
Grandes modelos de lenguaje más allá del diálogo
El término más buscado en Google en España durante el 2023 fue “ChatGPT”. Su lanzamiento representó un cambio de paradigma en cómo interactuamos con la tecnología, permitiéndonos comunicarnos en lenguaje natural con las máquinas.
Estos asistentes conversacionales son capaces de proporcionar ideas y conocimiento relevante (aunque es importante contrastar siempre su precisión). Una de sus principales virtudes reside en su habilidad para entender el contexto de la conversación y adaptarse a las instrucciones que le damos. Todo esto es posible gracias a los grandes modelos de lenguaje (Large Language Models, LLM por sus siglas en inglés), una rama de la inteligencia artificial que opera dentro del dominio del aprendizaje profundo.
Pero estos grandes modelos de lenguaje se pueden utilizar más allá de su uso para chat. En BBVA AI Factory, nuestro trabajo de exploración con estos modelos ha revelado nuevas aplicaciones que pueden beneficiar a diversas áreas, entre ellas la ciencia de datos. En este artículo, os contamos algunos desafíos que estos modelos nos están ayudando a superar.
¿Qué son los grandes modelos de lenguaje (LLM)?
Imaginemos un bibliotecario que nunca ha tenido contacto con el mundo exterior, pero que ha obtenido conocimiento de diversas fuentes dentro de una biblioteca que contiene todo el saber generado por la humanidad. Ha aprendido los patrones del lenguaje, la gramática y el contexto necesarios para entablar una conversación eficazmente.
Así como este ermitaño bibliotecario, los LLM han sido entrenados con toda la información necesaria para simular una interacción humana. La principal diferencia radica en que el bibliotecario, a pesar de su aislamiento, es un ser humano y puede articular sus respuestas mediante su razonamiento.
Los LLM, en cambio, predicen el texto que generan a partir de lo que es más probable, en coherencia con lo que les pidamos, y cuentan con la habilidad de sintetizar información de múltiples fuentes para dar una respuesta coherente y relevante.
Además de generar lenguaje, podemos entrenar y/o utilizar a los LLM para realizar otro tipo de tareas.
Diferentes aplicaciones de LLM
Reducir el tiempo dedicado al etiquetado de datos
Como científicos de datos, entre nuestras labores está el entrenar modelos de aprendizaje automático. Este trabajo implica una preparación meticulosa de los datos de entrenamiento. Cuando afrontamos problemas de clasificación supervisados requerimos que dichos datos estén etiquetados. Estas etiquetas clasifican la información y son las que sirven al modelo para tomar decisiones.
La calidad y consistencia de las etiquetas son fundamentales para el desarrollo de los modelos. Tradicionalmente, el etiquetado ha sido un trabajo manual donde anotadores humanos disciernen qué datos pertenecen a una categoría u otra. Este es un trabajo tedioso que puede verse afectado por el factor subjetivo que implica, por lo que la consistencia del etiquetado puede mermar, especialmente cuando los datos a etiquetar no son estructurados.
Esta tarea se puede agilizar de múltiples formas siempre con supervisión humana. Una forma novedosa de hacerlo es utilizando los LLM, los cuales pueden reconocer y etiquetar automáticamente categorías específicas en grandes conjuntos de texto. Dado que estos modelos han sido entrenados con un vasto corpus de datos textuales, pueden comprender la complejidad de dichos textos, siendo incluso capaces de contextualizarlos tal como lo haría una persona, e incluso reducir los errores humanos.
Para utilizar un LLM en el etiquetado automático, es esencial redactar un ‘prompt’1 claro y detallado que defina las categorías a etiquetar, al que podemos proporcionarle ejemplos y directrices concretas. Por ejemplo, en qué contexto y con qué finalidad se están anotando los datos. Esto le permite al modelo generar etiquetas precisas y consistentes.
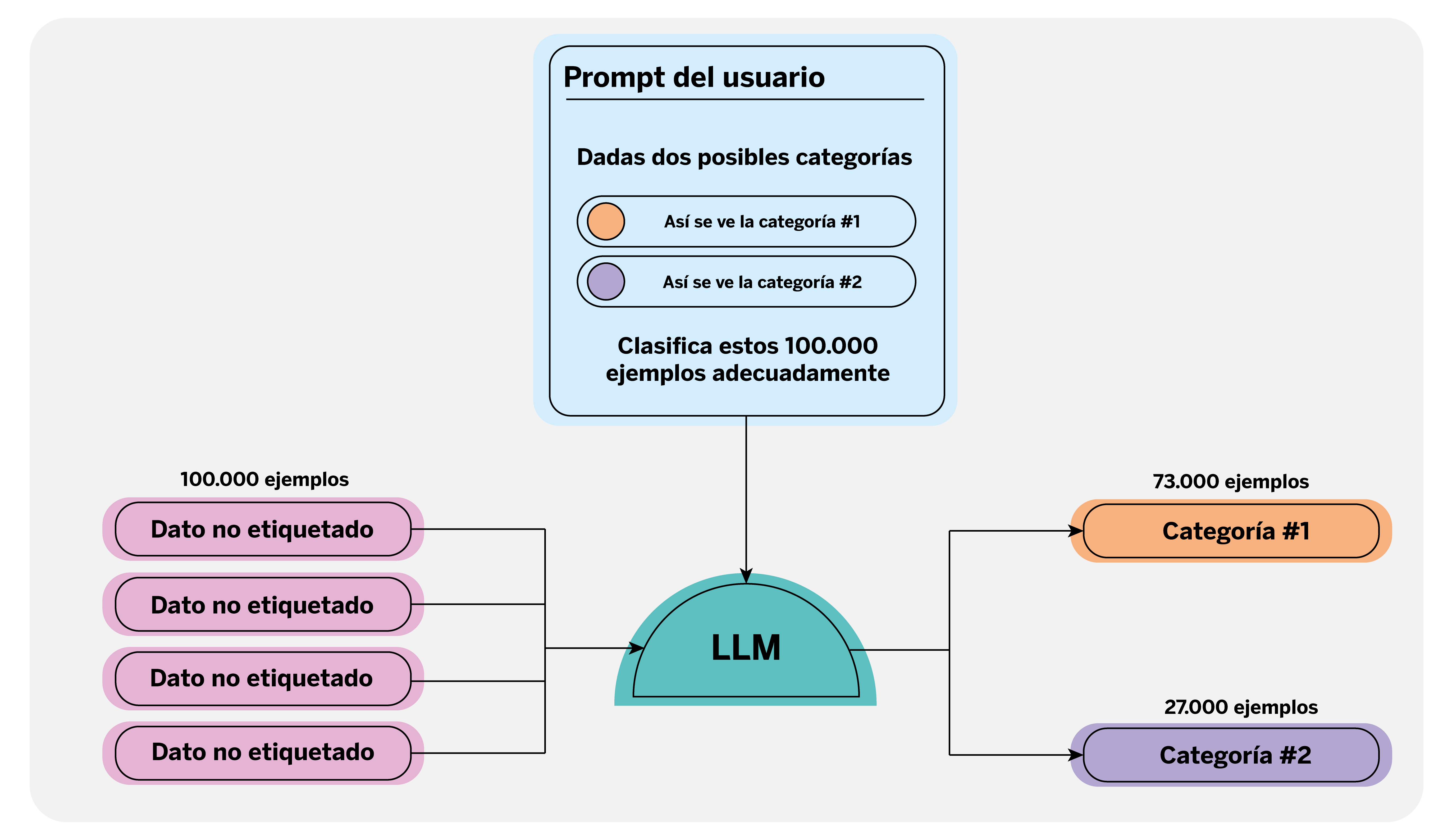
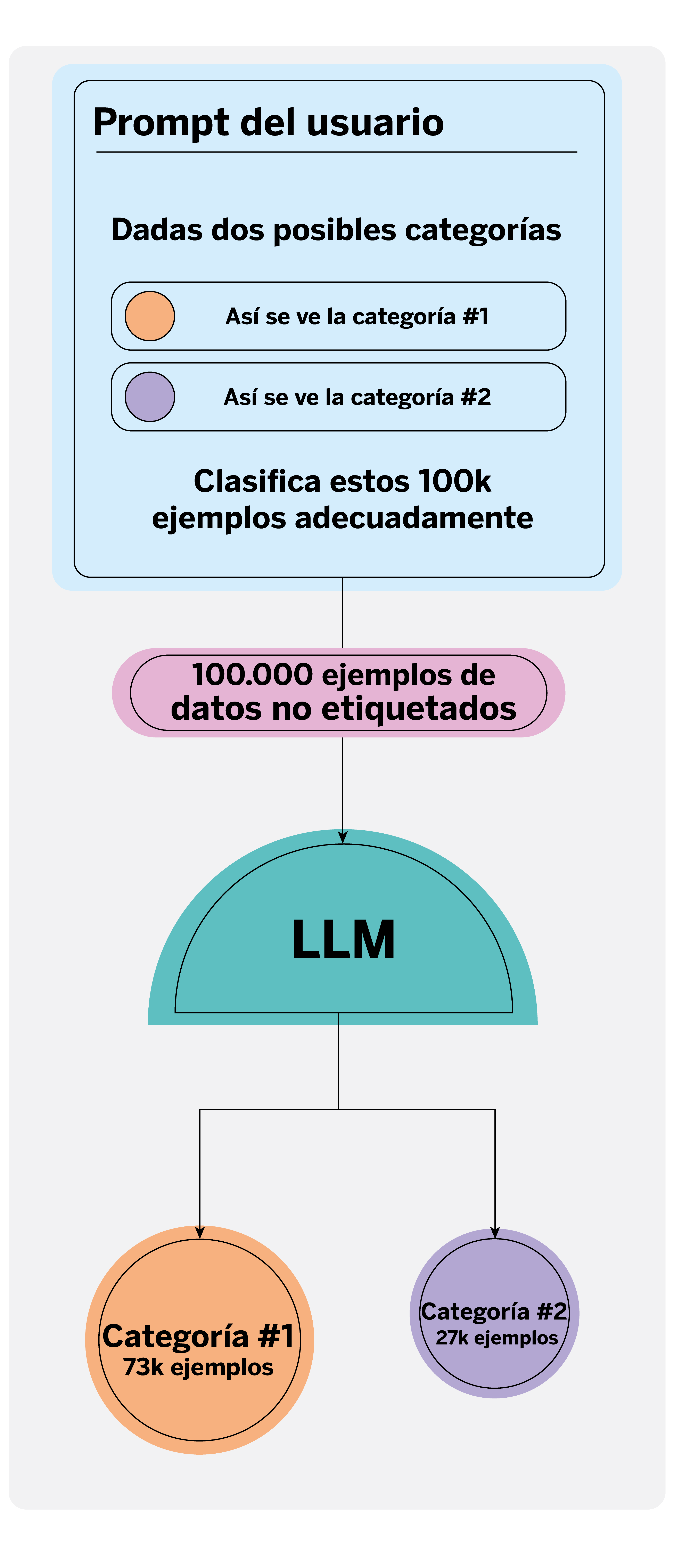
Automatizar esta tarea permite a los científicos de datos dedicar menos tiempo al etiquetado, y pueden enfocarse más en supervisar y corregir cualquier discrepancia en las etiquetas generadas, asegurando así la calidad del dataset final. Así, se optimizan los recursos y se abren nuevas posibilidades en la gestión de datos a gran escala.
Minimizar el esfuerzo en tareas de evaluación: self-critique
Una de las fases más importantes en el ciclo de desarrollo de un modelo analítico, en este caso, un modelo de lenguaje, es la evaluación de sus resultados. Esto nos sirve para estimar y mejorar su rendimiento al desplegarse en producción, e incluso para afinar el prompt que le proporcionamos. No obstante, esta evaluación no está tan claramente definida como la de modelos más tradicionales de aprendizaje automático, donde contamos con métricas establecidas como la precisión (accuracy) para abordar problemas de clasificación o el MSE (error cuadrático medio) para regresión.
En el ámbito de la IA generativa, resulta imprescindible definir un conjunto de métricas para evaluar aspectos como la relevancia de la respuesta, su consistencia y su integridad. Una vez definidas, calificar cada respuesta según estos criterios puede convertirse en un cuello de botella por el tiempo que conlleva, así como por la subjetividad de la evaluación, dado que distintos evaluadores humanos podrían tener criterios diferentes. Por esta razón, surge la alternativa de utilizar otro LLM para evaluar las respuestas generadas.
Una de las virtudes de los LLM es que se ha observado que poseen cierta capacidad de “razonamiento” o “crítica”, lo que puede ser de gran ayuda para evaluar el texto generado por otros LLM o incluso por ellos mismos, facilitando así la tarea de evaluación manual.
La evaluación puede orientarse de diferentes maneras según el problema: ¿Responde la pregunta correctamente? ¿Es la respuesta clara y concisa? ¿Inventa contenido o todo lo que genera es basado en el contexto proporcionado? ¿Contiene datos personales?
Imaginemos, por tanto, que deseamos evaluar cómo funciona un sistema de respuesta automática, por ejemplo, con una métrica que mide si la respuesta contiene información inventada o si divulga información personal. Podríamos desarrollar un sistema de evaluación (con ayuda de técnicas de prompting), evaluar manualmente una muestra de respuestas generadas y comparar las métricas de nuestro sistema con las que obtenemos manualmente. En caso de que observemos que el comportamiento es similar, este podría sustituir a la evaluación manual. Esto no implica que se elimine por completo dicha tarea, puesto que siempre será necesario revisar cómo evalúa el LLM en cuestión y, para ello, se requiere cierta supervisión humana.
Enriquecer las respuestas de los modelos con grandes bases de conocimiento
Los LLM tienen una capacidad excelente para comprender y manejar grandes volúmenes de datos, ya sean textos, imágenes o vídeos. Esta habilidad les permite realizar resúmenes y gestionar consultas en formato conversacional.
La primera posibilidad, y seguramente la más evidente, es aprovechar el gran tamaño de contexto que algunos de los actuales LLM pueden procesar (cantidad de texto que les podemos facilitar) para enriquecer nuestra consulta con toda la información adicional que consideremos necesaria. Por ejemplo, si lanzamos una pregunta sobre normativa pública, además de aprovecharnos del conocimiento general que posee el modelo, podemos obtener una mejor respuesta si en el prompt incluimos el documento con los detalles de esa normativa en concreto.
Sin embargo, cuando tenemos más información de la que el modelo puede procesar o no sabemos específicamente cuáles pueden ser los documentos que nos ayudan a responder, entran en juego otras técnicas. Las dos principales son Retrieval Augmented Generation (RAG) y fine-tuning. El RAG recupera información de documentos mediante un modelo de lenguaje. Cuando se realiza una consulta, primero se busca en la base de datos la información relevante para responder, y luego se utiliza esta información recuperada para que el LLM genere una respuesta enriquecida y contextualizada.
El fine-tuning, por otro lado, implica ajustar un LLM preentrenado para especializarlo en un dominio o tarea específica, utilizando un conjunto de datos pertinente a esa tarea.
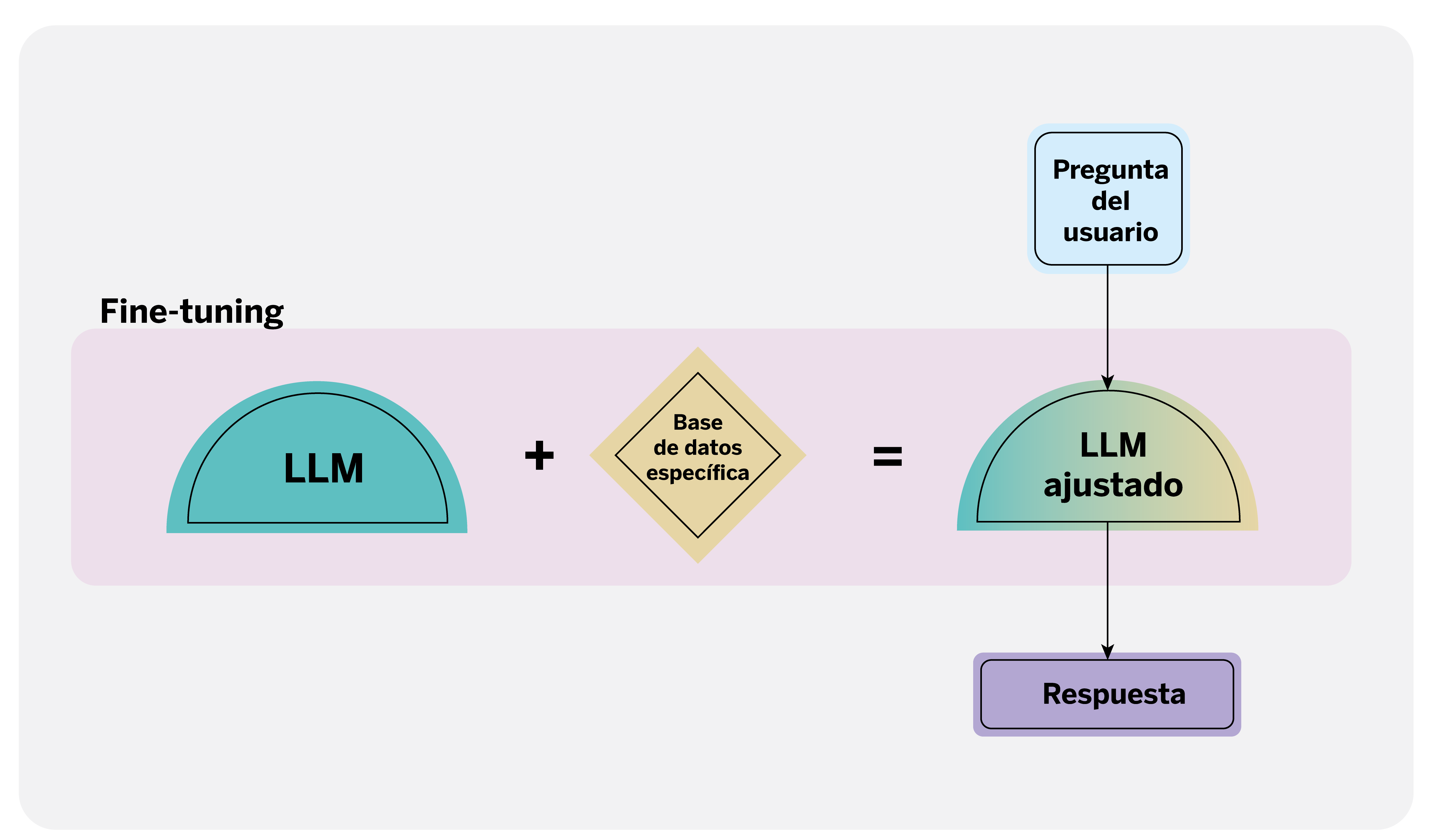
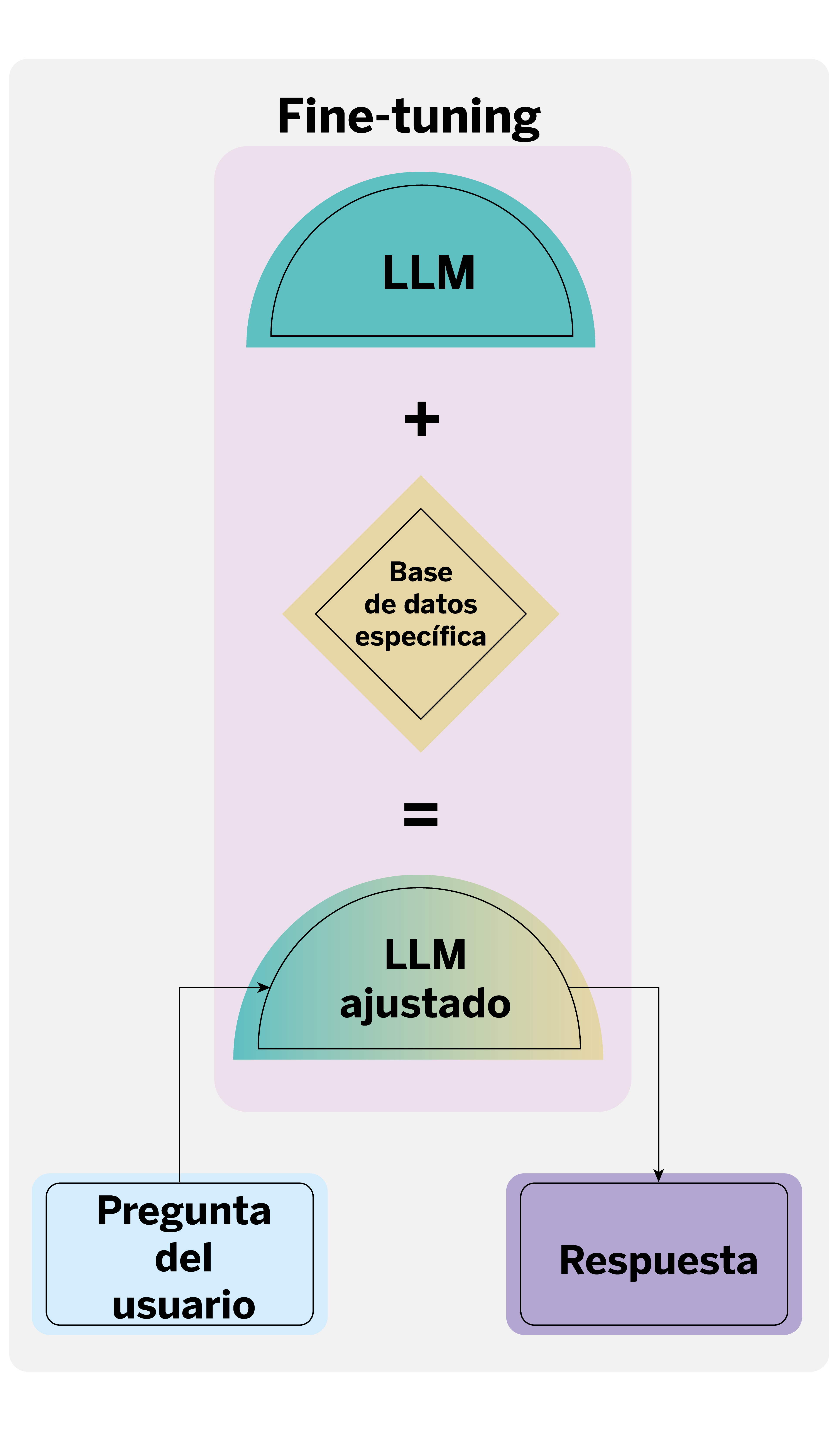
Cada técnica tiene sus ventajas y desventajas. El RAG, por ejemplo, es menos propenso a generar afirmaciones falsas y produce resultados más interpretables; es especialmente útil para bases de conocimiento que están sujetas a cambios o actualizaciones periódicas. Por su parte, el fine-tuning generalmente ofrece menor latencia y puede proporcionar mejores resultados cuando se dispone de un conjunto de datos rico y bien adaptado a la tarea en cuestión.
Generar datos sintéticos
Supongamos que estamos trabajando en un problema de clasificación multiclase donde etiquetamos productos financieros según su temática: tarjetas, cuentas, seguros, fondos de inversión, planes de pensiones, criptomonedas, etc. Al entrenar un clasificador, es posible que muestre cierta tendencia o sesgo en sus predicciones hacia algunas categorías, posiblemente debido a que otras categorías están menos representadas en el conjunto de datos. Esto puede afectar al rendimiento del modelo.
Una solución para este problema es la generación de datos sintéticos. Los datos sintéticos son información creada artificialmente por modelos computacionales que imitan la estructura y las características de los datos reales pero no provienen de eventos del mundo real. En el contexto de la inteligencia artificial, estos datos pueden ayudar a balancear un conjunto de datos, proporcionando ejemplos adicionales en las categorías que están infrarrepresentadas.
Los LLM son particularmente útiles para esta tarea. Mediante técnicas de prompting proporcionamos ejemplos específicos del tipo de texto que queremos que el modelo genere y así equilibramos nuestro conjunto de datos. Este proceso puede implementarse usando métodos como el “few-shot learning“, donde se muestra al modelo algunos ejemplos para que aprenda la tarea, o el “patrón de persona”, que define un formato específico que el texto generado debe seguir.
Al generar datos sintéticos, no solo podemos reducir los sesgos en las predicciones del clasificador, sino también mejorar la robustez y la generalización del modelo, permitiendo que este maneje una variedad más amplia de situaciones sin depender únicamente de los datos originalmente disponibles. Esta estrategia es especialmente valiosa en situaciones donde la recopilación de datos reales es costosa, lenta o poco práctica.
Invocar o realizar acciones mediante lenguaje natural
Los agentes basados en LLM son sistemas capaces de ejecutar acciones. Como científicos de datos, esto nos ofrece una nueva funcionalidad que podemos aprovechar en aplicaciones como los chatbots. Previamente, invocar acciones en conversaciones, como cuando interactuamos con dispositivos como Alexa, requería comandos específicos.
Por ejemplo, para encender la luz del salón debemos especificar a Alexa la acción concreta y el nombre exacto que le hemos dado a esa lámpara. No obstante, gracias a estos agentes, los LLM pueden interpretar la intención del usuario incluso si la orden no se menciona explícitamente, y proceder a invocar las acciones necesarias.
Para que los agentes puedan ejecutar estas acciones, es esencial que estén claramente definidas como ‘tools’2 (herramientas en inglés). Estas tools son componentes que permiten extender las funcionalidades del LLM más allá de su capacidad de diálogo, y deben incluir una descripción detallada de la acción a realizar, los parámetros necesarios para su ejecución y el código correspondiente para llevarla a cabo.
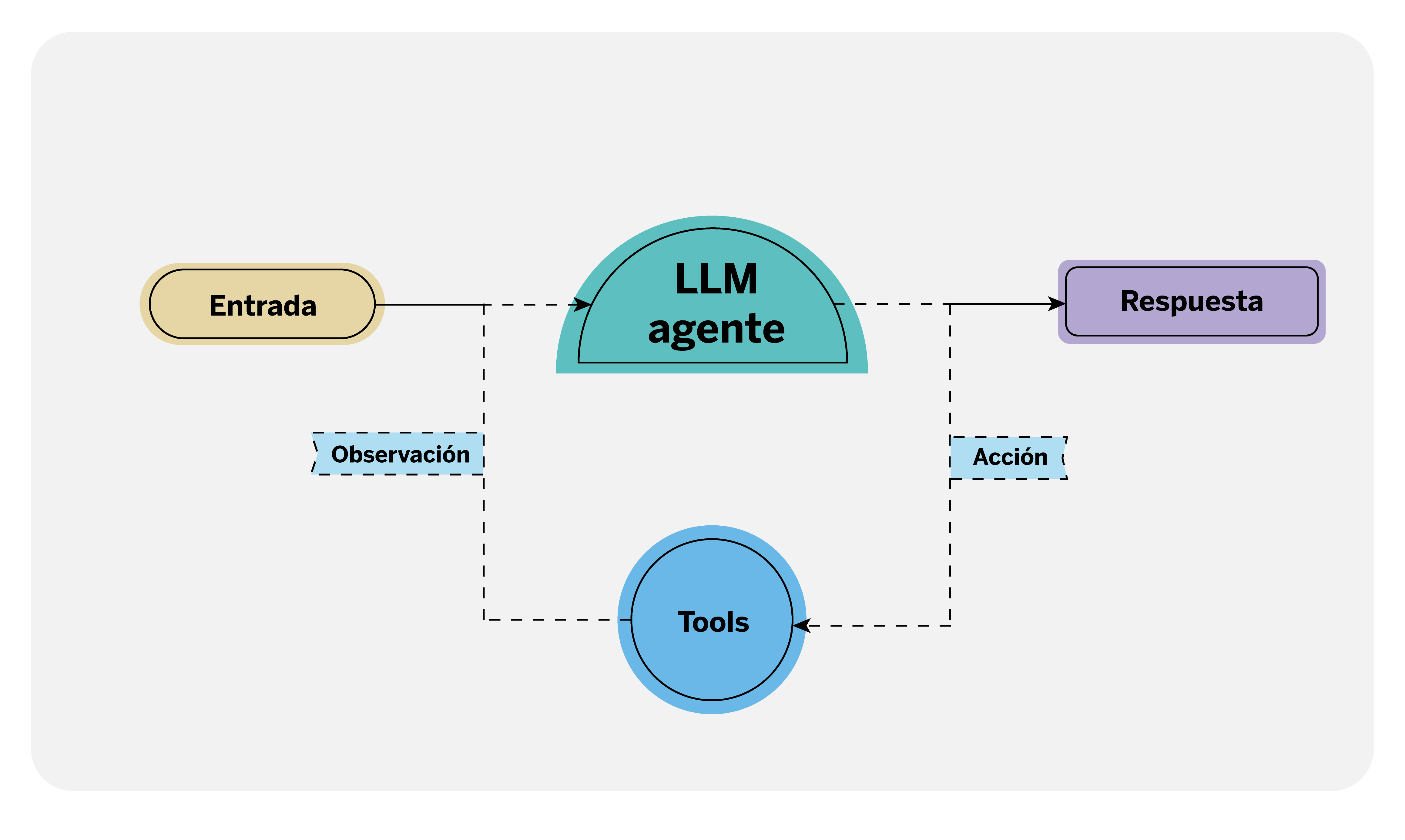
Dado que los modelos de lenguaje más avanzados han sido entrenados específicamente para estas tareas, tienen la capacidad de identificar cuándo invocar una de las tools definidas, recuperar los parámetros necesarios y ejecutar la acción adecuadamente.
Conclusiones
Estas aplicaciones de los LLM están transformando profundamente nuestro trabajo diario como científicos de datos. Herramientas como GitHub Copilot facilitan la programación, mientras que técnicas como “prompt-critique” mejoran la calidad de los prompts que redactamos, permitiéndonos identificar carencias y corregir instrucciones que no son del todo claras o precisas en tareas de etiquetado automático.
Además, el uso de LLM para automatizar tareas repetitivas nos permite concentrarnos en la interpretación de resultados y en la toma de decisiones estratégicas. Esta revolución abre nuevas áreas de investigación y aplicación, y nos permite ejercer nuestra creatividad para abordar problemas complejos que las máquinas aún no pueden resolver.
El mundo de la inteligencia artificial está en constante evolución, y nuevos descubrimientos y actualizaciones siguen redefiniendo nuestras formas de trabajo en el sector tecnológico.

Notas
- Conjunto de instrucciones que el usuario proporciona al LLM y que condicionan la generación de texto que ofrece como respuesta el LLM↩︎
- Son interfaces que permiten a un LLM interactuar con el mundo. Están compuestas por flujos de trabajo ejecutables bien definidos que los agentes pueden usar para llevar a cabo diversas tareas. Frecuentemente, pueden considerarse como APIs externas especializadas. ↩︎