
Mercury: acelerando la reutilización en ciencia de datos dentro de BBVA
El desarrollo de productos basados en Inteligencia Artificial requiere de una considerable cantidad de tiempo dedicado a diseñar, implementar y probar algoritmos sobre datos. En una gran organización como BBVA, con más de 700 científicos de datos, es común encontrar diferentes equipos desarrollando soluciones de software similares. En muchas ocasiones, aunque se trata de casos de uso diferentes, algunos de los componentes o assets utilizados son muy parecidos, lo que genera trabajo duplicado y, por tanto, pérdida de tiempo y recursos.
Desde BBVA AI Factory estamos contribuyendo a solucionar este problema con Mercury, una librería de código interna con la que buscamos aplicar los principios del Open Source dentro de BBVA. Además de perseguir el objetivo principal de facilitar la reutilización de componentes de código a gran escala, acelerando el desarrollo de los proyectos, el concepto inner-source1 también nos aporta otras ventajas.
Por un lado, conseguimos afianzar una fuerte cultura de comunidad al facilitar la compartición de ideas y conocimiento. El hecho de trabajar en comunidad fomenta el crecimiento profesional, al contribuir componentes que tendrán impacto a una escala mayor, al mismo tiempo que permite estar al tanto de las soluciones que otros equipos están desarrollando. Por otro lado, la calidad del código mejora notablemente, ya que más gente puede verlo, comentarlo, documentarlo y mejorarlo. Como afirma la Ley de Linus: “given enough eyeballs, all bugs are shallow“2. Además, somos capaces de proponer más casos de uso, ya que los equipos tienen componentes a su disposición que se pueden utilizar para resolver diferentes problemas de negocio.
El nacimiento de Mercury
Mercury nace con vocación de ser una herramienta eficaz para contribuir y consumir componentes de código entre equipos y desarrolladores. Esta idea se materializó en la creación de una librería de Python, llamada Mercury, en la que se incluyeron los algoritmos comunes a varios equipos, además de aquellos que tenían potencial de ser reutilizados en un futuro.
Para ser realmente útil y facilitar el desarrollo de los proyectos, se estableció desde un primer momento como librería de uso voluntario y abierta a toda la comunidad de BBVA AI Factory: cualquier persona puede ver, modificar y contribuir los cambios que considere útiles para el resto.
Otro requisito importante es que no debía contener funcionalidades ya presentes en otras librerías mainstream. Si algo existe en Mercury es porque es nuevo o tiene claras ventajas sobre otros componentes ya existentes. Además, se trata de componentes siempre asépticos a casos de negocio concretos, pero sí deben estar preparados para ser productivos y funcionales, por lo que es necesario asegurar una alta calidad de código.
Por último, activamos palancas como la realización de tutoriales y la generación de una buena documentación para facilitar el descubrimiento y adopción de las funcionalidades por parte de los usuarios.
Ese proyecto con pocas funcionalidades, semilla del actual Mercury, comenzó a crecer rápidamente en el ámbito de BBVA AI Factory. Los científicos de datos empezaron a reutilizar componentes dentro de sus proyectos y a contribuir con nuevas ideas de vuelta, creándose un sentimiento de comunidad que perdura hasta el día de hoy.
Crecimiento a todo BBVA
Tras el buen crecimiento interno experimentado durante los dos primeros años, decidimos abrir Mercury a toda la comunidad de analítica avanzada de BBVA, de modo que este mismo efecto pudiera repetirse en un ámbito mucho más amplio, llegando a más países y áreas del banco. Es el caso de México, Perú, Argentina o Colombia, entre otros, y áreas como Finanzas, Talento y Cultura o Banca de Inversión (Corporate & Investment Banking). De esta manera cada vez más científicos de datos empezamos a participar en Mercury, reutilizando componentes y contribuyendo con otros nuevos desde ámbitos y contextos muy diferentes.
Tras el despliegue de la librería dentro de BBVA, llegaron nuevas sinergias con otros programas o líneas de desarrollo. Algunos ejemplos son los X-Program, proyectos de experimentación e innovación con datos de los que surgieron interesantes componentes disponibles para la comunidad de Mercury y que actualmente están siendo reutilizados por diferentes programas.
Sobre la librería Mercury
A día de hoy la librería se ha convertido en un proyecto muy grande (+300K líneas de código) con un gran número de funcionalidades de diferentes dominios. Debido a esta casuística, desde el principio fue diseñada para que fuera modular, es decir, que sus usuarios puedan instalar solamente las partes de la librería que necesitan. Mercury se divide en varios micro-paquetes, que se pueden usar de manera independiente:
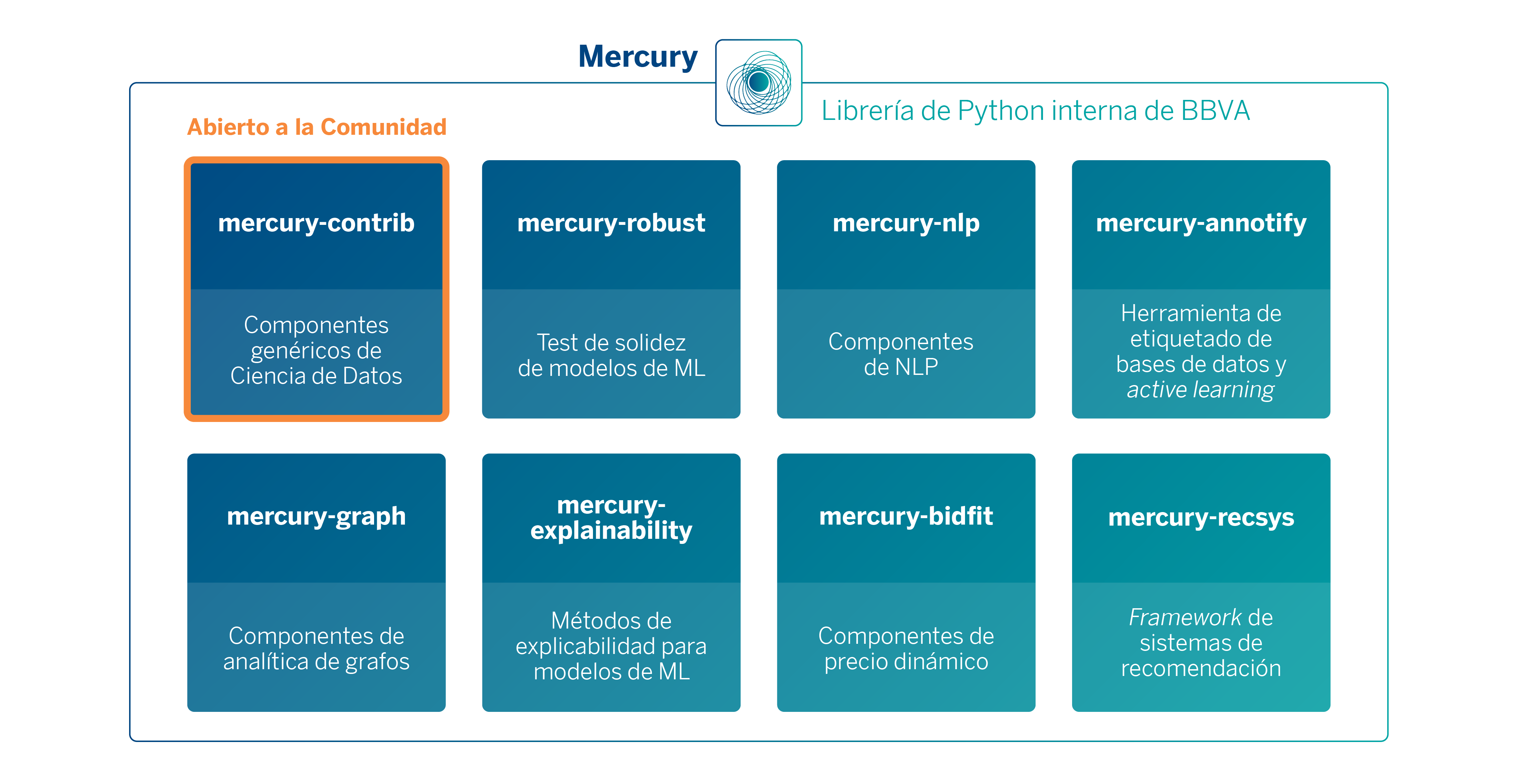
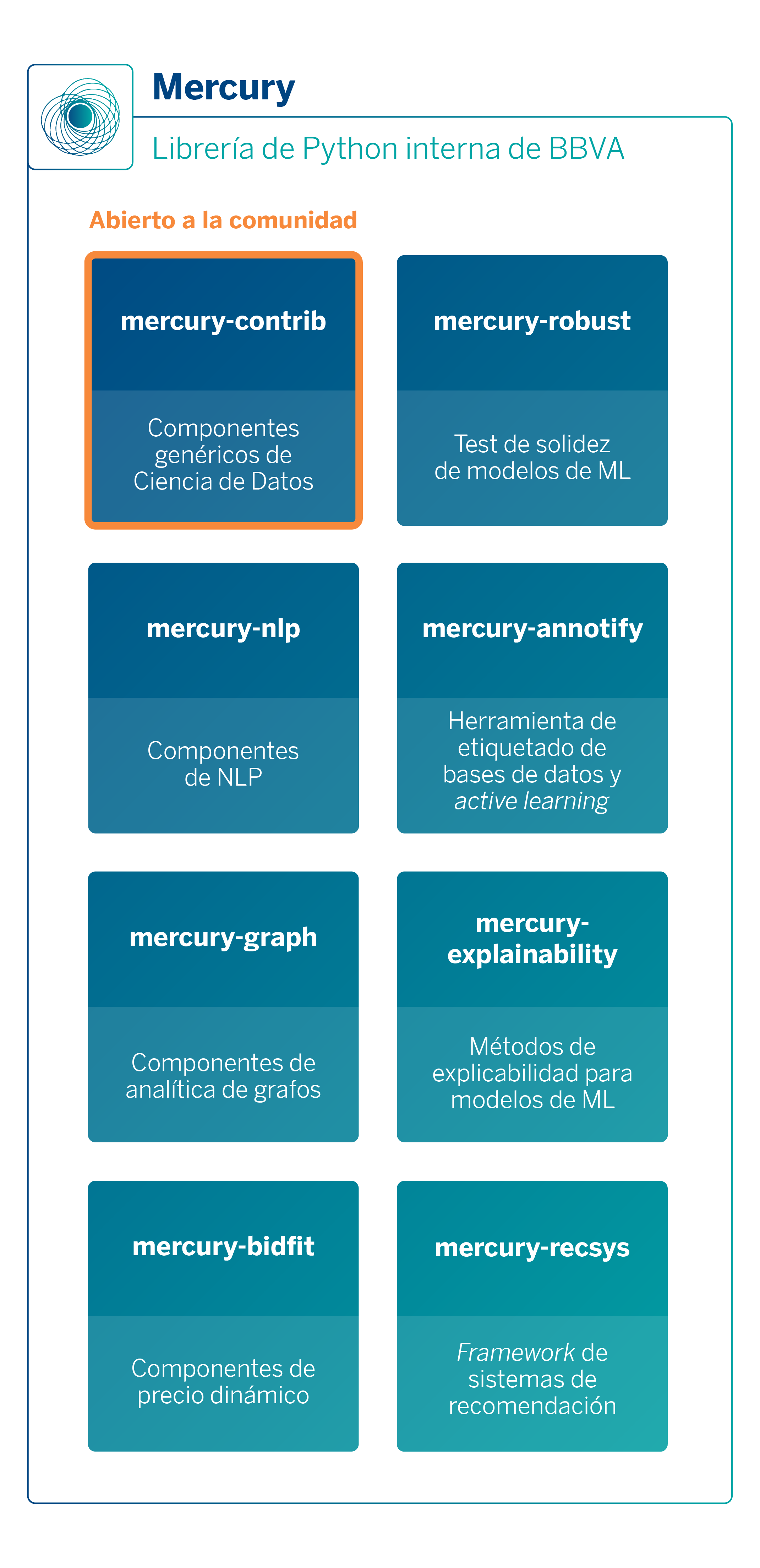
Algunos ejemplos de piezas que pueden encontrarse en cada uno de los paquetes de Mercury son, por ejemplo, una implementación de los Extended Trees (mercury-contrib), algoritmos para calcular embeddings en grafos a gran escala (mercury-graph3), métodos de explicabilidad de modelos (mercury-explainability), diversos algoritmos de optimización de hiperparámetros avanzados (mercury-contrib), algoritmos propios de detección de drift (mercury-contrib), un framework de ML robust-testing (mercury-robust) para asegurar la calidad de modelos y datos o un framework de precio dinámico basado en RL (mercury-bidfit).
Cada uno de los micro-paquetes tiene un ciclo de vida separado del resto, con su propia batería de tests, su propio CI (ciclo de integración contínua) y su propio artefacto.
Debido a que estos componentes son utilizados en procesos productivos con impacto en diversas áreas de negocio, es muy importante poder asegurar unos estándares de calidad altos, comparables a los que se usan en las principales librerías de Machine Learning, como scikit-learn, Tensorflow o PyTorch, entre otras. Esto es, cobertura de tests alta (~90%) además de pruebas de integración para asegurar que la librería funcionará correctamente en la plataforma de datos interna del banco. Mercury cuenta con un equipo dedicado a su desarrollo y mantenimiento, compuesto por científicos de datos e ingenieros de ML.
Con todo este ciclo de vida se intenta mantener una alta cadencia. Se genera una release de la librería completa cada mes, de modo que los usuarios puedan acceder a las últimas novedades lo más rápido posible y seguir apoyándose en Mercury para realizar sus desarrollos.
Algunas lecciones aprendidas
Una de las claves del éxito de este tipo de proyectos inspirados en las ideas del Open Source es el conseguir crear, hacer crecer y mantener una comunidad que utilice y contribuya al proyecto. Para alcanzar este objetivo es necesario definir una estructura organizativa clara, que en el caso de Mercury incorpora tres tipos de roles, con diferentes grados de responsabilidad sobre el proyecto:
 Equipo Core Equipo Core |
 Contribuidores Contribuidores |
 Comunidad Comunidad |
|---|
|
|
|
|
|---|---|---|---|
| Equipo Core | Contribuidores | Comunidad | |
| Usar la librería |  |
|
|
| Divulgación | |
|
|
| Contribuir ideas o algoritmos | |
|
|
| Mejorar tutoriales o documentación | |
|
|
| Gestionar contribuciones | |
||
| Mantenimiento | |
Aprender a manejar una librería nueva puede ser una carga bastante grande para los usuarios. En este punto, las dinámicas de divulgación y comunicación son críticas para extender su uso e intentar neutralizar las posibles reticencias. Es por esto que uno de los focos principales en el proyecto es el realizar diversas actividades de comunicación como pueden ser newsletters, habilitar canales de chat, workshops, hackathones o meetups.
El principal modo de aprendizaje de una librería de software es su propia documentación y ejemplos de uso. Para nosotros es crucial que exista una documentación exhaustiva para cada componente que se añade, así como tutoriales de uso que generamos y distribuimos en forma de notebook (más de 200 hasta la fecha). Todo esto es incluido en nuestros ciclos de release, donde se generan regularmente páginas de documentación al estilo de las que se pueden encontrar en otras conocidas librerías.
Dado el tamaño de BBVA, tener un sistema de gobierno y revisión adecuado nos permite asegurar que tanto los contribuidores potenciales como los habituales puedan añadir sus piezas a la librería.
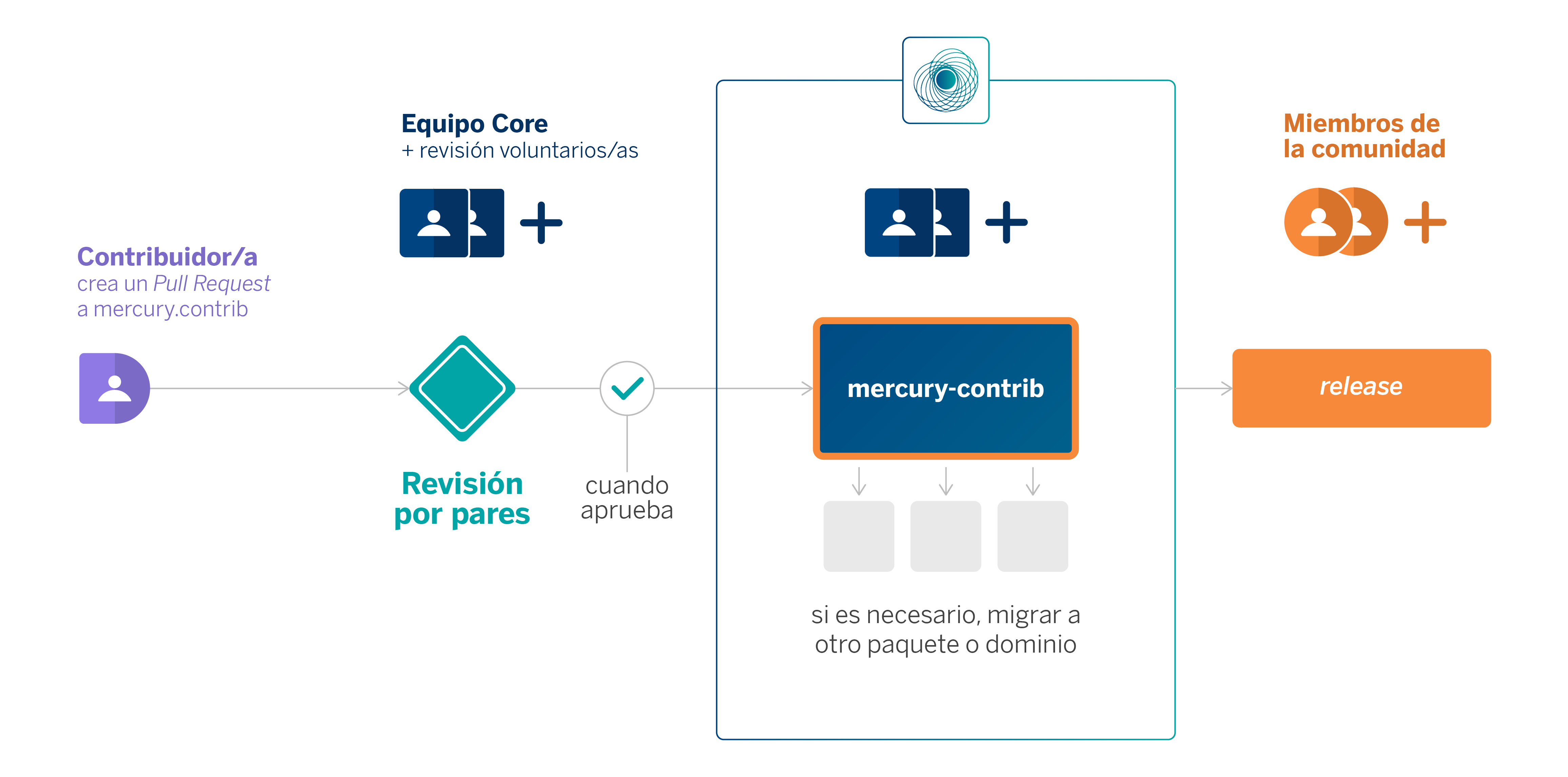
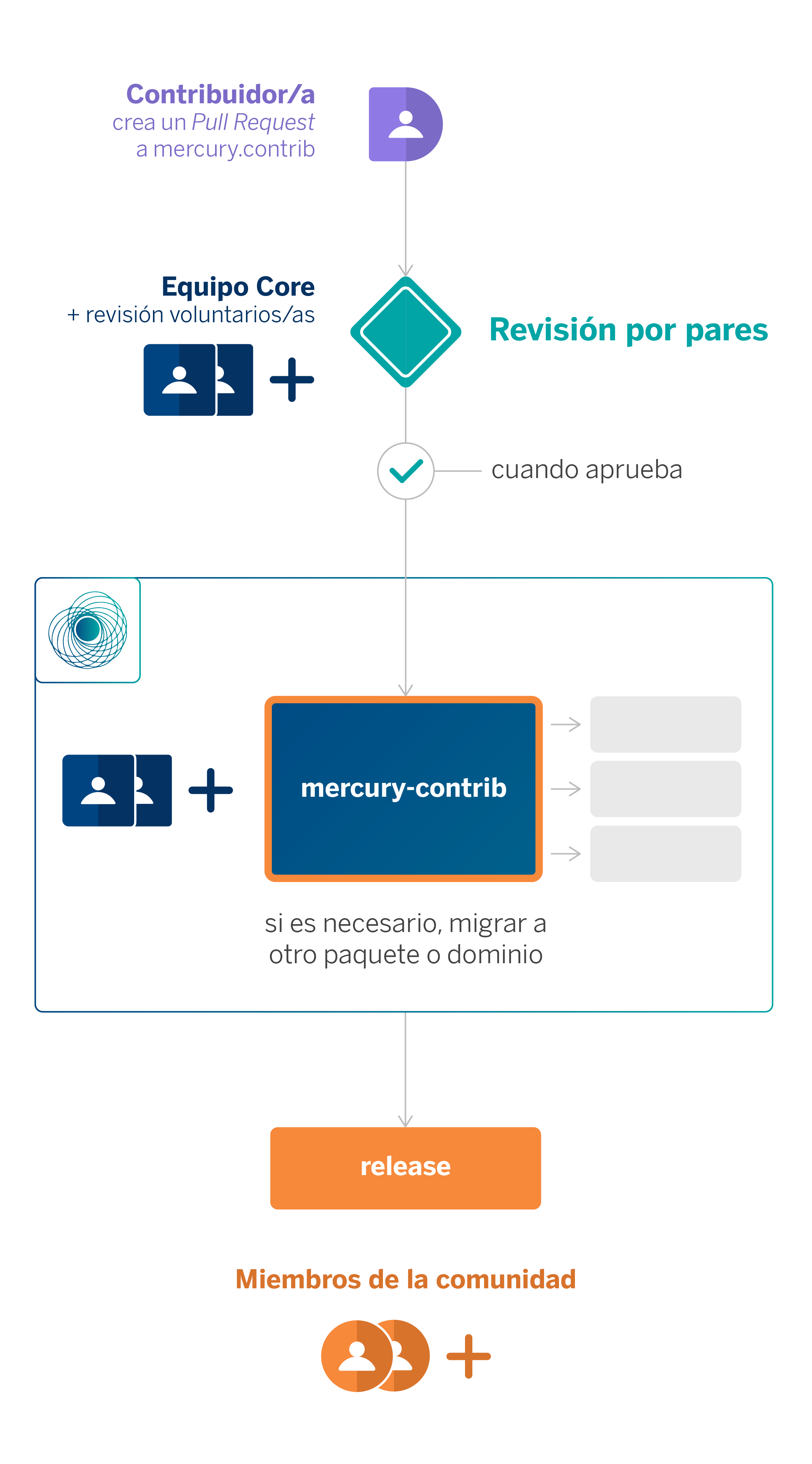
Como ya hemos mencionado, el ciclo de contribución está totalmente abierto a cualquier persona. Generalmente, se comienza abriendo una Pull Request (PR) al repositorio de mercury.contrib, punto central de la contribución en Mercury. A partir de aquí se abre un proceso de revisión en el que el equipo mantenedor y, opcionalmente, otros voluntarios, revisan y sugieren cambios con el objetivo de mejorar al máximo el código que se pretende contribuir. Cuando se obtiene un mínimo de dos aprobaciones, la contribución puede ser incluida dentro de mercury.contrib automáticamente.
Adicionalmente, si la contribución tiene un mejor encaje en un dominio concreto (p.e. si está relacionada con tratamiento grafos, tiene más sentido que se encuentre dentro de mercury.graph), el equipo de Mercury la migrará al paquete en el que mejor encaje tenga.
Acortando el time-to-value y acelerando nuevos proyectos
Mercury es el proyecto de referencia en la adopción del InnerSource en BBVA. Hacia afuera, InnerSource Commons es la mayor comunidad de la práctica de InnerSource en el mundo. En ella podemos encontrar algunas historias de éxito de muchas compañías de diferentes sectores, cada una de ellas con sus particularidades. Cuando analizamos nuestra propia historia, uno de los aspectos más diferenciadores que encontramos son los KPIs propios que utilizamos.
En proyectos InnerSource, es bastante habitual medir la actividad de código en los repositorios asociados, ya sea el volumen de Pull Request, commits, contribuidores, etc. Es decir, métricas que se pueden obtener fácilmente mediante el servicio de control de versiones, como Bitbucket o Github, entre otros. En el caso de Mercury, no obstante, ponemos el foco en el uso. Esto quiere decir que lo que más nos importa es medir cuántos usuarios instalan y utilizan la librería en casos de uso reales, aunque no contribuyan de vuelta con código nuevo. La métrica que nos mueve es un import mercury.* y no tanto un git commit / push.
Con este nuevo enfoque en torno al uso, la implantación de una librería de ciencia de datos cross-domain como Mercury contribuye a reducir el time-to-value (tiempo dedicado para la obtención de valor), acelerar el desarrollo de nuevos proyectos, hacer más eficiente el mantenimiento y compartir conocimiento.
A día de hoy el crecimiento de la comunidad de usuarios de Mercury es sólido. Tanto que lo usan ya más de una tercera parte de los casos de uso más relevantes del banco en analítica avanzada, cifra que esperamos doblar en 2023. Entre ellos, podemos detectar nuevos patrones de blanqueo de dinero utilizando componentes de mercury-graph, implementar sistemas de recomendación con mercury-recsys o acelerar el proceso de etiquetado que nos permite mostrar a los clientes nuevas categorías de gasto en la app de BBVA, gracias a mercury-annotify. Sin lugar a dudas la librería tiene un prometedor futuro por delante.
Referencias
- Una introducción a InnerSource – GitHub Resources. ↩︎
- Ley de Linus. ↩︎
- Lanzamiento en BBVA AI Factory de un software interno para el análisis de relaciones, semilla del actual componente mercury-graph de Mercury. ↩︎