
Qué, cómo y cuándo: personalización de ofertas comerciales con IA
En los últimos años, el comercio electrónico ha crecido exponencialmente. La sociedad en general ha asumido esta nueva forma de compra por la facilidad e inmediatez que ofrece. BBVA no es la excepción; de hecho, el año pasado, el 79% de nuestras ventas fueron digitales.1
En este contexto donde la información, la oferta y las posibilidades de elección se multiplican, resulta oportuno adoptar un enfoque basado en la personalización de las ofertas comerciales. Tendrán más éxito aquellos productos y servicios que se adapten a lo que cada cliente precisa, en el momento y en la forma que lo necesita.
La inteligencia artificial nos ayuda en este cometido: procesando una gran cantidad de datos, mejorando así el grado de personalización de nuestras ofertas.
Del criterio experto a los datos y algoritmos
Durante décadas, las campañas comerciales se configuraban con base en el criterio experto y conjuntos limitados de datos, a partir de los cuales se identificaban públicos objetivo. Este proceso implicaba la creación y lanzamiento poco escalable de campañas estáticas.
Por ejemplo, si queríamos lanzar una campaña que ofreciera cuentas para menores, habríamos utilizado los datos disponibles en el banco para encontrar pistas que nos permitieran identificar públicos afines a ese producto. Podríamos haber buscado personas en el rango de edad de 20 a 40 años, con recibos domiciliados de colegios, guarderías o actividades extraescolares. Con esta información, habríamos configurado el público al que se dirigiría la oferta comercial. Para esta campaña, habríamos además generado un único mensaje publicitario.
Este método tiene limitaciones, ya que no considera los factores individuales de cada persona. Para superarlas, hemos creado un sistema de recomendación de productos comerciales que realiza ofertas en tiempo real. Estos mensajes se configuran a partir de múltiples fuentes de datos y utilizan modelos de aprendizaje automático.
La tecnología combinada con el criterio experto nos permite analizar miles de variables, detectando públicos más precisos y descubriendo nuevos clientes potenciales.
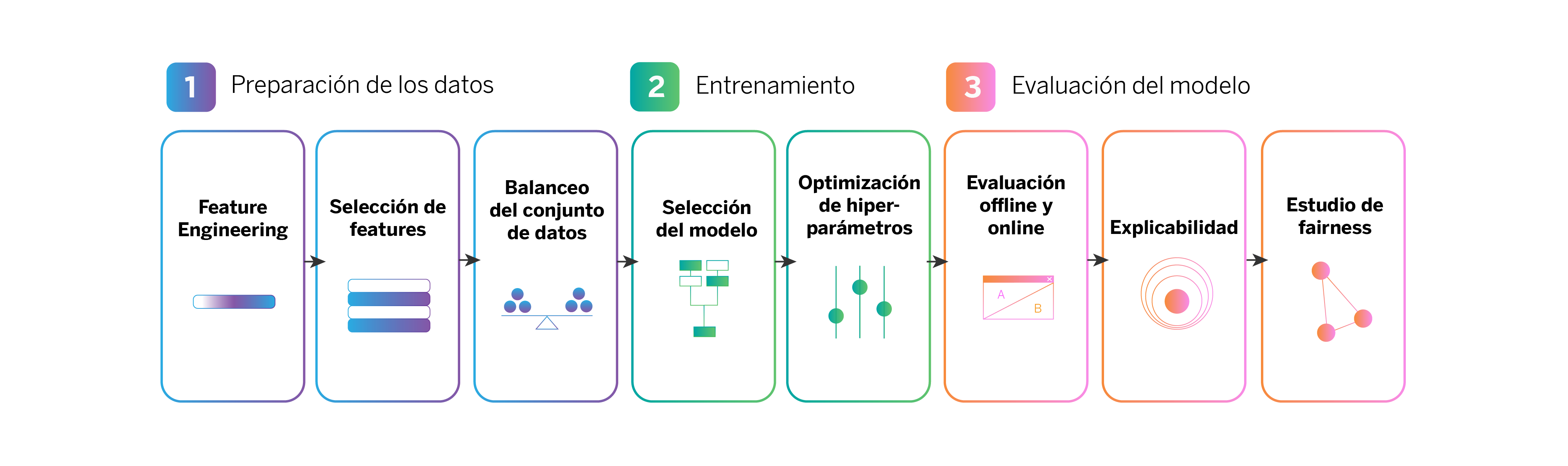
Para conseguirlo, hay una serie de pasos que seguimos, que en su conjunto son lo que definimos como nuestro pipeline de ventas digitales.
Pero, antes de profundizar en nuestro pipeline, es importante entender dos conceptos que juegan un papel fundamental en el proceso: la experimentación y el feature engineering.
Experimentación continua como forma de aprender
Los tests A/B y estudios de mercado son, por defecto, la manera de descubrir el mejor mensaje para una audiencia concreta. Actualmente, la tecnología nos permite pasar del “café para todos” a adaptar el mensaje para cada cliente, canal y momento. Además, podemos experimentar continuamente y utilizar los resultados para afinar nuestras ofertas (o su ausencia si es necesario) y brindar el mejor servicio a todos los clientes.
Los tests A/B funcionan comparando dos versiones de un elemento, como un anuncio o un correo electrónico, para ver cuál tiene mejor rendimiento. En un test A/B, una parte de la audiencia recibe la versión A y otra parte la versión B. Luego, se analizan los resultados para determinar qué versión genera mejores resultados en términos de métricas clave, como la tasa de clics o la tasa de conversión.
¿Cómo conseguimos la personalización?
Usamos muchos datos de diferentes fuentes, que procesamos cuidadosamente mediante una técnica llamada Feature Engineering. Esta técnica nos permite transformar los datos en características útiles. Por ejemplo, el gasto medio y máximo en supermercados realizado por el cliente en el último mes. De esta manera, los modelos de IA pueden entender mejor la situación financiera de nuestros clientes, su actividad en nuestra aplicación y sus intereses.
Para que estos modelos funcionen en diferentes países, utilizamos fuentes de datos estandarizadas y globales. Esta información, junto con los registros de productos que los clientes han contratado anteriormente en BBVA, es utilizada por un modelo de IA que aprende a reconocer qué características de cada cliente indican un mayor interés o necesidad por ciertos productos.
En este punto retomamos la explicación detallada de nuestro pipeline de ventas digitales, es decir, la serie de pasos que seguimos para obtener nuestras personalizaciones.
Nuestro pipeline de aprendizaje automático, paso a paso
Preparación de los datos
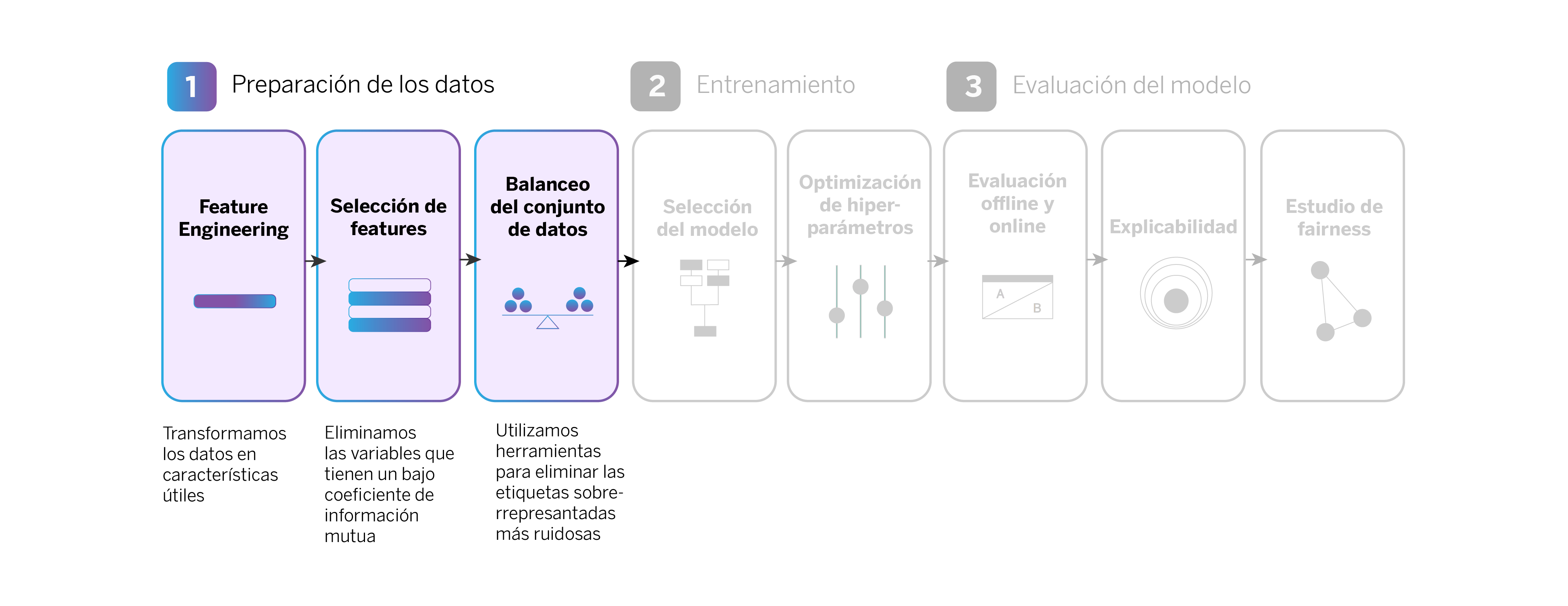
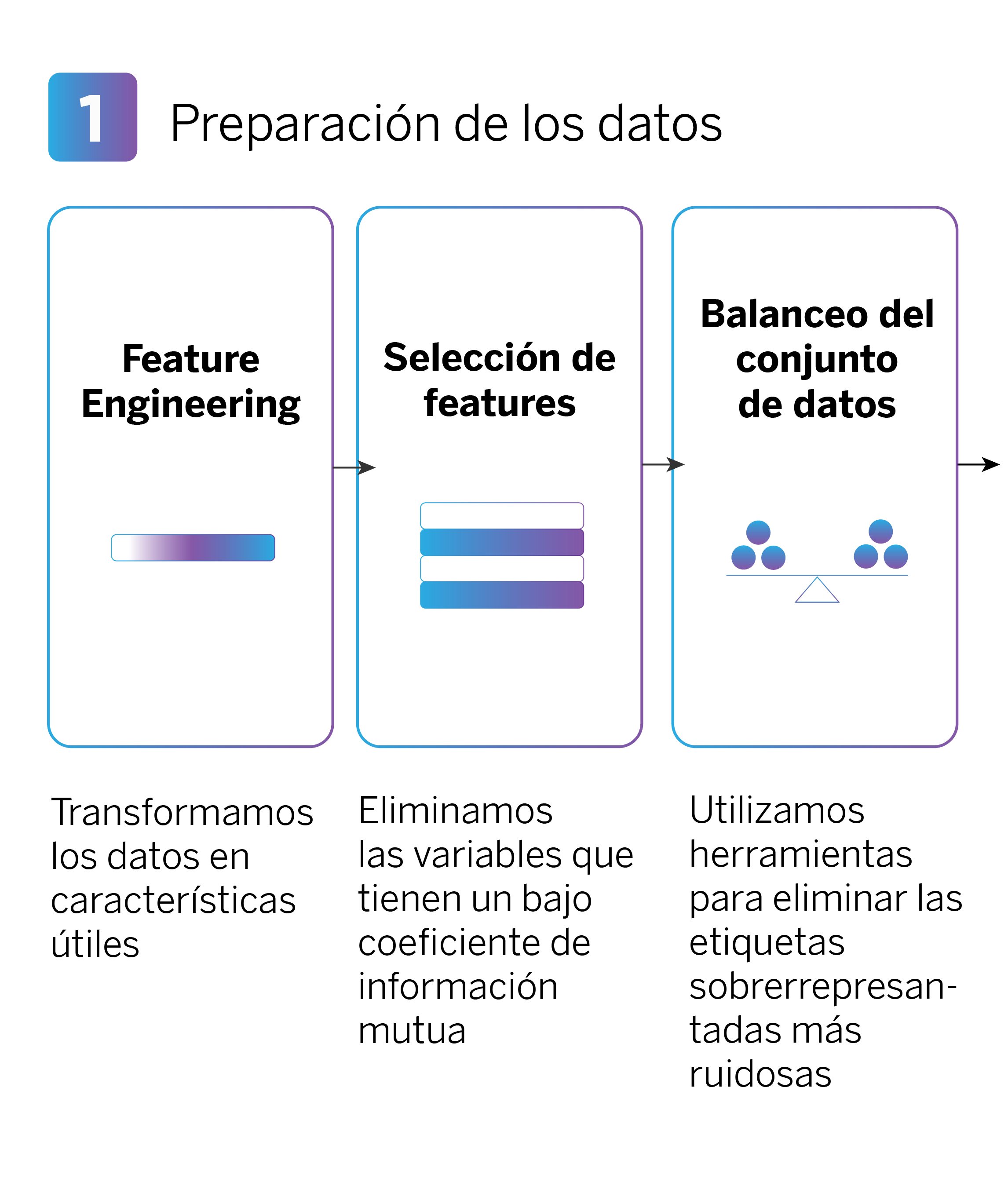
Cuando realizamos Feature Engineering, se crean muchas features (características) diferentes, las cuales no son todas útiles y/o relevantes para alimentar al modelo de IA. Reducir el número de features nos ayuda a contener el coste computacional y hacer más eficiente el entrenamiento del modelo.
En un segundo paso, el criterio para seleccionar las features se basa en lo que llamamos “información mutua”, que sería la relación que puede establecerse entre cada feature (por ejemplo, el gasto mensual en bares y restaurantes) y la variable objetivo (por ejemplo, la contratación de una cuenta de ahorro Metas). Así, eliminamos las features que tienen un bajo coeficiente de información mutua y que, por tanto, son menos relevantes para el entrenamiento del modelo.
Por último, en esta primera fase de preparación de los datos es importante realizar un balanceo del conjunto de datos, de modo que el modelo haga predicciones más precisas y equilibradas para todos los tipos de productos.
Los productos comerciales ofrecidos a través de nuestro sistema de recomendación son muy variados, desde tarjetas de crédito hasta cuentas de ahorro. El volumen de ventas varía mucho según el producto, y esto se refleja en los datos históricos que usamos para entrenar el modelo. Esto puede llevar a un “dataset desbalanceado”, donde el modelo tiende a predecir más y mejor las clases (productos) que tienen más registros. Por ejemplo, si hay muchas más contrataciones de tarjetas de débito que de cuentas de ahorro, el modelo podría predecir más frecuentemente la contratación de tarjetas de débito, ignorando las cuentas de ahorro.
Para solucionar este problema, utilizamos una librería llamada CleanLab que nos ayuda a detectar y eliminar observaciones ruidosas de las clases más representadas, consiguiendo así un dataset más balanceado.
Entrenamiento del modelo
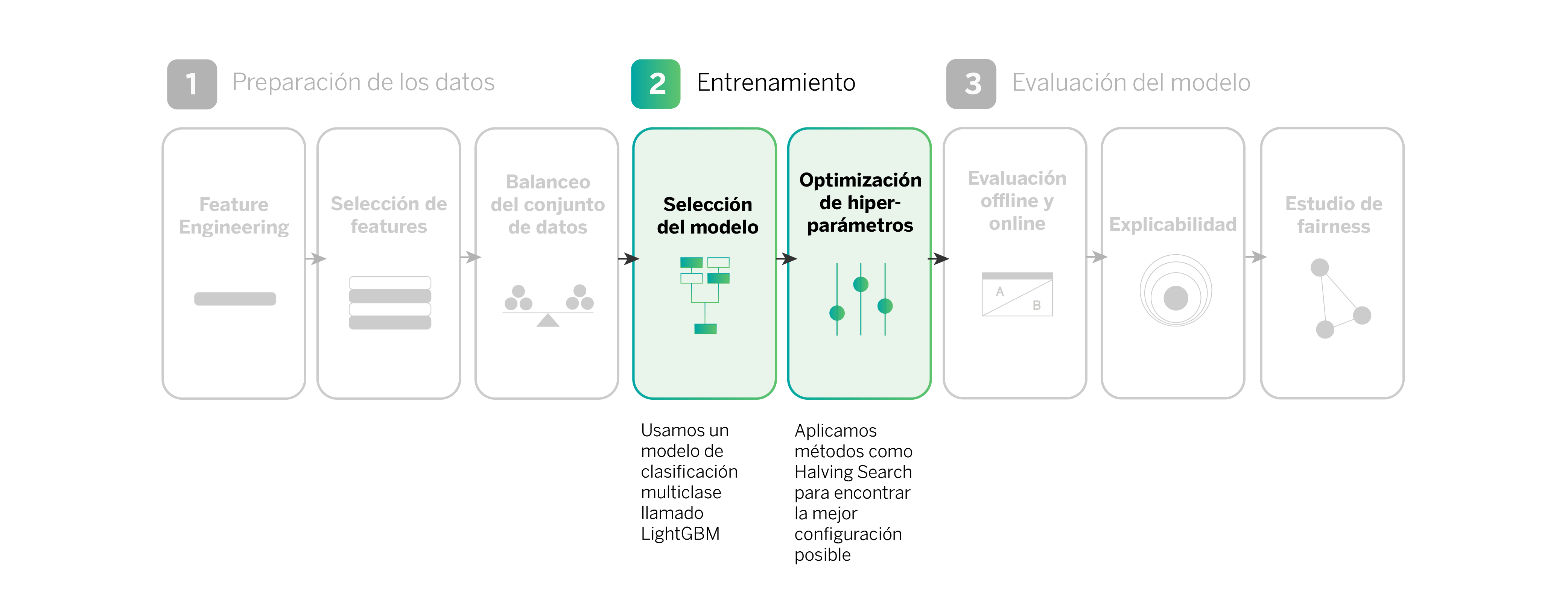
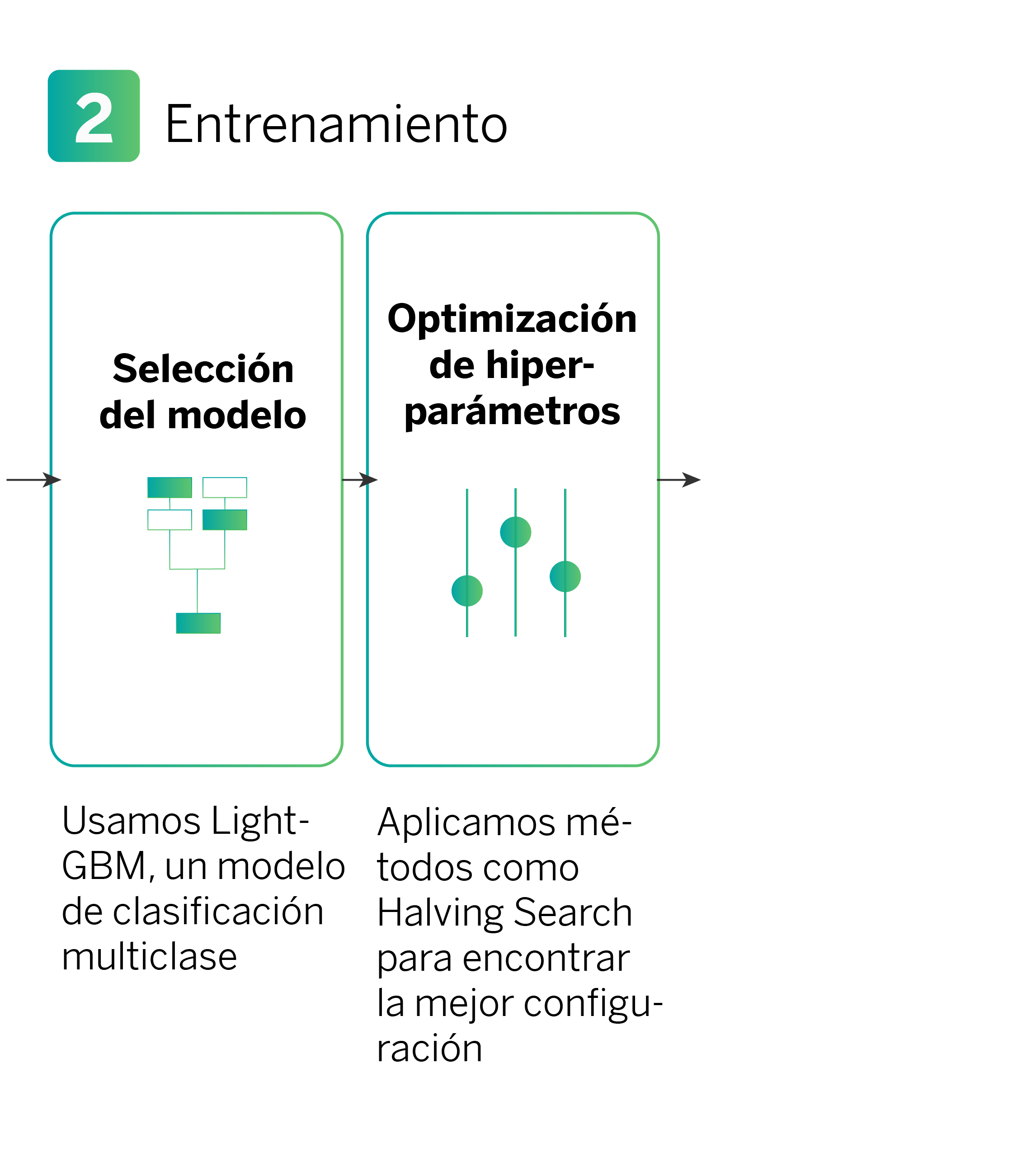
Una vez que los datos están preparados, el siguiente paso es entrenar un modelo de clasificación multiclase con los tipos de productos que un cliente podría necesitar. En este caso, usamos un algoritmo basado en modelos de árboles de decisión llamado LightGBM, que es muy eficiente para este propósito.
Durante el entrenamiento, optimizamos los hiperparámetros haciendo uso del método llamado Halving Search. Los hiperparámetros son configuraciones internas del modelo que podemos ajustar para mejorar su rendimiento (velocidad de entrenamiento) y comportamiento (precisión del modelo). Ejemplos de hiperparámetros pueden ser la tasa de aprendizaje o número de iteraciones.
El método Halving Search comienza probando muchas configuraciones diferentes con pocos recursos (el número de muestras con las que se entrena el modelo). Luego, elimina las configuraciones que no funcionan bien y concentra más muestras en las que tienen mejor desempeño. Este proceso se repite varias veces hasta que encontramos la mejor configuración posible para nuestro modelo.
Evaluación del modelo
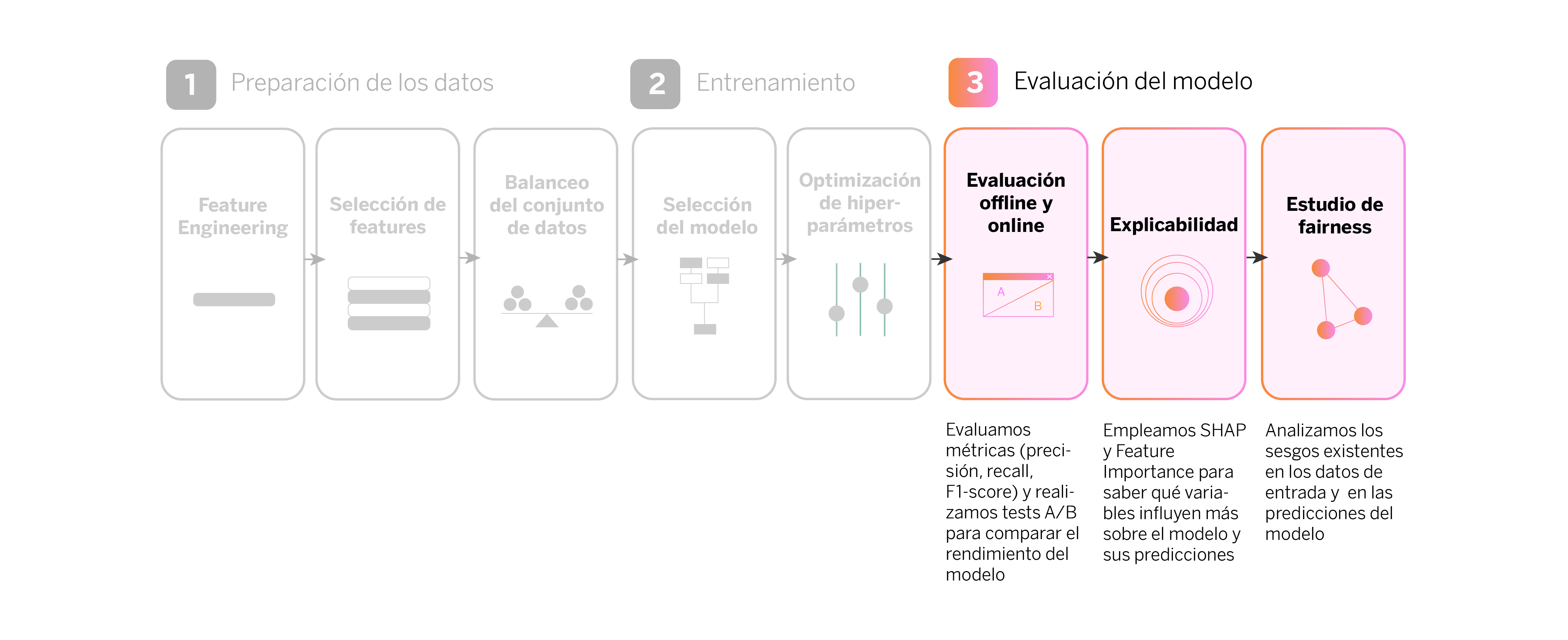
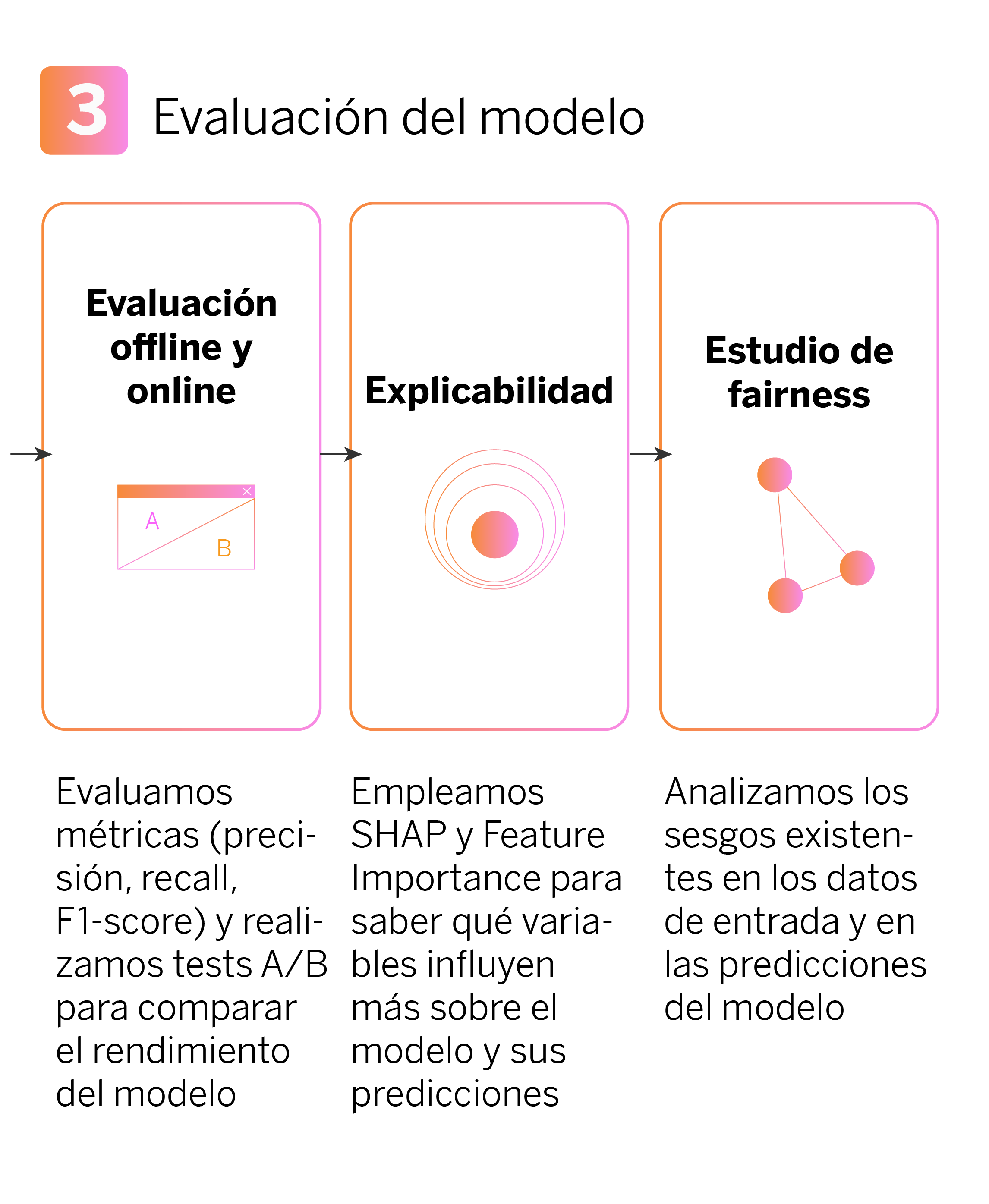
Utilizamos una serie de métricas para evaluar el rendimiento del modelo, tanto online como offline. Medimos la precisión, que nos indica cuántas de las predicciones del modelo son correctas. El recall mide cuántos casos verdaderos identifica el modelo. Para tener una visión equilibrada del rendimiento del modelo, utilizamos F1-Score, que combina precisión y recall. Estas métricas también se calculan en sus versiones ponderadas, lo que significa que consideramos la importancia relativa de diferentes clases de productos.
Además, hacemos uso de matrices de confusión. Estas matrices nos muestran en detalle cómo el modelo clasifica los productos, permitiéndonos identificar cuáles son los grupos de productos en los que el modelo tiene más errores e incluso cuáles confunde entre sí.
También aplicamos métricas de ordenación o ranking, las cuales sirven para conocer en qué medida el modelo ordena los productos de manera efectiva en sus recomendaciones. Todas estas métricas de evaluación nos ayudan a entender cómo de bien funciona el modelo y nos permiten identificar áreas donde puede necesitar ajustes.
Por otro lado, realizamos test A/B (evaluación online) para comparar diferentes versiones del modelo en producción, donde A sería un modelo y B otro diferente. Utilizando las métricas de conversión de cada versión de nuestro modelo, podemos determinar si los resultados tras actualizarlo son estadísticamente significativos. Esto nos permite validar una nueva versión del modelo siempre y cuando muestre una mejora significativa en comparación con la versión anterior.
Evaluación del modelo: explicabilidad
Uno de los objetivos principales de la fase de evaluación es que todos los equipos involucrados en el desarrollo, desde equipos técnicos a negocio, comprendamos qué variables de datos influyen a la hora de recomendar determinados productos, y de qué manera lo hacen, tanto a nivel individual como global. Para ello, utilizamos técnicas de explicabilidad:
- Feature Importance. Esta herramienta nos indica cuáles son las variables más importantes para el modelo. En otras palabras, muestra qué datos han tenido más peso a la hora de que el modelo aprenda a hacer sus predicciones. Por ejemplo, si estamos recomendando una tarjeta de crédito de empresa, la feature importance puede mostrar que el saldo en nómina o los gastos en Seguridad Social son variables muy influyentes.
- Shapley values. Los valores SHAP nos ayudan a entender el impacto de cada variable en las predicciones del modelo para cada producto. Explican de manera detallada cómo cada característica afecta la decisión del modelo. Por ejemplo, podrían mostrar cómo un aumento en el ingreso mensual de un cliente influye en la probabilidad de que se le recomiende una tarjeta de crédito.
Evaluación del modelo: estudio de equidad
Después de completar nuestro pipeline de machine learning, una pregunta clave es, ¿está el modelo reproduciendo, aumentando o disminuyendo sesgos? Para responder a esta pregunta, analizamos los sesgos existentes, tanto en los datos de entrada, como en las predicciones del modelo en función de las variables protegidas.
Las variables protegidas son características o atributos de los individuos que están protegidos por leyes o regulaciones contra la discriminación. Es importante verificar que el modelo no favorezca a ningún grupo poblacional ni cometa más errores con un grupo que con otro.
Para ello, utilizamos tres métricas de equidad o fairness:
- Paridad predictiva (Predictive Parity, PPV). Esta métrica mide la proporción de personas que han contratado lo que se les ofreció, es decir, cuando el modelo acierta.
- Igualdad predictiva (Predictive Equality, FPR). Esta métrica mide la proporción de personas que no han contratado lo que se les ofreció, es decir, cuando el modelo falla.
- Tasa de igualdad de oportunidades (Equal Opportunity Rate, FNR). Esta métrica mide la proporción de personas a las que no se les ofreció un producto que sí habrían contratado, es decir, cuando el modelo falla en identificar correctamente una oportunidad.
Estas métricas nos ayudan a asegurarnos de que el modelo funcione de manera justa y equitativa para todos los clientes, sin favorecer ni perjudicar a ningún grupo específico.
Conclusiones
Nuestro objetivo con la personalización de ofertas comerciales es responder de manera más precisa a las preguntas sobre qué producto ofrecemos, a quién, cómo y cuándo. De esta manera, podemos lanzar ofertas comerciales verdaderamente relevantes y que respondan a las necesidades individuales de nuestros clientes.
La evaluación continua y la experimentación aseguran que nuestras ofertas comerciales continúen siendo relevantes y eficaces a lo largo del tiempo, mientras que el compromiso con la transparencia y la equidad garantiza una experiencia equilibrada para todos los clientes.
Notas
- Percentage of units sold through digital channels ↩︎