
Improving Predictions in Deep Learning by Modelling Uncertainty
At BBVA we have been working for some time to leverage transactional data of our clients and Deep Learning modes to offer a personalized and meaningful digital banking experience. Our ability to foresee recurrent income and expenses in an account is unique in the sector. This kind of forecasting helps customers plan budgets, act upon a financial event, or avoid overdrafts. All of this, while reinforcing the concept of “peace of mind”, which is what a bank such as BBVA aims to herald.
The application of Machine Learning techniques to predict an event as being recurrent, together with the amount of money involved, allowed us to develop this functionality. As a complement to this project, at BBVA Data & Analytics we are investing in research and development to study the feasibility of Deep Learning methods in forecasting1 . This has already been explained in the post “There is no such thing as a certain prediction”. The goal was not simply to improve the current system, but to generate new knowledge to validate these novel techniques.
As a result, we have observed that Deep Learning contributes to reducing errors in forecasting. Nonetheless, we have also have seen that there are still cases in which certain expenses are not predictable. Indeed, simple Deep Learning for regression does not offer a mechanism to determine uncertainty and hence measure reliability.
Making good predictions is as important as detecting the cases in which those predictions have an ample range. Therefore, we would like to be able to include this uncertainty in the model. This would be useful not only for showing clients reliable predictions but also for prioritizing actions related to the results shown. This is why we are now researching Bayesian Deep Learning models that can measure uncertainty related to the forecast.
Measure uncertainty to help clients
The detection of confident user behaviors for prediction purposes requires an analysis of the concept of the uncertainty of the prediction. However, what is the source of uncertainty? Although the clarification of this concept is still an open debate, in Statistics (or at times in Economics),it is classified in two categories: The aleatoric uncertainty (i.e. the uncertainty manifested due to the variability of the different possible correct solutions given the same information to predict) or epistemic uncertainty (i.e. the uncertainty related with our ignorance of what is the best model to use in order to solve our problem, or even our ignorance vis á vis this new kind of data that we were not able to appreciate in the past).
From a mathematical point of view, we could try to find a function based on certain input data (logged transactions of a certain user) that would return the value of the next transaction in a time series in the most accurate way possible. Nevertheless, there are limits to this approach: in our case, given the same information -past transactions-, the results are not necessarily the same. Two clients with the same past transactional behavior do not necessarily imply similar transactions in the future.
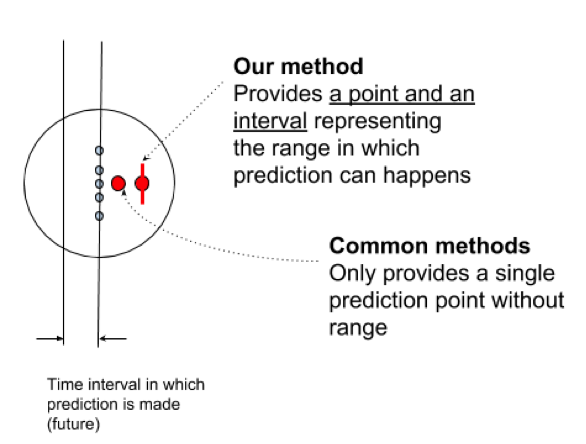
The following figure visualizes the concept of uncertainty and tries to answer the question of what the value would be of the red dot during a certain time interval.

In this case, a model with or without uncertainty would predict the following outputs:
In order to approximate this function, a good state-of-the-art solution for this problem is Deep Learning algorithms due to their capacity to fit very complex functions to large datasets. The standard way to build D Learning algorithms provides a “pointwise” estimate of the value to predict but does not reflect the level of certainty of the prediction. What we are looking for here is to obtain a probability distribution model of the possible predictions by using Deep Learning algorithms.
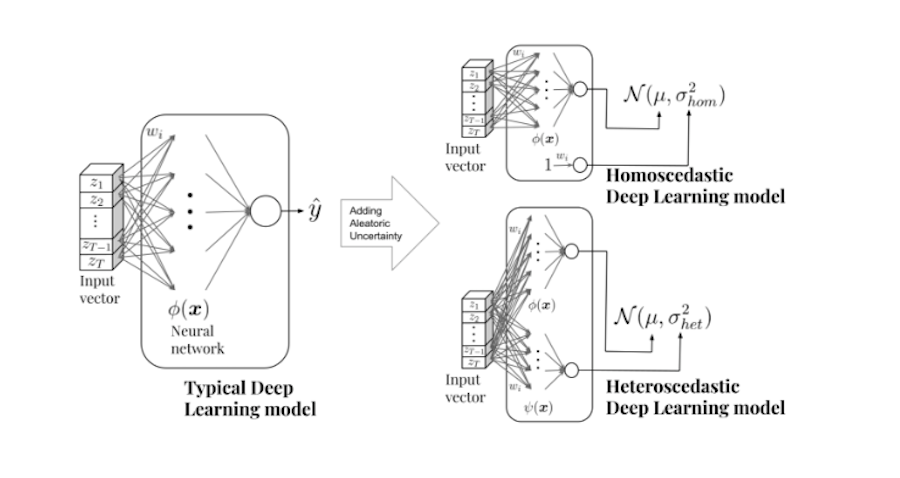
We can model two types of aleatoric uncertainty: homocedastic uncertainty, which reflects a constant variance for every client, and heterocedastic uncertainty, which accounts for the variance of each individual client given their transactional pattern.
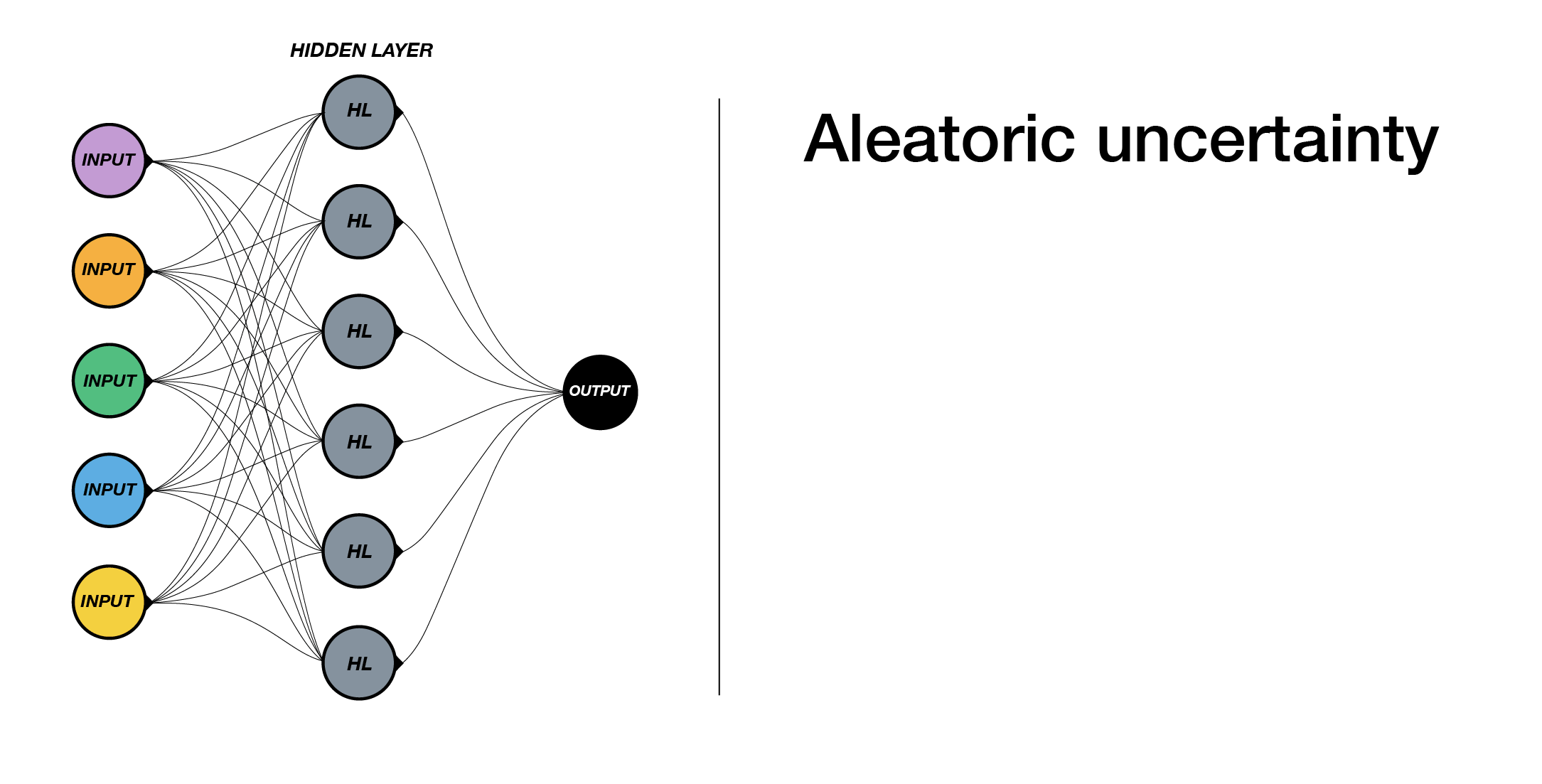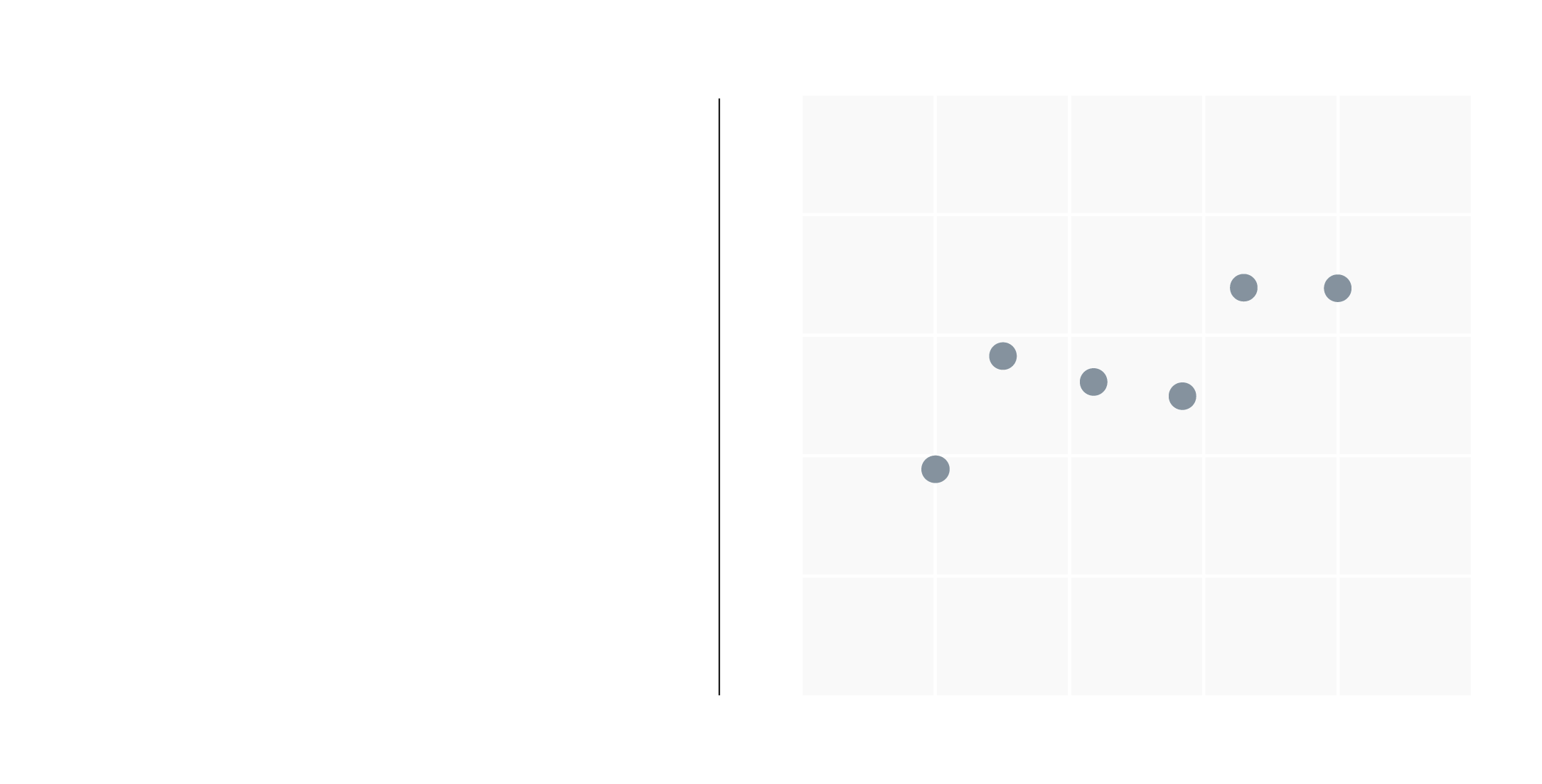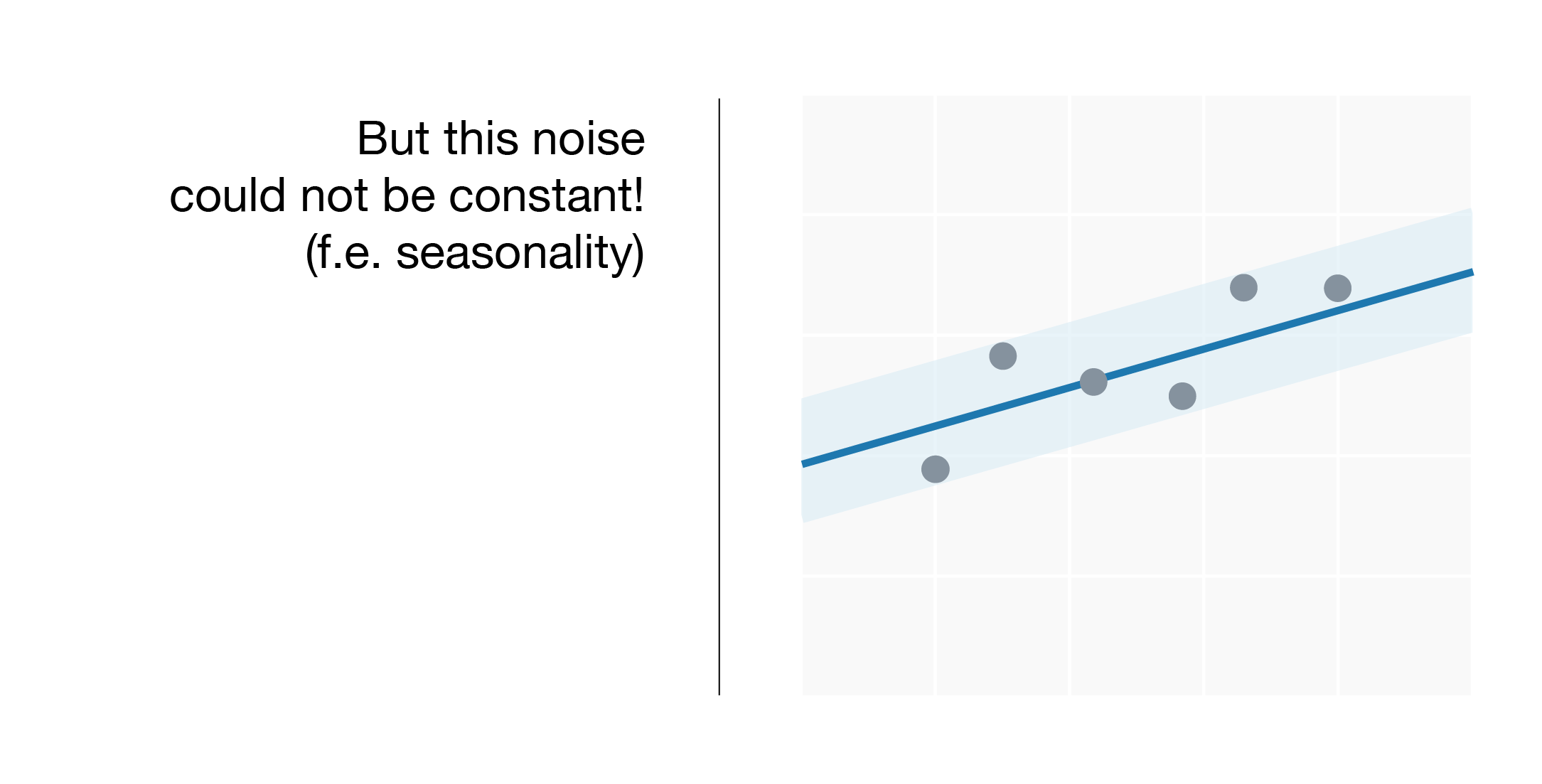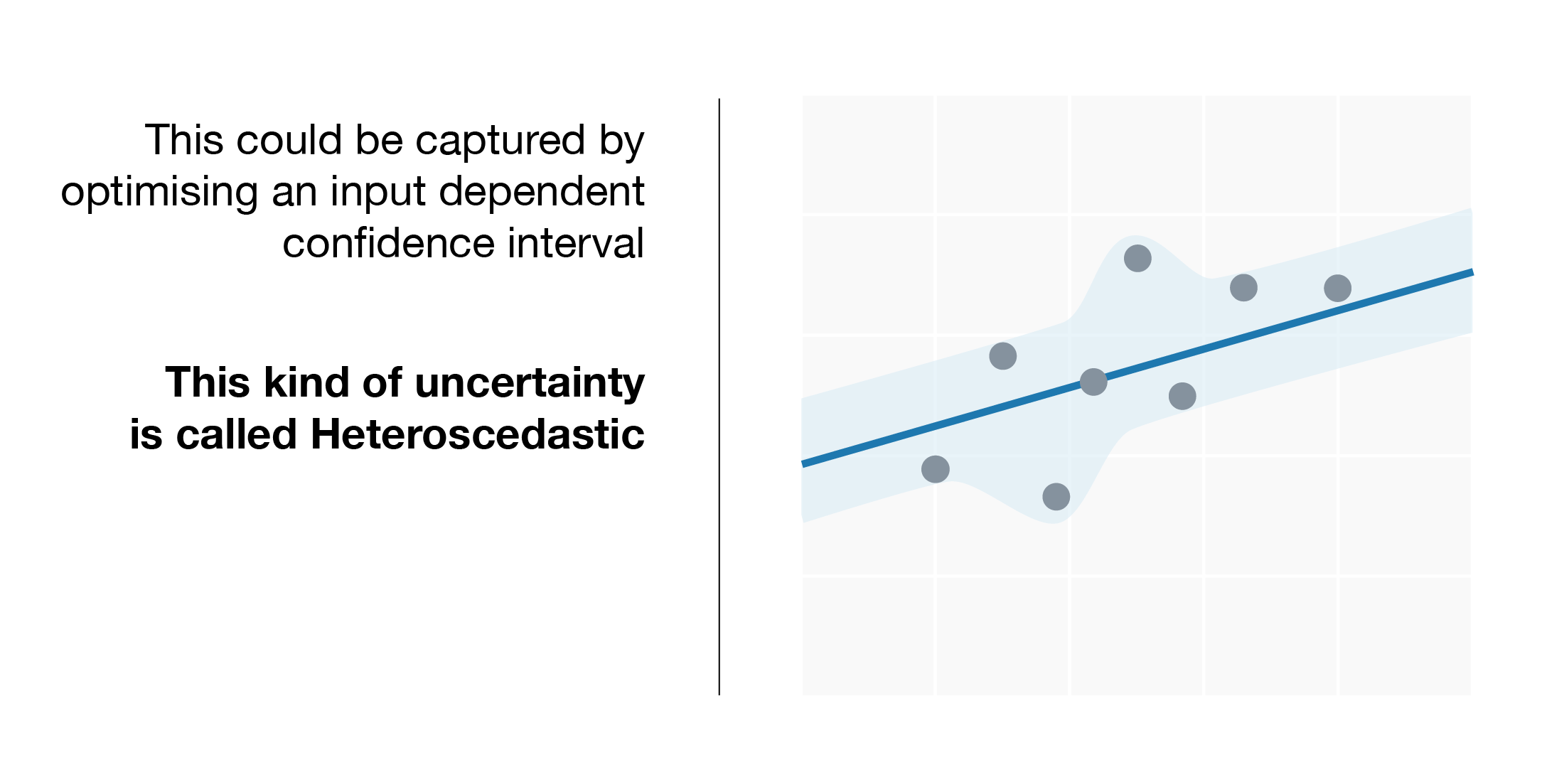
In any case, the usefulness of the aleatoric Deep Learning against the epistemic Deep Learning is greater. In fact, we have detected a clear improvement in our ability to gain a measure of confidence of each prediction, especially because we can gauge the variance.
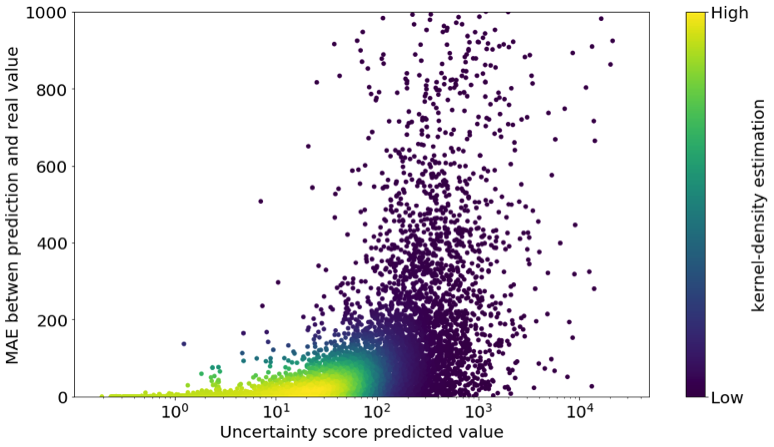
The type of uncertainty that we have taken into account is extremely useful when we have to create a new model that can forecast incomings and expenses. In the following plot each point is a user plotted with their own real error prediction versus the predicted uncertainty score. Furthermore, we see that most yellowish points (the majority of clients) have a low error and a low uncertainty score that allows us to ascertain that it makes sense to use this score as a confidence score
.
The potential applications of this approach to Business range from being able to recommend measures to avoid overdrafts, create shortcuts to most common transactions, improve financial health, or identify unusual transactions in the transaction history. We could also provide the client with feedback concerning how certain our predictions are in terms of future occurrence.

Notes
- This research was synthesized in an article accepted for publication that will be presented in the ECML-PKDD 2018, and that is opened in the e-Print service arXiv. ↩︎
- This article has been written by Axel Brando Guillaumes.