
Mercury-Robust: así garantizamos la fiabilidad de nuestros modelos de ML
Cada vez se hace más patente la necesidad de garantizar la robustez de modelos de Machine Learning (aprendizaje automático), así como su correcta monitorización una vez estos se despliegan en entornos productivos. Por esto, es recomendable incorporar elementos analíticos que nos ayuden a evaluar nuestros modelos para medir su funcionamiento y fiabilidad.
Esta necesidad es proporcional a la madurez de las compañías en lo que a desarrollo de soluciones basadas en Machine Learning refiere, pero también al impacto que dichas soluciones puedan tener en la vida de las personas. En BBVA AI Factory creamos soluciones que pasan a formar parte de los entornos productivos del banco, las cuales luego se implementan en casos de uso reales. Por esta razón, debemos ser rigurosos y precavidos para prevenir cualquier circunstancia que pueda afectar al desempeño de los modelos.
Como nuestros modelos operan en la vida real, no es suficiente con desarrollarlos como se hace en el ámbito académico, donde los entornos son controlados y los datos no son realistas; aquí hay que prepararlos ante contingencias. Por ello, el interés por implementar técnicas que midan y optimicen el funcionamiento de modelos de Machine Learning ha crecido a la par que muchas de las herramientas de MLOps en el mercado.
¿Qué es Machine Learning Operations (MLOps)?
MLOps es un conjunto de prácticas y herramientas que se utilizan para gestionar y automatizar el ciclo de vida de los modelos de Machine Learning, desde su fase de entrenamiento hasta su entrada en producción. Se enfoca en mejorar la eficiencia, la escalabilidad y la fiabilidad de los modelos en entornos productivos para asegurar que estén en línea con los objetivos de negocio, así como para facilitar su integración con otros sistemas.
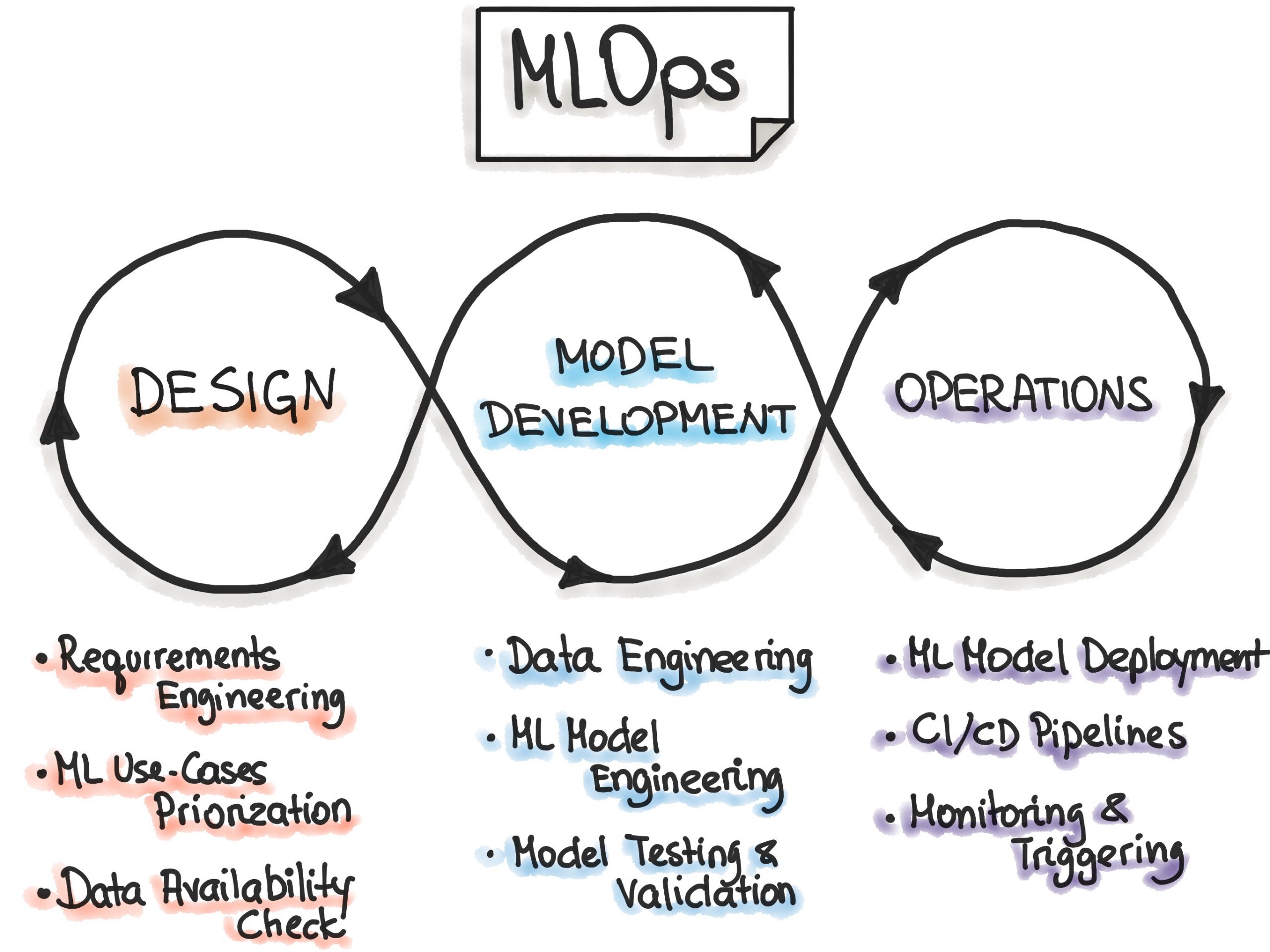
Si bien en muchos casos se asocia con una práctica metodológica, este término se emplea para dar nombre a las herramientas que soportan la infraestructura del desarrollo de modelos de Machine Learning. Se trata de un ámbito muy destacado en la actualidad y se considera crítico para obtener valor de negocio a partir de productos basados en datos y para garantizar su correcta operatividad.
Comercialmente, existen múltiples soluciones de MLOps creadas por proveedores de plataformas de datos y servicios Cloud, como lo son SageMaker MLOps de AWS, VertexAI de Google Cloud Platform y Azure Machine Learning.
Aunque MLOps comprende otros elementos, la monitorización y robustez son aspectos esenciales contenidos en esta suite de herramientas. Por un lado, la monitorización hace referencia a la capacidad de supervisar el rendimiento del modelo en tiempo real y detectar rápidamente cualquier problema que pueda surgir, como puede ser el drift (cambios en la distribución) en los datos de entrada.
Por otro lado, la robustez se refiere a la capacidad de los modelos de Machine Learning para mantener un alto nivel de rendimiento en condiciones adversas o inesperadas, como la aparición de nuevos datos que no se habían visto durante el entrenamiento.
Mercury-robust: Un framework para testear la robustez de modelos de ML en BBVA
En el ámbito industrial, es necesario asegurar que al desplegar un modelo de Machine Learning ya entrenado éste se comporte adecuadamente en el mundo real. Para ello, hay que dotarlo con una fuerte capacidad de resistencia ante situaciones adversas y cambios en su entorno. Además, es fundamental asegurar que futuras actualizaciones del modelo no añadan posibles puntos de fallo en el sistema, lo que podría poner en riesgo su fiabilidad y rendimiento.
Para atajar estas cuestiones, mercury-robust nació como un framework dentro de la librería de ciencia de datos de BBVA, Mercury. Fue diseñado para realizar pruebas sobre modelos y/o conjuntos de datos, y está inspirado en tests unitarios de software tradicionales.
Cuando alguna de las pruebas falla levanta una excepción, la cual es gestionada siempre a discreción del usuario final. Además, ofrece una serie de casos de prueba predefinidos y configurables, los cuales ayudan a garantizar la robustez de los pipelines de aprendizaje automático. Por ejemplo, puede verificar rápidamente si un modelo está discriminando a un colectivo o comprobar si al reentrenar un modelo con los mismos datos se obtienen las mismas predicciones.
Mercury-robust se ha revelado como un componente analítico realmente útil en nuestro día a día, por lo que ahora se encuentra disponible como open-source. De esta forma, facilitamos que su utilización se extienda entre una comunidad más amplia, lo cual también incidirá eventualmente en el crecimiento de sus funcionalidades.
A alto nivel, mercury-robust está dividido en dos tipos de componentes: Model Test y Data Test, en función de si involucran un modelo o solo los datos, respectivamente.
Data Test
| Same schema → |  |
Asegura que un DataFrame tiene las mismas columnas y tipos de features que los especificados en el DataSchema. |
| Data Drift → |  |
Verifica que las distribuciones de features individuales no hayan cambiado significativamente entre un DataSchema de referencia y un pandas.DataFrame. |
| Linear Combinations → |  |
Comprueba que no tiene columnas redundantes o innecesarias en su pandas.DataFrame. |
| No Duplicates → |  |
Verifica que no tenga muestras repetidas en su conjunto de datos, lo que puede agregar sesgo a sus métricas de rendimiento. |
| Sample Leaking → |  |
Comprueba si el dataset de test o validación contiene muestras que ya están incluidas en el dataset de entrenamiento. |
| Label Leaking → |  |
Verifica que no tenga ninguna feature que filtre información sobre la variable objetivo. |
| Noisy Labels → |  |
Verifica que las etiquetas de un conjunto de datos tengan una calidad mínima. Consideramos etiquetas de baja calidad cuando tenemos un alto número de muestras etiquetadas incorrectamente o cuando la separación entre etiquetas no es evidente. |
| Cohort Performance → |  |
Comprueba si una métrica especificada resulta peor para un grupo concreto de tus datos. Por ejemplo, se puede configurar para que compruebe si la precisión de un modelo es más baja en un género respecto el otro. |
Data Test
Same schema →
Asegura que un DataFrame tiene las mismas columnas y tipos de features que los especificados en el DataSchema.
Data Drift →
Verifica que las distribuciones de features individuales no hayan cambiado significativamente entre un DataSchema de referencia y un pandas.DataFrame.
Linear Combinations →
Comprueba que no tiene columnas redundantes o innecesarias en su pandas.DataFrame.
No Duplicates →
Verifica que no tenga muestras repetidas en su conjunto de datos, lo que puede agregar sesgo a sus métricas de rendimiento.
Sample Leaking →
Comprueba si el dataset de test o validación contiene muestras que ya están incluidas en el dataset de entrenamiento.
Label Leaking →
Verifica que no tenga ninguna feature que filtre información sobre la variable objetivo.
Noisy Labels →
Verifica que las etiquetas de un conjunto de datos tengan una calidad mínima. Consideramos etiquetas de baja calidad cuando tenemos un alto número de muestras etiquetadas incorrectamente o cuando la separación entre etiquetas no es evidente.
Cohort Performance →
Comprueba si una métrica especificada resulta peor para un grupo concreto de tus datos. Por ejemplo, se puede configurar para que compruebe si la precisión de un modelo es más baja en un género respecto el otro.
Model Test
| Model Reproducibility → |  |
Entrena un modelo dos veces y verifica que las predicciones (o una cierta métrica) de las dos versiones no sean demasiado diferentes. |
| Feature Checker → |  |
Estima la importancia de las features y vuelve a entrenar su modelo eliminando las menos importantes una a una. |
| Tree Coverage → |  |
Test que funciona solo con modelos basados en árboles (principalmente los de scikit-learn). Comprueba que, una vez que se tiene un modelo entrenado, dado un conjunto de datos de prueba, las muestras “activan” una cantidad mínima de ramas en su(s) árbol(es). |
| Model Simplicity → |  |
Compara el rendimiento de su modelo con una línea de base más simple (por defecto, un modelo lineal, aunque puede especificar su propia línea de base). |
| Classification Invariance → |  |
Este test mira que cuando se aplica una perturbación que no debería de impactar en la etiqueta de los samples, el modelo ciertamente no se ve afectado y no cambia su predicción. |
| Drift Resistance → |  |
Comprueba la resistencia de un modelo a drift en los datos. |
Model Test
Model Reproducibility →
Entrena un modelo dos veces y verifica que las predicciones (o una cierta métrica) de las dos versiones no sean demasiado diferentes.
Feature Checker →
Estima la importancia de las features y vuelve a entrenar su modelo eliminando las menos importantes una a una.
Tree Coverage →
Test que funciona solo con modelos basados en árboles (principalmente los de scikit-learn). Comprueba que, una vez que se tiene un modelo entrenado, dado un conjunto de datos de prueba, las muestras “activan” una cantidad mínima de ramas en su(s) árbol(es).
Model Simplicity →
Compara el rendimiento de su modelo con una línea de base más simple (por defecto, un modelo lineal, aunque puede especificar su propia línea de base).
Classification Invariance →
Este test mira que cuando se aplica una perturbación que no debería de impactar en la etiqueta de los samples, el modelo ciertamente no se ve afectado y no cambia su predicción.
Drift Resistance →
Comprueba la resistencia de un modelo a drift en los datos.
¡Manos a la obra!
Si quieres empezar a usar el framework de mercury-robust, sólo tienes que visitar la documentación, el repositorio que tenemos abierto en Github e instalar el paquete desde Pypi.
pip install mercury-robustDe manera general, podemos utilizar este framework en dos pasos:
- Creamos los tests que deseamos ejecutar
- Creamos una test suite con estos tests y la ejecutamos.
A continuación, podemos ver un ejemplo:
from mercury.robust.data_tests import LinearCombinationsTest, LabelLeakingTest
from mercury.robust import TestSuite
# Create tests
linear_combinations = LinearCombinationsTest(df[features], dataset_schema=schema)
label_leaking = LabelLeakingTest(
df,
label_name = label,
dataset_schema=schema,
)
# Create Test Suite
test_suite = TestSuite(tests=[linear_combinations, label_leaking])
test_results = test_suite.run()
test_suite.get_results_as_df()Resultado:
| name | state | error | |
| 0 | LinearCombinationsTest | TestStateSUCCESS | |
| 1 | LabelLeakingTest | TestState.FAIL | Test failed because high importance features were detected: [‘WARNING_SENT’]. Check for possible target leaking. |
| name | state | error | |
| 0 | LinearCombinationsTest | TestStateSUCCESS | |
| 1 | LabelLeakingTest | TestState.FAIL | Test failed because high importance features were detected: [‘WARNING_SENT’]. Check for possible target leaking. |
Vemos que tras ejecutar la test suite, podemos localizar fácilmente qué tests han fallado y cuál es el motivo. En este caso, uno de los tests falla debido a que nuestro dataset contiene una variable con posible “leaking” respecto el target.
Conclusiones
En resumen, este framework proporciona herramientas que permiten garantizar un alto estándar de calidad en los modelos y facilitar su auditoría interna. Gracias a sus funcionalidades, se han detectado sesgos en la métrica de rendimiento por subgrupos en variables sensibles, se ha prevenido el data drift y se han detectado errores en las etiquetas asignadas por expertos que posteriormente se utilizan para modelos de ML.