
Formación, Una Ventaja Esencial para Retener un Perfil de Científico de Datos
El primer hito de BBVA Data & Analytics se alcanzó en 2011, cuando la Unidad de Innovación de BBVA creó un pequeño equipo de investigación, comprometido con el uso de las fuentes de datos existentes para resolver los retos de negocio. Varias colaboraciones externas con instituciones de investigación, otras startups, corporaciones de telecomunicaciones e instituciones públicas, ofrecieron resultados prometedores, como la identificación masiva de clientes altamente rentables anteriormente etiquetados como clientes estándar, e hicieron visible la necesidad de un enfoque estratégico sólido para el descubrimiento y análisis de datos.
Así se constituyó BBVA Data & Analytics, en febrero de 2014, una subsidiaria propiedad de BBVA, principalmente por dos razones: queríamos comercializar productos no financieros basados en datos y contar con un modelo más ágil y diferenciado de atracción y gestión del talento, tanto desde el punto de vista operativo como cultural.
¿Qué necesitábamos en ese momento?
Por ello, queríamos atraer a personas altamente cualificadas y con talento, capaces de extraer valor de grandes cantidades de datos, hacer recomendaciones, identificar patrones, proponer nuevas explicaciones a las tendencias y nuevas soluciones a los problemas, y traducirlas a un lenguaje comprensible para nuestros homólogos de las unidades de negocio de BBVA. Necesitábamos científicos de datos. Y queríamos los mejores Científicos de Datos del mercado. Nos imaginamos que todos habéis oído que ésta es la profesión más sexy del mundo. Más que sexy, era un perfil realmente nuevo y desconocido, en aquel momento, y muy difícil de encontrar y definir, sobre todo a la hora de detectar a los mejores profesionales del sector. No es fácil lograr una combinación equilibrada entre estadística, programación, herramientas Big Data, conocimientos de aprendizaje automático, capacidad de resolución de problemas, capacidad de comunicación y una buena intuición para comprender y explorar los problemas del Banco. Por ello, era necesario diseñar un modelo de gestión del Talento y Cultura enfocado a atraer y retener ese talento, una vez encontrado.
Nuestro enfoque
El primer paso que dimos fue adquirir un profundo entendimiento de lo que significa trabajar como un Científico de Datos y cuáles son las aspiraciones de los mismos. Durante 8 meses entrevistamos a un promedio de 2 a 3 candidatos al día, incluyendo miembros del personal en el proceso. Pronto tuvimos una idea bastante clara de qué conductores son la clave para ellos. Por ello, diseñamos políticas y procedimientos a la medida de sus necesidades y expectativas de una manera efectiva y atractiva. Entendimos que la gestión a medida, el empoderamiento y la flexibilidad eran primordiales.
El mercado es demasiado exigente y paga demasiado por este tipo de perfil escaso y los científicos de datos reciben ofertas de trabajo a diario. Sin embargo, en términos generales, ¡no se trata sólo de dinero! Un salario más alto no es la clave si no viene acompañado de desafíos analíticos y un ambiente de trabajo flexible, algo que hemos aprendido escuchando a nuestros Científicos de Datos.
Asimismo, mantenerse al día es una necesidad para su desarrollo profesional y una de sus principales preocupaciones. Ser capaces de ampliar sus conocimientos, llevar a cabo investigaciones, publicar artículos científicos y, en última instancia, impulsar el estado del arte de la disciplina.
Todo esto mientras se trabaja en una empresa con proyectos a tiempo real significa un gran atractivo para estas personas, y está disponible en muy pocas empresas.
Se trata de perfiles con conocimientos e intereses muy diferentes, a diferentes niveles. Además, estamos convencidos de que cada uno de los miembros de nuestro equipo es el más adecuado para identificar y elegir la formación que mejor se adapte a sus necesidades, motivaciones y nivel de conocimiento. Y así, les entregamos esa decisión. Una de nuestras competencias clave es la Responsabilidad Flexible; nos gusta aplicarlo a todo lo que hacemos, por lo que el plan de formación no iba a ser una excepción. Así, en lugar del clásico catálogo de formación general, que no cubre sus necesidades especiales, hemos diseñado un plan de formación básica, individual y extraordinaria basado en tres ejes, asignando un presupuesto para cada uno de ellos.
La formación básica cubre las necesidades transversales del equipo, tales como el dominio de idiomas, el desarrollo de habilidades o alguna herramienta técnica que sea utilizada por todos. Así mismo, cada empleado tiene asignado dinero por cada año para formación individual, basada en su elección personal, siempre y cuando se relacione con nuestra actividad. La formación extraordinaria se presupuesta para eventos y conferencias mundiales, u otra formación que exceda el presupuesto de formación asignado individualmente, de la que el equipo en general puede beneficiarse. Compartir conocimientos, tanto en sesiones en profundidad como en talleres, es una condición principal para obtener la aprobación de su solicitud.
Cómo eligió nuestro equipo su formación a lo largo de los años
Desde 2015, cuando nuestro modelo de gestión del Talento se hizo realidad, nuestros Científicos de Datos tuvieron la oportunidad de elegir cómo gastar el dinero asignado por persona, cada año, a la formación individual y extraordinaria. El 93% de nuestros Científicos de Datos aprovecharon el pasado año su presupuesto de formación individual, en comparación con el 82% que lo hizo en 2016, y a lo largo de 2017, el 56% de nuestros empleados gastó por encima del 90% del presupuesto asignado. En 2015, los cursos online eran la primera opción de formación, con un 30% sobre el total, mientras que actualmente los cursos presenciales son los preferidos, representando el 59% del total.
Dado que los datos forman parte de nuestra cultura, echemos un vistazo a algunas cifras cuantitativas. En el gráfico siguiente se puede explorar la evolución de las categorías de gasto a lo largo de los años:
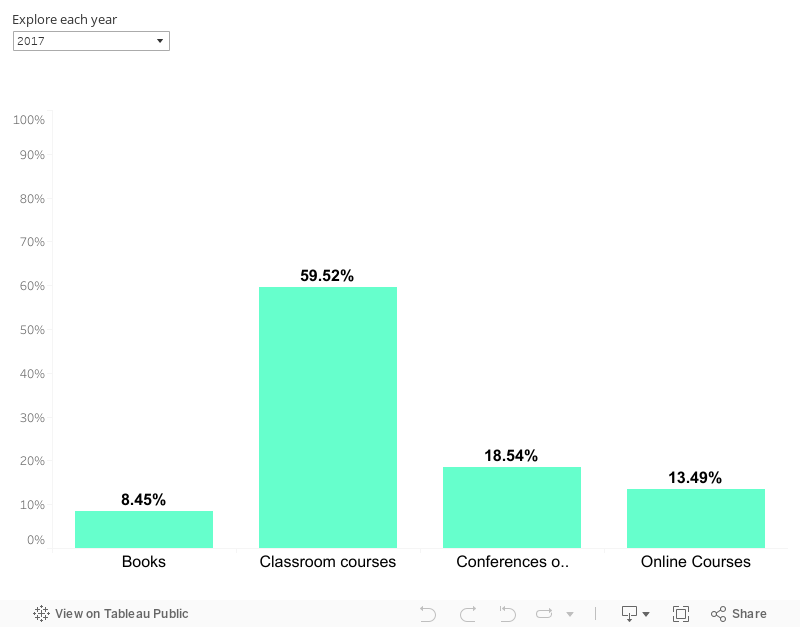
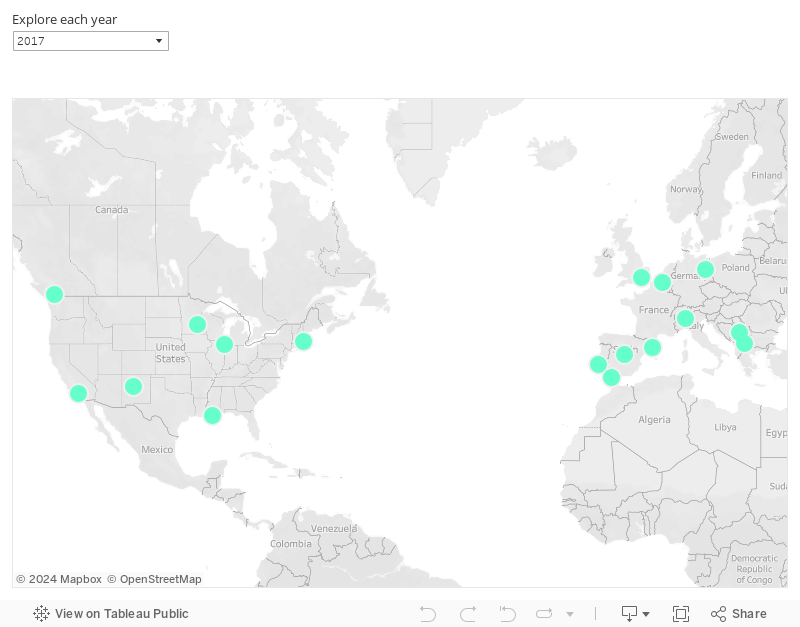
Al mismo tiempo, nuestro equipo tiene la posibilidad de mantenerse al día con el estado del arte en Ciencia de Datos asistiendo a numerosas conferencias de su elección. Abajo puedes explorar dónde hemos estado:
Lo que hacemos y lo que somos es lo que nos define
Todo el trabajo que hemos realizado forma parte de una filosofía de aprendizaje continuo y proceso de desarrollo personal, concebido para ser ágil, basado en la escucha activa y bidireccional, y la acción inmediata. Con todas las políticas, procedimientos y estilo de gestión que hemos desplegado aquí, hemos creado una cultura de empresa que es el resultado de lo que hacemos y lo que somos, y no de lo que decimos que deberíamos ser.
Nuestro equipo ha propuesto de forma espontánea posibles temas de formación, así como la posibilidad de invitar a Científicos de Datos de Alto Nivel1 a participar en charlas relacionadas con técnicas de vanguardia y cómo aplicarlas a nuestros problemas en sesiones de trabajo con nosotros.
Notas
- Algunos de estos científicos de alto nivel son: DJ Patil (Anteriormente Científico Jefe de Datos de la Oficina de Políticas de Ciencia y Tecnología de la Casa Blanca), Usama Fayyad (Director General de Datos y Director General del Grupo en Barclays Bank), Le Song (Profesor Asistente en el Instituto de Tecnología de Georgia), Kalyan Veeramachaneni (Investigador Científico del MIT), Roberto Paredes (Profesor Asociado de la Universidad Politécnica de Valencia), Jordi Vitrià (Profesor en la Universidad de Barcelona e Investigador Senior en Centro de Visión por Computador), Carmen Cadarso Suárez (Profesor en Biostatech, Universidad Santiago de Compostela), Fernando Pérez-Cruz (Profesor Asociado en la Universidad Carlos III de Madrid), Miguel Romance (Profesor Asociado en la Universidad Rey Juan Carlos de Madrid), Regino Criado (Profesor Asociado en la Universidad Rey Juan Carlos de Madrid), Lisa Gansky (Directora Ejecutiva de 11FS), Barbara Wixom (Principal Investigadora Científica del MIT CISR), Alex Arenas (Profesor en la Universidad Rovira i Virgili,), JJ Ramasco (Investigador en IFISC), Yuri Engelhardt (Diseñador de Información), Eneko Agirre (Investigador en el área de Procesamiento del Lenguaje Natural de la Universidad del País Vasco), y recientemente, José Vicente Rodríguez Mora (Investigador para The Alan Turing Institute), por nombrar algunos.↩︎
- Artículo escrito por Ana de Melo e Faro