
Ningún Problema Demasiado Grande; Ninguna Solución Demasiado (Computacionalmente) Pequeña
En BBVA Data & Analytics abordamos constantemente los problemas de negocio con matemáticas aplicadas, estadística o econometría. No hay problema demasiado grande; pero resulta que la solución a veces puede ser demasiado grande. Esta premisa llevó a dos de nuestros científicos de datos, Jordi Nin y Jordi Aranda, a explorar una forma de mejorar la calidad de los conocimientos que ofrece Commerce 360, una aplicación que ofrece a las pymes analizar su ecosistema de negocio y sus patrones de compra.
Lo que Nin y Aranda estaban tratando de elaborar era un sistema en el que se pudiera proporcionar la información más desagregada posible sobre negocios similares y circundantes sin violar las reglas de privacidad de ninguno de los elementos del conjunto y subconjunto. Esto habría permitido a las empresas compararse con la competencia sin violar la privacidad que todo cliente de BBVA debe haber protegido.
Nin y Aranda, han colaborado con el matemático Javier Herranz de la Universitat Politècnica de Catalunya en la búsqueda de una solución algorítmica a este problema para dotar de mayor flexibilidad al uso de los datos por parte de las pequeñas empresas, haciéndolo así mucho más significativo. “Hemos creado una hermosa y detallada formulación matemática para este problema”, explica Nin desde las soleadas oficinas de BBVA Data & Analytics en el centro de Barcelona. El enfoque consistió en dos fases: una que crea todos los subconjuntos prohibidos de negocios, porque no satisfacen, individualmente, una condición de privacidad específica. Más adelante, una fase en línea, que se ejecuta para cada nueva consulta, y valida si la información agregada solicitada puede ser liberada de forma segura, teniendo en cuenta todas las consultas anteriores aceptadas.
El problema es que con un universo tan vasto de datos de negocio y una formulación con tiempo de ejecución exponencial, comprobar individualmente las condiciones de privacidad de cada elemento de un conjunto para crear un subconjunto de consultas válidas tiene un tiempo de ejecución de O (2n). Así que el tamaño del subconjunto que define las condiciones de privacidad hará que los tiempos de procesamiento sean casi imposibles de manejar a menos que la computación cuántica se convierta en una realidad.
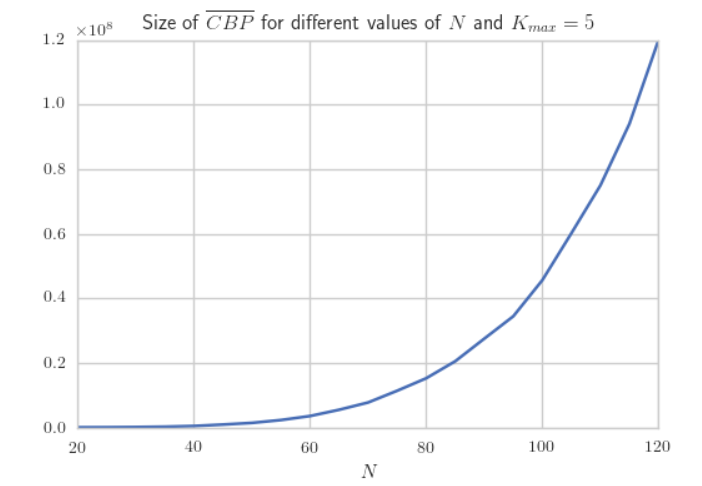
Lo que el científico encontró es que para prevenir la información no agregada de las compañías como lo requieren las leyes de privacidad y al mismo tiempo permitir una búsqueda fina sobre la competencia es casi un problema de NP para el universo de datos que estamos usando, por lo tanto necesitando un tiempo de procesamiento computacional tan enorme que no es factible hoy en día.
“Compartir información agregada de manera privada es un problema importante y desafiante en productos y aplicaciones basados en datos. Aunque es posible aumentar el rendimiento de los algoritmos propuestos, en un futuro próximo nos gustaría estudiar formas alternativas de reducir el coste de cálculo de la lista de subconjuntos prohibidos”, dice Nin.
La conclusión de este trabajo experimental sobre cómo abordar problemas computacionales extremadamente desafiantes está siendo publicada después del proceso de revisión por pares en Proceedings of COMPSAC 2018 y será presentada este mes de julio en Tokio (Japón) durante la 42ª conferencia del IEEE sobre Informática, Software y Aplicaciones.