
¿Cómo ayuda el Procesamiento de Lenguaje a los gestores de BBVA?
En el ámbito de la tecnología, y especialmente en el desarrollo de soluciones basadas en Inteligencia Artificial, la experimentación y la innovación son tareas que forman parte fundamental de nuestro trabajo. Desde BBVA AI Factory apostamos por reservar bloques de tiempo específicos para experimentar con tecnología del estado del arte y trabajar en ideas y prototipos que más adelante podrían incorporarse al abanico de soluciones basadas en IA de BBVA. Son lo que llamamos los sprints de innovación.
En uno de estos sprints nos preguntamos cómo podríamos ayudar a los gestores en sus conversaciones con los clientes. Los gestores, que asesoran y ayudan a los clientes en la gestión de sus finanzas, en ocasiones hacen búsquedas manuales en repositorios de respuestas predefinidas para responder a las preguntas más sencillas y frecuentes. Esto nos confirmó el potencial de desarrollar un sistema de Inteligencia Artificial que sugiriera posibles respuestas a los gestores tras recibir una pregunta de un cliente, de tal forma que con un solo click pudieran responder. La idea detrás de este sistema consistiría en ahorrar tiempo a los gestores en escribir respuestas que no requieren de su conocimiento experto, permitiéndoles así centrarse en aquellas que aporten mayor valor al cliente.
Así que nos pusimos manos a la obra. Una vez definido el problema, pronto empezaron a surgir diferentes formas de abordarlo. Por un lado, pensamos en un sistema de búsqueda de la pregunta más similar dentro del histórico a la planteada por el cliente y, posteriormente, evaluar si la respuesta que se dió en su día es válida para la situación actual. Por otro lado, también probamos a clusterizar (agrupar) las preguntas y sugerir la respuesta canónica pre-establecida para el clúster (grupo) al que pertenece la pregunta. Sin embargo, estas soluciones requerían mucho tiempo de inferencia o eran muy manuales (clustering de preguntas).
Finalmente, la solución que nos resultó más eficiente desde el punto de vista de tiempo de inferencia y que además era capaz de sugerir respuestas automáticas a multitud de preguntas de diferentes temáticas, sin tener que hacer un previo clustering, fue la de los modelos sequence to sequence también conocidos por su abreviatura en inglés: seq2seq.
¿Qué es seq2seq?
Los modelos seq2seq toman una secuencia de ítems de un ámbito y generan otra secuencia de ítems de otro ámbito diferente. Uno de sus usos paradigmáticos es la traducción automática de textos; un modelo seq2seq entrenado permite transformar una secuencia de palabras escritas en un idioma en una secuencia de palabras que mantiene el mismo significado en otro idioma. La arquitectura básica de seq2seq consiste en dos redes recurrentes (decoder y encoder), llamadas Long-Short Term Memory (LSTM).
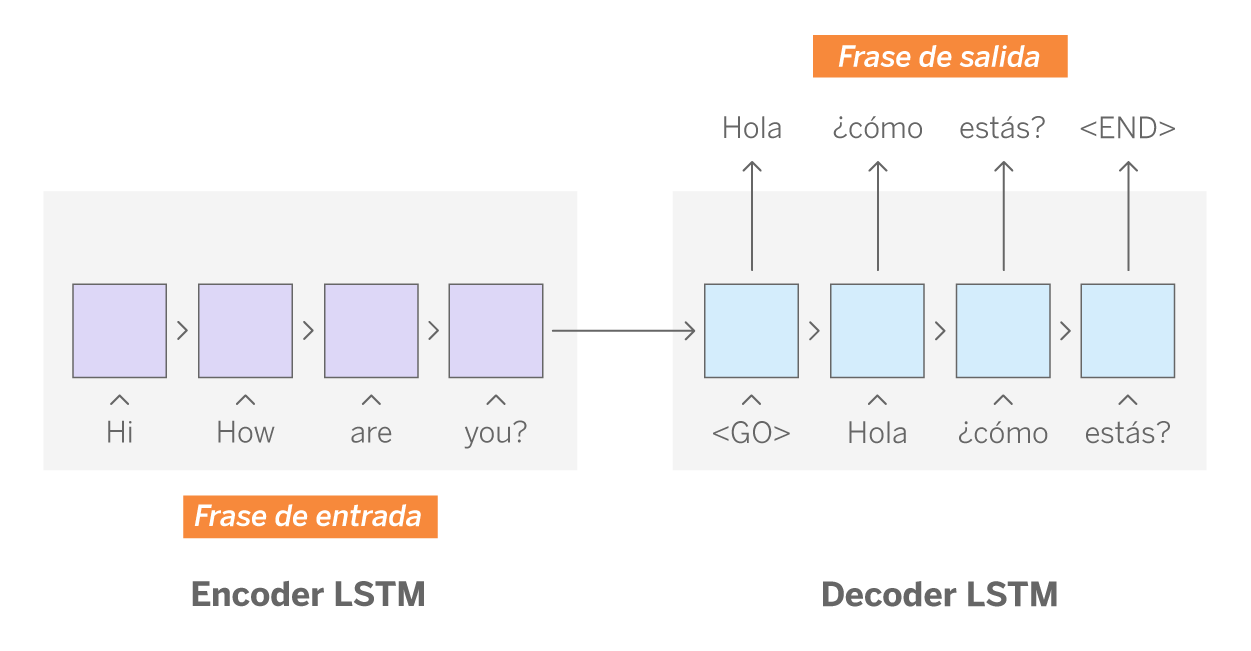
Las redes LSTM son un tipo de red neuronal en la que cada una de sus celdas (hidden units) procesa en orden un elemento de la secuencia (en este caso, la representación de una palabra). Lo peculiar de estas redes neuronales es que conservan la información relevante de la celda anterior, al mismo tiempo que descartan la información que no lo es para las siguientes celdas. De esta forma la red aprende no solo de datos aislados, sino también de la información inherente a la secuencia, que va acumulando celda a celda. Esta característica es especialmente significativa en texto, puesto que el orden de las palabras es importante para construir oraciones sintáctica y semánticamente correctas. Técnicamente, también implica una gran ventaja, ya que reduce considerablemente el coste computacional. Para conocer en más detalle las LSTM recomendamos la lectura de este post de Christopher Olah.
Para ilustrar este concepto pensemos en los modelos de lenguaje cuyo propósito es predecir cuál será la palabra siguiente más probable. Por ejemplo: “María ha nadado durante dos horas y está muy ____”. En este caso, algo importante a “recordar” (información que pasa de una celda a la siguiente) es el género del último sujeto mencionado, de forma que la red sea capaz de determinar que la palabra “cansada” tendrá mayor probabilidad de ser la palabra correcta que “cansado”.
Como hemos mencionado anteriormente, la arquitectura seq2seq se compone de dos redes LSTMs: encoder y decoder. Volviendo al caso de la traducción automática, la misión de la red encoder es aprender la estructura de las frases en inglés (secuencias de entrada), mientras que el decoder hace lo propio con las frases en español (secuencias de salida). El decoder, además, también aprende la relación que existe entre ambas secuencias. De esta forma, el resultado de la última celda del encoder es un vector, llamado thought vector, que almacena la información de las celdas anteriores y por tanto, es una representación matemática de la frase en inglés, -es decir, de la secuencia de entrada-. Finalmente, el decoder utiliza estos vectores junto con la respuesta también codificada en representación matemática para el entrenamiento. Durante el entrenamiento la red aprende los patrones que permiten asociar una secuencia de entrada y otra de salida.
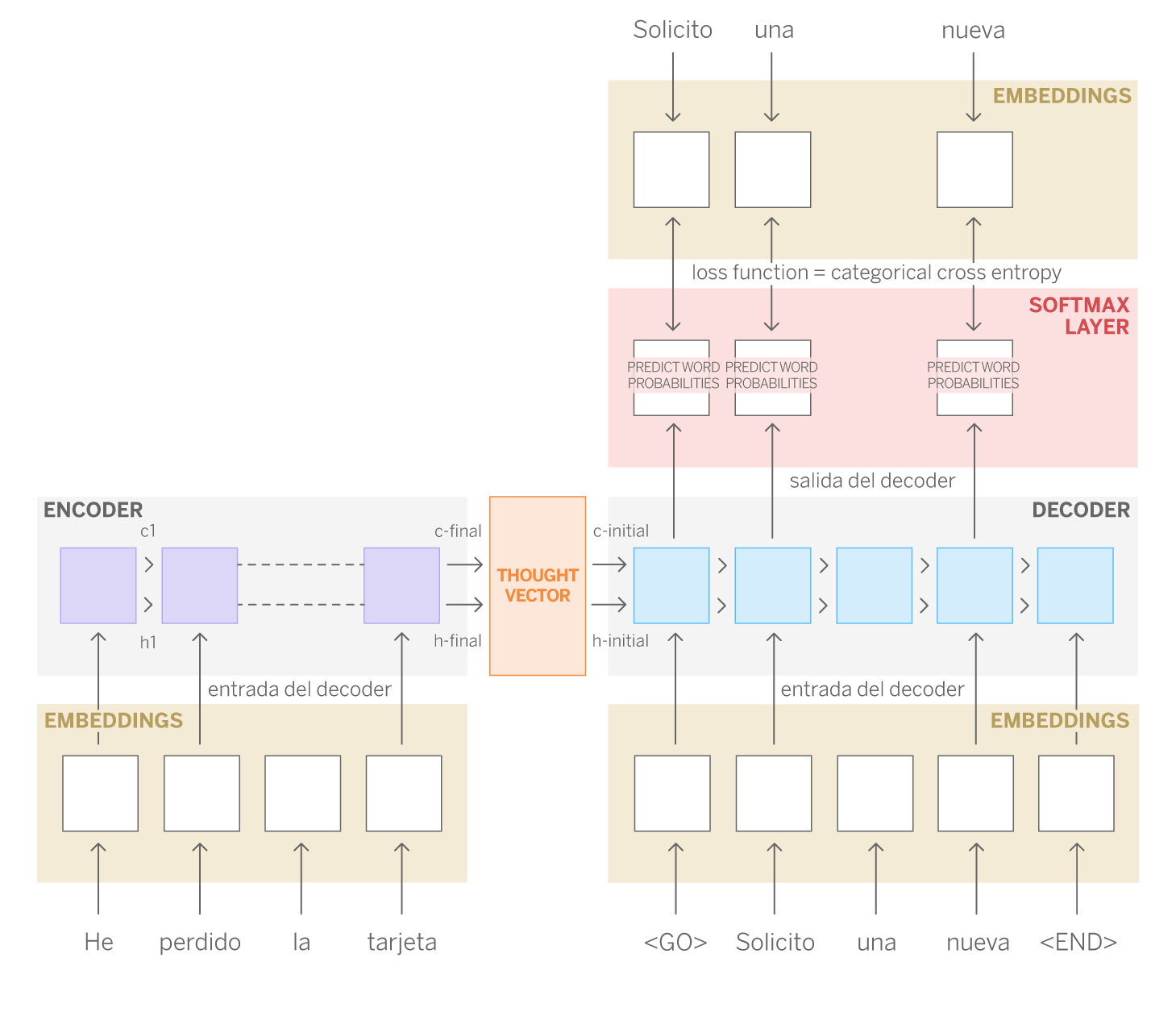
¿Cómo hemos aplicado seq2seq para construir nuestro sistema de sugerencia de respuestas?
Aunque la traducción es una de las aplicaciones más evidentes, la ventaja de estos modelos es que son muy versátiles. Trasladando su funcionamiento a nuestro caso, podríamos “alimentar” el encoder con las preguntas de los clientes (secuencia 1) y el decoder con las respuestas que en su día dieron los gestores (secuencia 2).
Y eso hicimos. Seleccionamos de nuestro histórico más de un millón de conversaciones cortas iniciadas por el cliente con su gestor (no más de cuatro mensajes). Con este conjunto de datos, realizamos un pre-procesado clásico (lowercase, eliminar signos de puntuación) y descartamos saludos y despedidas mediante expresiones regulares. Este paso es útil ya que uno de los hiper parámetros de las redes LSTM es la longitud de la secuencia a aprender y es por ello que, suprimiendo esta información no relevante, podemos aprovechar mejor la capacidad de aprendizaje del modelo para secuencias más diversas o variables, así como reducir el coste de computación que tendría aprender secuencias más largas. Previamente a la fase de preprocesamiento, aplicamos nuestra librería de NER (Named Entity Recognition) para enmascarar ciertas entidades como pueden ser importes, fechas o expresiones temporales para tratarlas de forma homogénea y que el modelo posteriormente creado les de la misma importancia.
Una vez entrenada la red utilizamos algunas preguntas de test (no incluidas en el entrenamiento) y evaluamos manualmente la sugerencia de nuestro sistema. Como vemos en el siguiente ejemplo, el modelo es capaz de sugerir una respuesta adecuada a preguntas de los clientes.

Sin embargo, cuando la pregunta está relacionada con la situación particular de un cliente, la respuesta sugerida no es del todo satisfactoria. Esto es debido a que el modelo no tiene en cuenta el contexto específico de cada cliente.
Por ejemplo, en el caso que mostramos a continuación, el sistema propone una respuesta que podría ser correcta pero no tiene en cuenta si efectivamente la tarjeta ya se ha enviado al cliente. Esta información contextual actualmente no es contemplada por el modelo. Uno de los próximos pasos en esta investigación sería conseguir que el modelo aprendiese a generar el mensaje de respuesta conforme a la situación actual del cliente ante una casuística concreta.
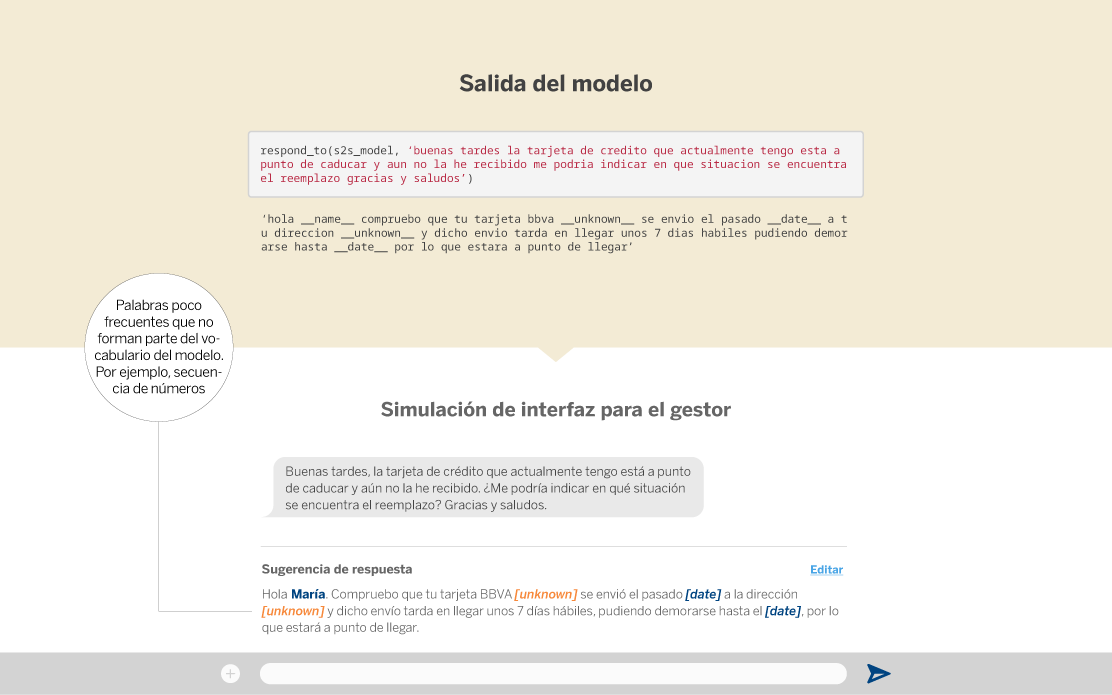
Finalmente, también existen algunos casos en los que la respuesta sugerida al gestor por el modelo no es correcta, ya que no tiene relación con la cuestión planteada por el cliente.

¿Cómo validamos nuestro modelo seq2seq?
Evaluar el resultado de un texto generado automáticamente es una tarea compleja. Por un lado, resulta imposible evaluar manualmente un conjunto de test de preguntas y respuestas relativamente grande. Además, si quisiéramos optimizar el modelo, posteriormente necesitaríamos algún método para medir la calidad y adecuación de las respuestas sugeridas por el modelo de forma automática.
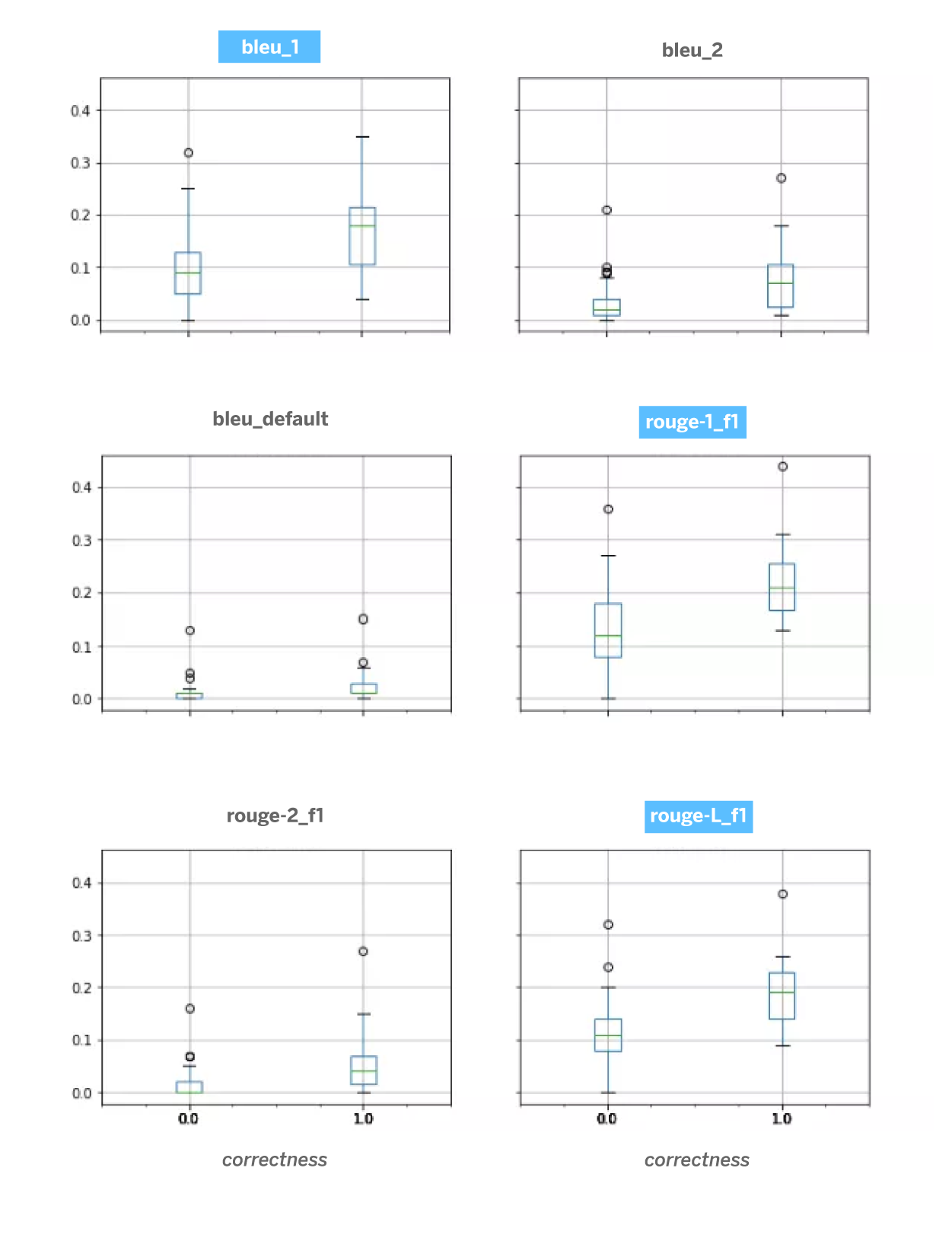
Sin embargo, sí podemos realizar una evaluación manual que nos permita obtener, con un conjunto pequeño de mensajes y según nuestro criterio como clientes1, qué respuestas son adecuadas y cuáles no, calculando posteriormente la correlación entre nuestra evaluación manual y la evaluación obtenida por conjuntos de métricas automáticas como Rouge, Blue, Meteor o Accuracy.
La siguiente figura representa la correlación entre la evaluación manual (false: respuesta incorrecta, true: respuesta correcta) y los valores de las métricas automáticas. En un primer análisis observamos que bleu_1, rouge_1 y especialmente rouge-L son las métricas que mejor se alinean con el criterio humano. Esto es importante de cara a optimizar la arquitectura de seq2seq y para la evaluación automática del sistema. Aunque este estudio requeriría más investigación, consideramos que es suficiente para esta fase de prototipado.
Con estas primeras pruebas realizadas con seq2seq (hemos omitido algunos experimentos fallidos y otras decisiones tomadas en el camino), hemos podido demostrar el enorme potencial de esta técnica en el contexto de las comunicaciones cliente-gestor en BBVA. Un sistema basado en seq2seq es capaz de sugerir respuestas a preguntas sencillas de los clientes. Sin embargo, para otras muchas tareas, como dar respuesta a preguntas relacionadas con el contexto específico de un cliente, es mucho mejor optar por la relación directa con nuestros gestores BBVA.
Notas
- Para la evaluación manual utilizamos dos criterios: answerability y correctness. La primera de estas métricas cualitativas determina en qué grado una pregunta se puede responder, con el objetivo de comprobar cuál sería el impacto de negocio, y la segunda evalúa si la respuesta sugerida por el modelo es correcta o no, lo que nos da una idea de la calidad de nuestro modelo seq2seq. Con esta evaluación comprobamos que no todas las preguntas del cliente pueden resolverse con este enfoque actualmente. La razón principal radica en la necesidad de tener en cuenta información contextual, bien sea aportada previamente por el cliente, comentada previamente por un gestor concreto o información personal y financiera del cliente. ↩︎