
Large Language Models beyond dialogue
The most searched term on Google in Spain during 2023 was “ChatGPT.” Its sudden appearance has represented a paradigm shift in how we interact with technology, allowing us to communicate with machines in natural language.
These conversational assistants can provide insights and relevant knowledge (although we must always verify the accuracy of their output). One of their key virtues is their ability to understand the context of the conversation and adapt to our instructions. All of this is possible thanks to Large Language Models (LLM), a branch of artificial intelligence that operates within deep learning.
However, these Large Language Models have other applications beyond chat. At BBVA AI Factory, our exploratory work with them has revealed new applications that can benefit several fields, among them data science. This article presents some of the challenges that these models help us overcome.
What is a Large Language Model?
Imagine a librarian who has never had contact with the outside world but has gained knowledge from various sources within a library that contains all the knowledge generated by humankind. He has learned the language patterns, grammar, and context necessary to engage in conversation effectively.
Like this hermit librarian, Large Language Models have been trained with all the information necessary to simulate human interaction. The main difference is that despite his isolation, the librarian is human and can articulate his responses through his reasoning.
LLMs, conversely, predict the text they generate from what is most likely to be coherent regarding what we asked and can synthesize information from multiple sources to give a cohesive and relevant answer.
In addition to generating language, we can train and use Large Language Models to perform various tasks.
Different Large Language Models applications
Reducing time spent on data labeling
One of our jobs as data scientists is to train machine learning models. This work requires careful preparation of the training data. When we face supervised classification problems, we need to label the data. These labels classify the information and ultimately allow the model to make decisions.
The quality and consistency of labels are fundamental to model development. Traditionally, labeling has been a manual task where human annotators identify which data belongs to one category or another. This tedious task can be affected by the subjective factor it involves, so the consistency of the labeling can be compromised, especially when the data being labeled is unstructured.
There are several ways to streamline this task. One novel way is to use Large Language Models, which can automatically recognize and label specific categories in large text sets. Because these models have been trained on a large corpus of text data, they can understand the complexity of such texts, contextualize them as a human would, and even reduce human error.
When using an LLM for automatic annotation, it is essential to write a clear and detailed prompt1 that defines the categories to be annotated, for which we can provide concrete examples and guidelines. For instance, in what context and for what purpose is the data being annotated? This allows the model to generate accurate and consistent labels.
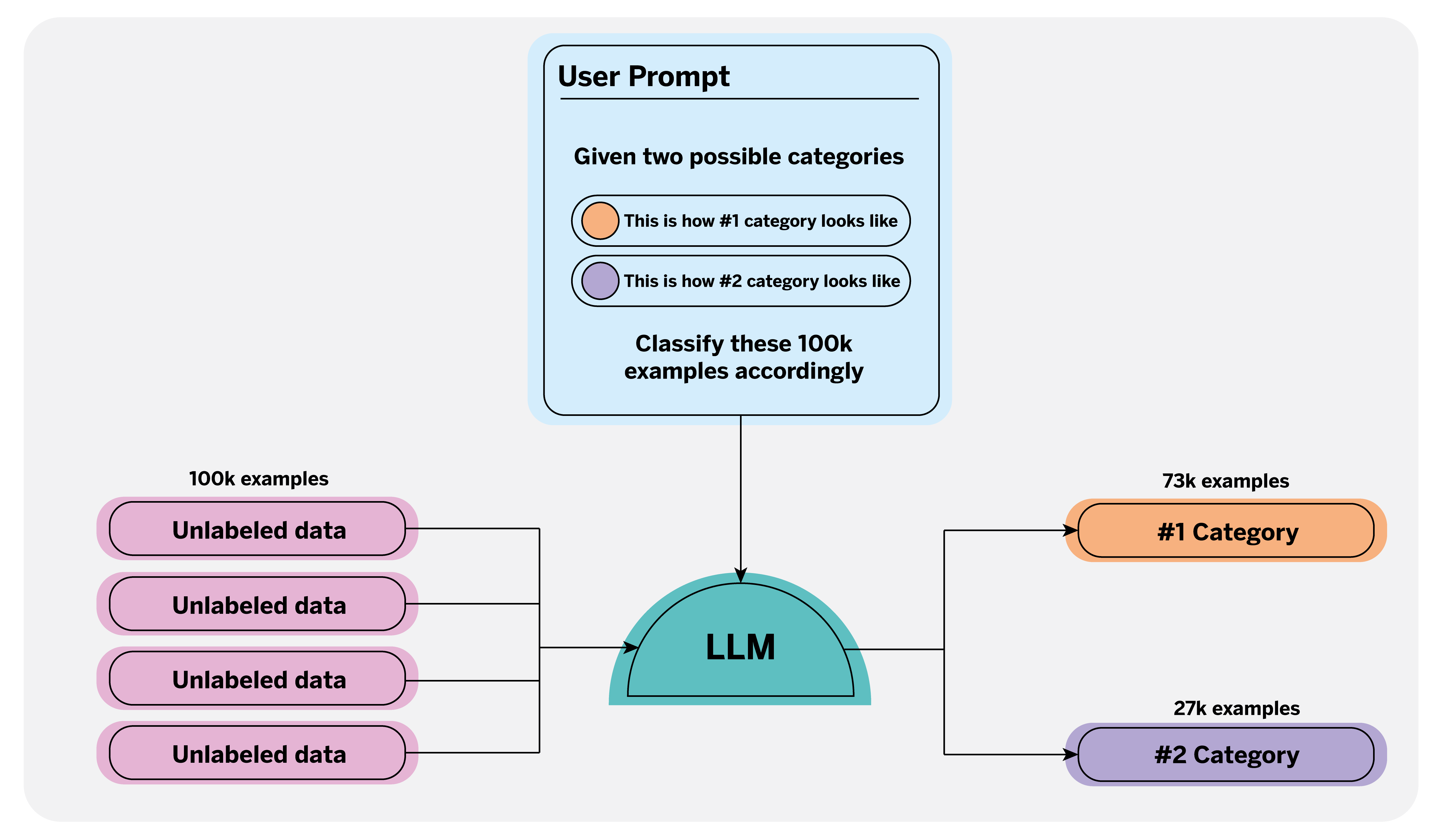
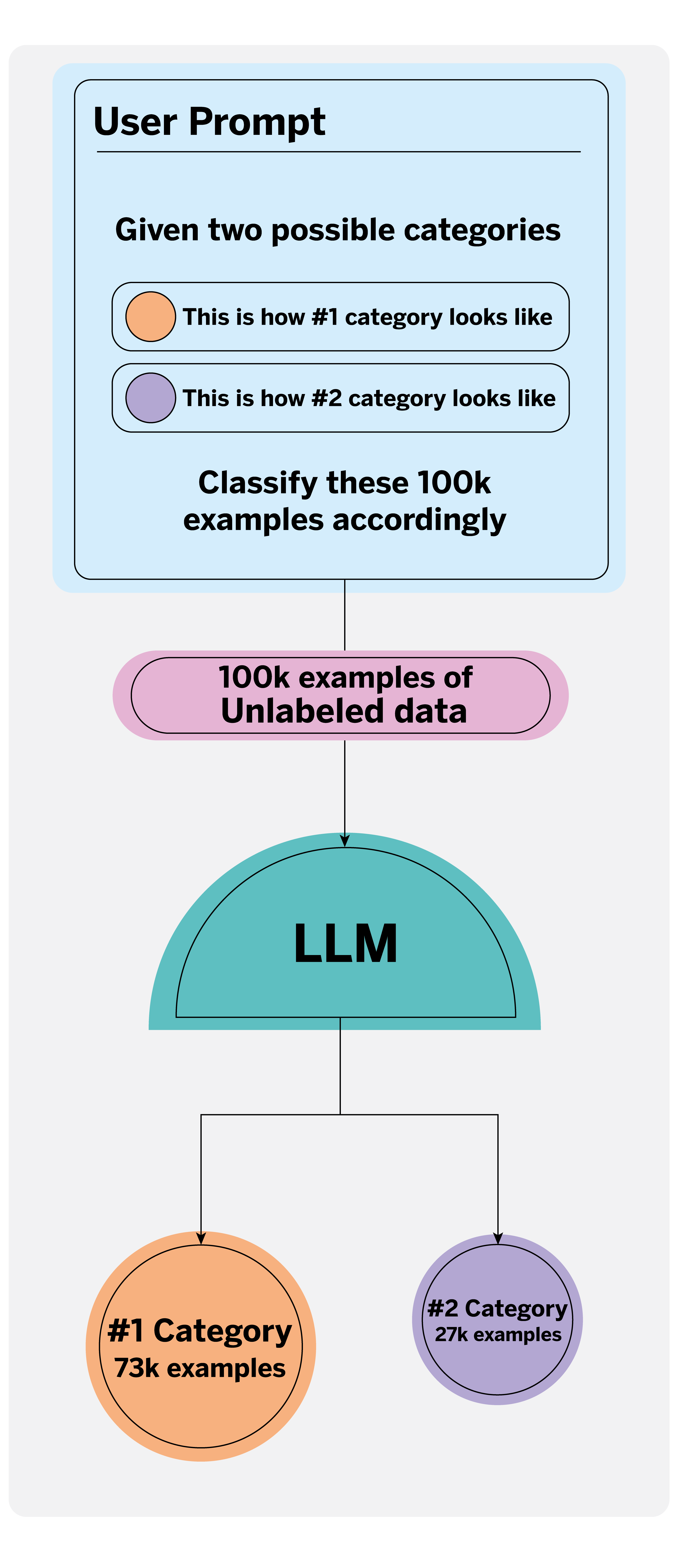
By automating this task, data scientists can spend less time labeling and more time monitoring and correcting any discrepancies in the generated labels, ensuring the quality of the final dataset. This optimizes resources and opens up new possibilities for large-scale data management.
Minimizing effort in evaluation tasks: self-critique
One of the most important phases in the development cycle of an analytical model, in this case a language model, is evaluating its results. This helps us assess and improve its performance in production and even fine-tune the prompts we provide. However, this evaluation is less well-defined than that of more traditional machine learning models, where we have established metrics such as accuracy for classification problems or MSE (Mean Squared Error) for regression.
In generative AI, defining a set of metrics to evaluate aspects such as response relevance, consistency, and completeness is essential. Once defined, scoring each response according to these criteria can become a bottleneck due to the time required and the subjectivity of the evaluation, as different human evaluators may have different criteria. For this reason, the alternative is to use another LLM to score the generated responses.
It has been observed that Large Language Models have a certain “reasoning” or “critical” capacity that can be very helpful in evaluating the text generated by other LLMs or even by themselves, thus facilitating the task of manual evaluation.
Depending on the problem, the evaluation can be oriented differently: Does it answer the question correctly? Is the answer clear and concise? Does it invent content, or is everything generated based on the context provided? Does it contain personal information?
For example, suppose we want to evaluate the performance of an automated response system using a metric that measures whether the response contains invented information or reveals personal information. We could develop an evaluation system (using prompting techniques), manually evaluate a sample of generated responses, and compare our system metrics with those we obtain manually. If the behavior is similar, this could replace the manual evaluation.
This does not mean that this task is eliminated, as it will always be necessary to check how the LLM in question scores, and this will require some human supervision.
Enriching model answers with large knowledge bases
LLMs have an excellent ability to understand and process large amounts of data, whether text, images, or video. This ability allows them to synthesize information and process requests in a conversational format.
The first possibility, and probably the most obvious, is to take advantage of the large context size that some of the current LLMs can handle (the amount of text we can feed them) to enrich our query with all the necessary information. For example, let’s suppose we ask the model a question regarding government regulations. We can get a better answer if we include in the query a document with the details of that specific regulation rather than just relying on the model’s general knowledge.
However, other techniques come into play when we have more information than the model can process or when we do not know exactly which documents can help us answer the question. The two main ones are Retrieval Augmented Generation (RAG) and fine-tuning. RAG retrieves information from documents using a language model. In the case of a query, the first step is to search the database for information relevant to the answer. The LLM then uses this retrieved information to generate an enriched and contextualized answer.
On the other hand, fine-tuning involves specializing a pre-trained LLM for a particular domain or task using a task-relevant dataset.
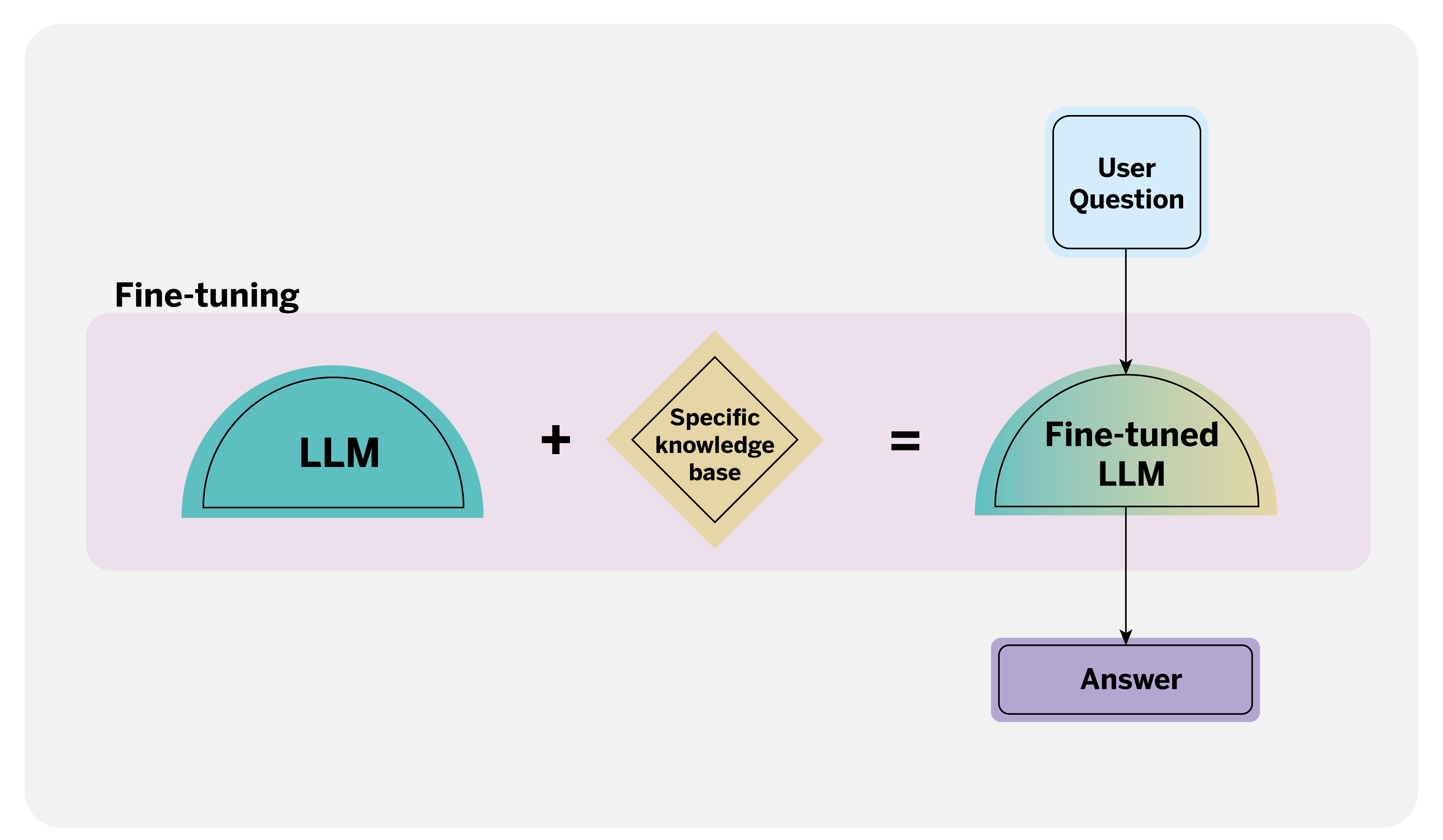
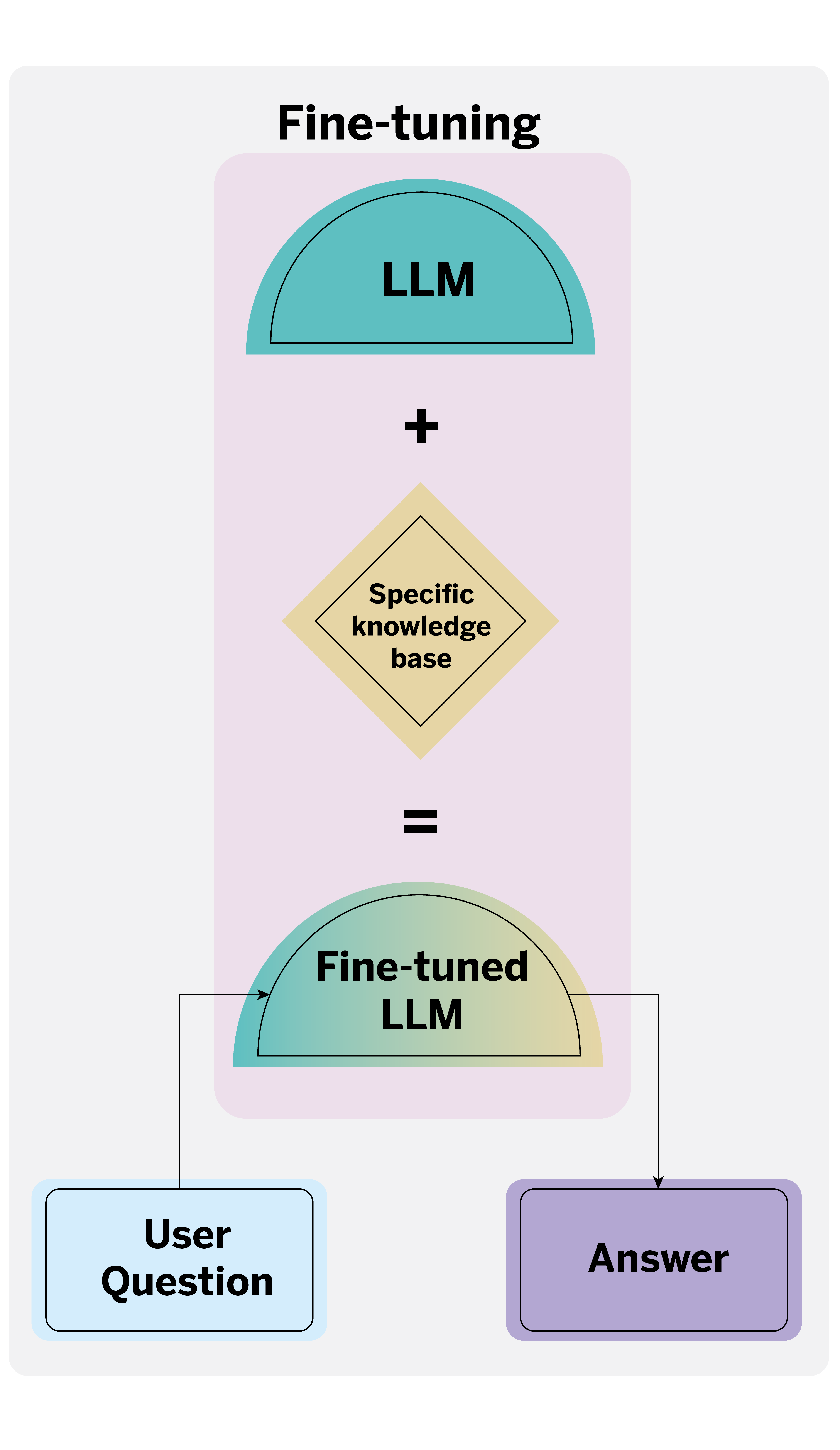
Each technique has its pros and cons. For example, RAG is less prone to generating false positives and produces more interpretable results; it benefits knowledge bases subject to periodic changes or updates. On the other hand, fine-tuning offers lower latency and can provide better results when a rich set of data well suited to the task is available.
Generating synthetic data
Suppose we are working on a multi-class classification problem where we label financial products according to their subject matter: cards, accounts, insurance, mutual funds, investment funds, pension plans, cryptocurrencies, and so on. When training a classifier, it may show some tendency or bias in its predictions towards some categories, possibly because other categories are less represented in the dataset. This can affect the model’s performance.
One solution to this problem is to generate synthetic data. Synthetic data is information artificially created by computational models that mimic the structure and characteristics of actual data but do not come from real-world events. In the context of artificial intelligence, this data can help balance a dataset by providing additional examples in underrepresented categories.
LLM are particularly useful for this task. Using prompting techniques, we provide specific examples of the type of text we want the model to generate to balance our dataset. This process can be implemented using “few-shot learning,” where we show the model a few examples to learn the task, or the “person pattern,” which defines a specific format the generated text must follow.
By generating synthetic data, we can reduce bias in the classifier’s predictions and improve the model’s robustness and generalizability. As a result, the model can handle a wider variety of situations without relying solely on the initially available data. This strategy is precious when data collection is costly, time-consuming, or impractical.
Invoking or performing actions using natural language
LLM-based agents are systems that can perform actions. As data scientists, we can use this new functionality in applications like chatbots. Traditionally, invoking an action in a conversation, such as when interacting with a device like Alexa, requires a specific command. For example, if you wanted to turn on the lights in your living room, you’d have to specify a particular action and the exact name you gave that lamp to Alexa. However, these agents allow LLMs to interpret the user’s intent, even if the command is not explicitly mentioned, and invoke the necessary actions.
These actions must be clearly defined as tools2 so that agents can perform them. Tools are components that extend the functionality of LLM beyond its dialog capabilities. They must contain a detailed description of the action to be performed, the necessary parameters for its execution, and the corresponding code to carry it out.
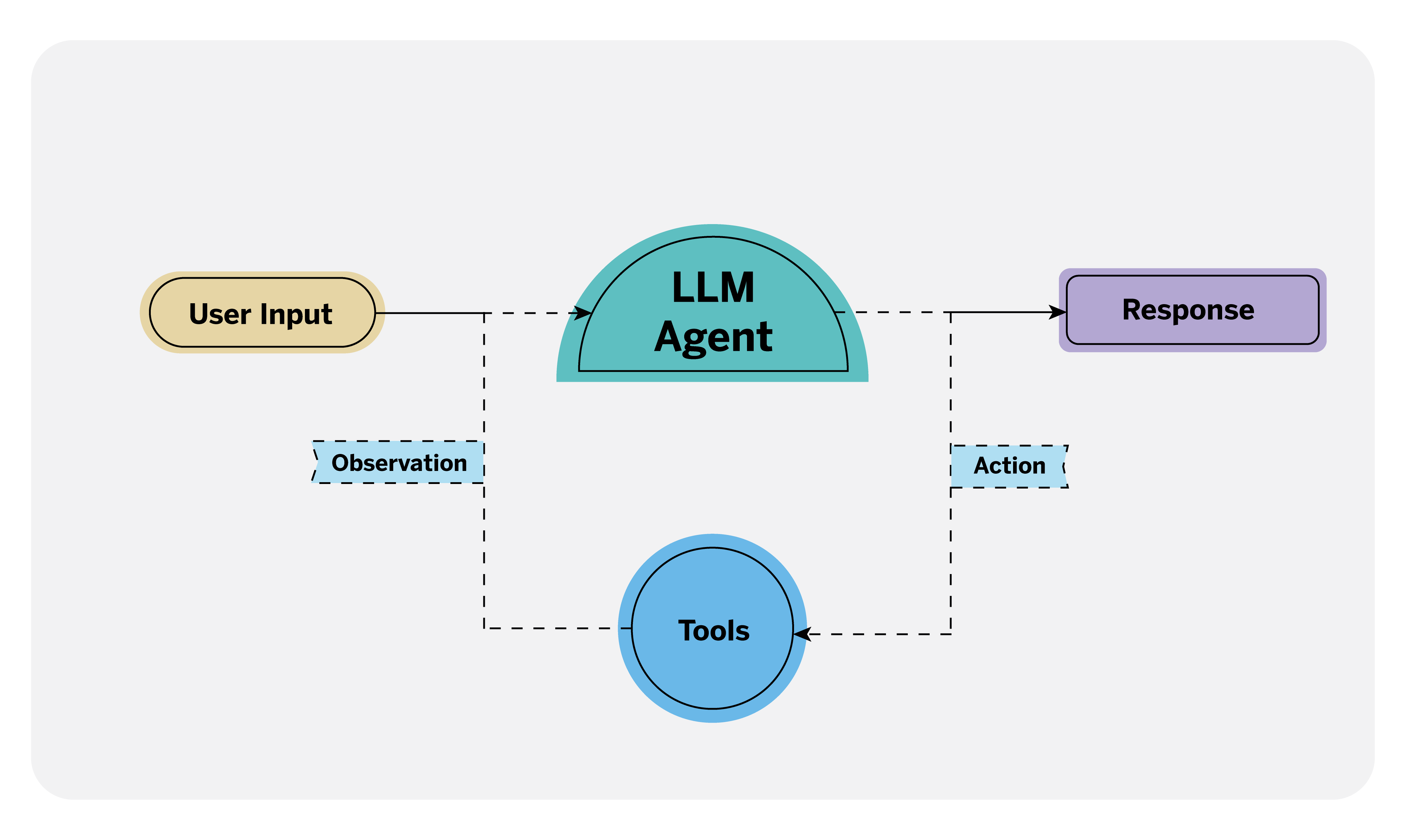
Because the most advanced language models are trained specifically for these tasks, they can recognize when to invoke one of the defined tools, retrieve the necessary parameters, and perform the action accordingly.
Conclusions
These LLM applications are profoundly changing our daily work as data scientists. Tools like GitHub Copilot make coding more accessible, while techniques like prompt critique improve the quality of the prompts we write. They allow us to identify gaps and correct instructions that could be clearer and more accurate in automated tagging tasks.
In addition, using LLM to automate repetitive tasks allows us to focus on interpreting results and making strategic decisions. This revolution opens up new research and application areas, allowing us to use our creativity to solve complex problems that machines cannot yet solve.
Artificial intelligence is a constantly evolving field, and new discoveries and updates continue redefining how we work in the technology sector.

Notes
- A set of instructions that the user gives to the LLM and that condition the generation of the text that is returned by the LLM as a response.↩︎
- Interfaces that allow an LLM to interact with the world. They consist of well-defined, executable workflows that agents can use to perform various tasks. Often they can be thought of as specialized external APIs. ↩︎