
Our approach to human data annotation in the age of Gen AI
Data annotation remains critical in building effective AI models. Traditional AI models require accurate labels for training, which sometimes necessitates annotation. In Generative AI, annotation is vital, especially in evaluation. Annotation can be conducted manually (human annotation) or automatically (e.g. using LLMs for the purpose or metrics like BLEU or ROUGE).
Depending on the specific problem we need to solve, it’s essential to determine when it’s convenient to automate and when it’s best to rely on human annotators or a combination of both.
Data annotation is often a bottleneck in AI projects due to its complexity and resource requirements. Large Language Models (LLMs) can automate this process by interpreting natural language queries. For example, when evaluating a RAG1 (e.g. a chatbot assistant using Retrieval-Augmented Generation), an LLM is able to assess whether the generated response answers the user query.
However, relying solely on automation may not always be advisable. Automation bias—where humans over-rely on machine decisions—can introduce errors and perpetuate biases inherent in training data.
Moreover, these models might use criteria that do not align with the specific needs of a given project. Thus, it’s essential to ensure models meet ethical and functional standards, which can be achieved through a robust in-house human annotation methodology. This system lays the groundwork for developing automated tools aligned with human criteria and project-specific requirements.
Yes, human data annotation, but consider the challenges
Human annotation is recommendable for high-quality and nuanced results when evaluating generative models. However, we must recognize the challenges we face when tackling this task.
First, annotators’ subjectivity can lead to inconsistencies, particularly when they have different understandings of the task at hand. To mitigate this issue, we must count on comprehensive guidelines with specific examples to standardize the annotation process.
Secondly, managing the scale of datasets is a significant challenge in data annotation. It is often necessary to have large, well-annotated datasets in order to perform effectively. However, this makes the annotation process time-consuming and demanding. In this sense, balancing cost and quality is crucial.
Before starting the annotation process, it is important to estimate the minimum size of the dataset and establish agreement thresholds. This ensures that the dataset is manageable and meets the necessary quality standards from the beginning.
Facing complex data annotation tasks: our methodology
Imagine you want to create a conversational assistant (chatbot) and measure the accuracy of its responses. But the question arises: what does an accurate response mean? To define this criterion objectively and annotate accordingly, you need to follow a series of steps:

 Select a group of people and assign roles
Select a group of people and assign roles
Before embarking on an annotation project, decide who will be the Annotation Owner. This should be the person or group that will benefit from the annotation task, such as the team developing the chatbot. This person will be responsible for evaluating and monitoring the system.
Next, choose a group of annotators who will handle the manual annotation task. It is important that these individuals have knowledge of the project domain. For instance, if the chatbot is intended for customer service, the annotators should be familiar with customer service protocols. Once the guidelines are defined, these annotators can make informed decisions.
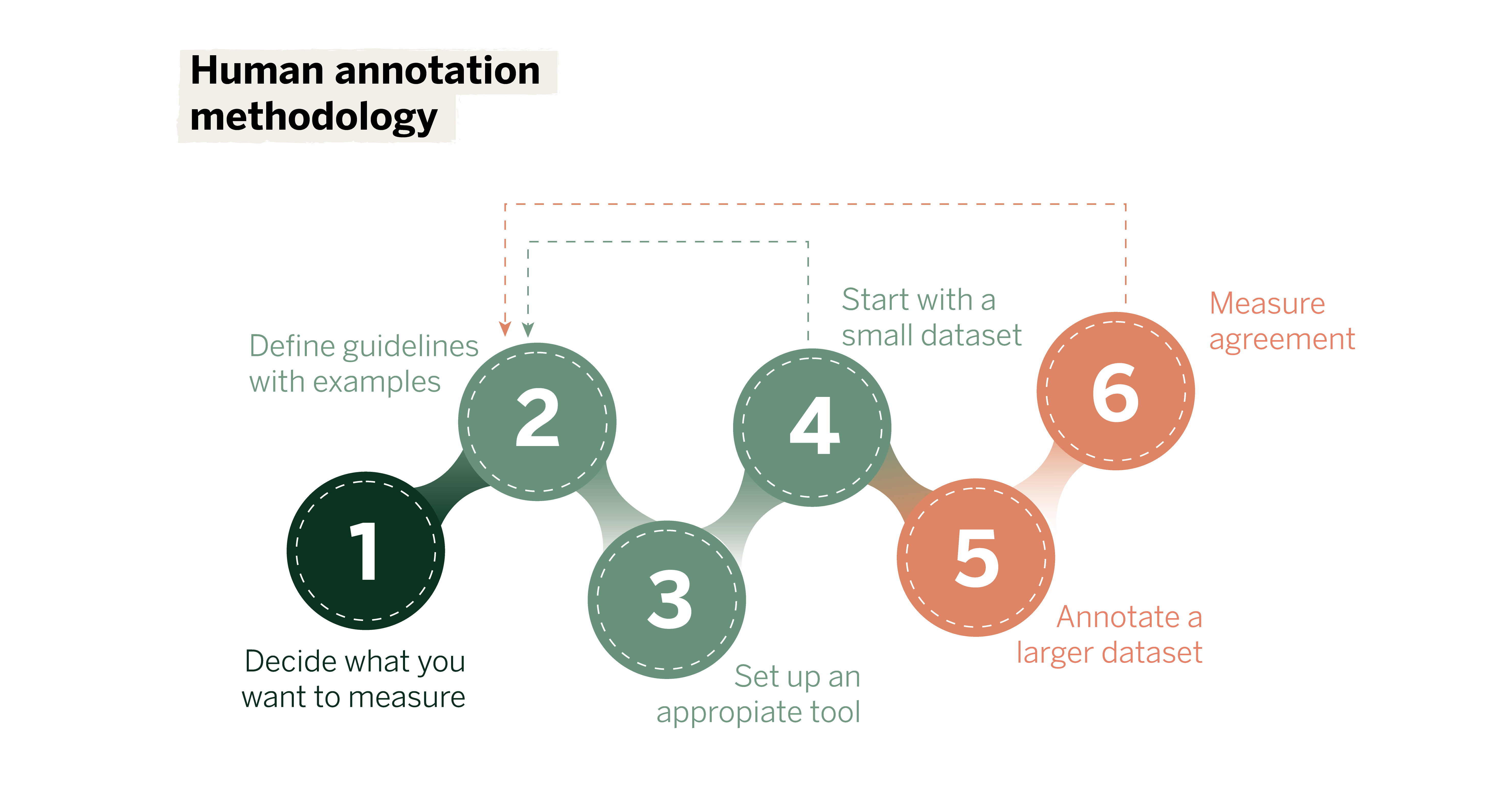
 Decide what you want to measure
Decide what you want to measure
Before starting data entry, clearly define what you want to measure. This involves thoroughly understanding the project’s objectives and how the annotated data will contribute to achieving them.
Ask yourself: what is the main objective of the model? In this case, it might be to provide accurate and helpful responses to customer inquiries. What types of patterns or information need to be extracted from the data? How will the annotated data be used to train and evaluate the model? Clearly defining what you want to measure ensures that annotation efforts align with project objectives, thus avoiding unnecessary or irrelevant data collection.
 Define guidelines with examples
Define guidelines with examples
Annotation guidelines should be accompanied by concrete examples illustrating how to apply the criteria in real situations. This helps annotators better understand expectations and handle ambiguous or complex cases. When defining guidelines for the chatbot:
- Include examples of accurate (correctly scored) and inaccurate (incorrectly scored) chatbot responses.
- Provide detailed descriptions of each example, explaining why it was annotated that way.
- Update examples as new cases are identified or annotation criteria are refined.
- Use simple, straightforward language in annotation guidelines.
- Avoid complex or subjective criteria that may lead to inconsistent interpretations.
- Ensure that each annotation criterion is measurable and observable.
Clear and detailed examples help align the interpretation of criteria among all annotators, improving annotation consistency.
 Configure an appropriate tool for the use case
Configure an appropriate tool for the use case
Using the right annotation tool can improve project efficiency and accuracy. Some examples are Label Studio, Amazon SageMaker Ground Truth, and other annotation platforms—research which is most appropriate for the task and within your budget.
 Do a few rounds with a small set of data and refine the guidelines
Do a few rounds with a small set of data and refine the guidelines
Before jumping into scoring a large volume of data, start with a small dataset. This allows you to identify and troubleshoot problems in the guidelines and annotation process. To do this:
- Select a dataset that is representative but manageable in size.
- Conduct several rounds of annotation, assessing consistency and accuracy in each round.
- Gather feedback from annotators on the guidelines and process.
- Take the examples with disagreement, have a session with the team of annotators, and refine the guidelines with the conclusions of the discussion. These refinements can consist of specific examples or more detailed instructions.
The annotation owner must be actively involved throughout the annotation process, from the initial definition phase to conducting several runs. This involvement includes serving as one of the annotators and participating in the initial runs with a small dataset.
 Annotate the large dataset
Annotate the large dataset
Once the guidelines are well defined and tested with a small dataset, it is time to annotate the entire dataset. Ensure to:
- Break the dataset into smaller batches and set specific goals for each batch. For instance, if your goal is to annotate 200 samples, break the examples into three rounds of 50, 75, and 75 samples and measure the agreement in each round.2
- Train annotators using the refined guidelines and developed examples.
- Implement a quality control system to monitor and review annotations regularly.
- Provide tools and resources that make the annotation process more efficient and accurate.
Annotating a large dataset requires careful planning and continuous monitoring to maintain the quality and consistency of the annotations.
 Measure the agreement and return to the guidelines
Measure the agreement and return to the guidelines
After annotating the large dataset, measure the level of agreement between annotators (known as inter-annotator agreement). This can be done using metrics such as Cohen’s Kappa coefficient or percent agreement. If the level of agreement is low:
- Review the guidelines and examples provided.
- Identify areas of ambiguity or confusion and clarify the criteria.
- Provide additional feedback and training to annotators.
If necessary, return to the guidelines to refine the criteria before proceeding with further annotations. This iterative cycle of evaluation and adjustment is vital to ensure that annotations are accurate and consistent over time.
By following these steps, you can systematically define and measure the accuracy of your chatbot’s responses, ensuring that it meets the intended performance standards and effectively serves its users.
Developing an LLM judge
Once we can ensure human annotation works correctly and there is a clear consensus on the criteria to follow, it is possible to create an automatic evaluator based on a large language model. You can develop an “LLM judge” evaluator by providing it with the guidelines for annotators, a specific prompt, and a set of manually annotated data. How to do this properly and efficiently is an active line of research with its advantages and limitations.3
The LLM judge’s performance can then be compared with the previously defined human criteria. For this comparison, the agreement between human annotators can be used as a benchmark. Suppose the agreement between the LLM judge and a human is similar to the agreement between humans. In that case, we can consider that we have reached human-level performance with the LLM judge, allowing us to use it in the future to automate the evaluation process.
Summing up
Human annotation is still an essential task in evaluating generative AI models, but it can be very time-consuming and tedious. It is important to approach it progressively and systematically, ensuring that objective criteria are met. Once this is done and a solid baseline with human annotations has been established, we can proceed to build LLM models that reflect the nuanced decisions made by human annotators, thereby maintaining the quality and reliability of the annotations.
In conclusion, integrating LLMs for automatic annotation should be approached as a complementary tool that enhances efficiency rather than completely replacing human oversight. By combining the strengths of both human and machine capabilities, we can achieve more robust, efficient, and ultimately more responsible AI models.
References
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … & Kiela, D. (2020). “Retrieval-augmented generation for knowledge-intensive nlp tasks.” Advances in Neural Information Processing Systems, 33, 9459-9474.↩︎
- Sim, Julius, and Chris C. Wright. “The kappa statistic in reliability studies: use, interpretation, and sample size requirements.” Physical therapy 85.3 (2005): 257-268.↩︎
- ZHENG, Lianmin, et al. “Judging llm-as-a-judge with mt-bench and chatbot arena.” Advances in Neural Information Processing Systems, 2024, vol. 36. ↩︎