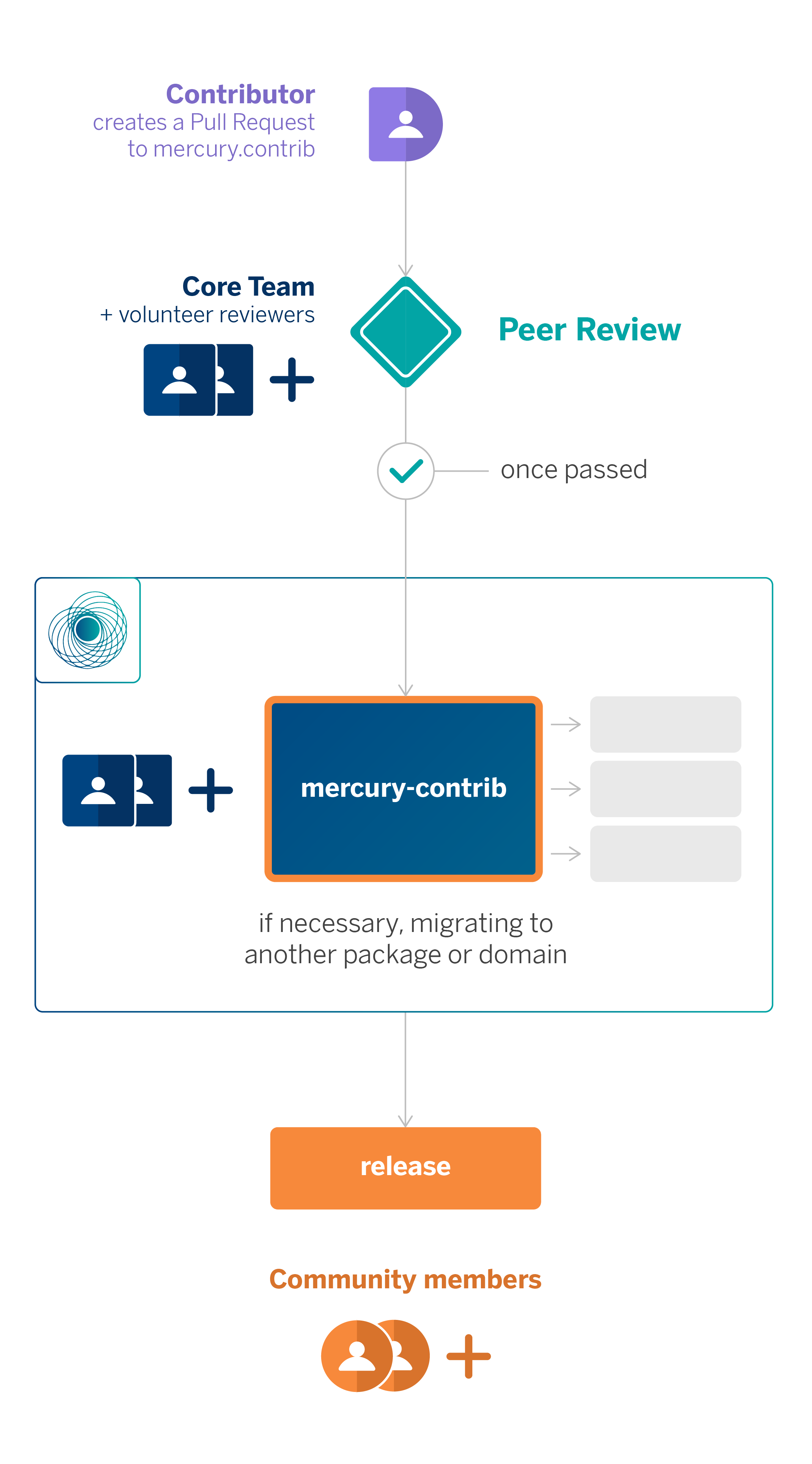
As previously mentioned, the contribution process is fully open to anyone. It typically begins by opening a Pull Request (PR) in the mercury.contrib repository, the central point of contribution in Mercury. This triggers a review process in which the maintenance team and, if desired, other volunteers, review and provide feedback with the aim of enhancing the code being contributed. Once a minimum of two approvals is obtained, the contribution can be automatically included in the mercury.contrib.
Furthermore, if the contribution aligns better with a specific domain (e.g. if it pertains to graph processing, it would be more appropriate to be located within mercury.graph), the Mercury team will relocate it into the package that most appropriately fits it.
Shortening time-to-value and accelerating new projects
Mercury serves as a model for the implementation of InnerSource at BBVA. Externally, InnerSource Commons is the largest community of InnerSource practitioners worldwide, featuring success stories from various companies across different industries, each with its unique characteristics. When examining our own story, one of the most distinctive factors is the set of KPIs we utilize.
In InnerSource projects, it is typical to track code activity in the associated repositories, such as the volume of Pull Requests, commits, contributors, etc. These metrics can be easily obtained through version control services like Bitbucket or Github, among others. However, in the case of Mercury, we prioritize usage. This means that what matters most to us is measuring how many users are installing and utilizing the library in real use cases, even if they do not contribute new code. The metric that drives us is an import mercury.* and not so much a git commit / push.
By shifting our focus to usage, the implementation of a cross-domain Data Science library like Mercury helps to reduce time-to-value, speed up the development of new projects, improve maintenance efficiency and promote knowledge sharing.
Today, the Mercury user community is thriving. It is utilized in over a third of the bank’s most significant advanced analytics use cases and this number is expected to double by 2023. These use cases include detecting new patterns of money laundering using mercury-graph components, building recommendation systems with mercury-recsys, or accelerating the labeling process that enables customers to view new spending categories in the BBVA app, using mercury-annotify. There is no doubt that the library has a bright future ahead.
References
- An introduction to innersource – GitHub Resources. ↩︎
- Linu’s Law. ↩︎
- An AI Factory team releases internal software to analyze relations, basis of Mercury’s current mercury-graph package. ↩︎