
¿Cómo enfocamos la anotación humana en tiempos de IA generativa?
La anotación de datos sigue siendo fundamental para crear modelos de IA eficaces. Los modelos tradicionales de IA requieren etiquetas precisas para el entrenamiento, lo que a veces hace necesaria la anotación. La anotación es vital en la IA generativa, especialmente para tareas de evaluación. Esta puede realizarse de forma manual (anotación humana) o automática (por ejemplo, utilizando un LLM para este fin o métricas como BLEU o ROUGE).
Dependiendo del problema específico que necesitemos resolver, es esencial determinar cuándo es conveniente automatizar y cuándo es mejor confiar en anotadores humanos, o una combinación de ambos.
La anotación de datos suele ser un cuello de botella en los proyectos de IA debido a su complejidad y a los recursos que requiere. Los grandes modelos de lenguaje (LLM, por sus siglas en inglés) pueden automatizar este proceso interpretando las consultas en lenguaje natural. Por ejemplo, al evaluar un RAG1 (un asistente de chatbot que utiliza Retrieval Augmented Generation), un LLM es capaz de evaluar si la respuesta generada responde a la consulta del usuario.
Sin embargo, no siempre es aconsejable confiar únicamente en la automatización. El sesgo de automatización -cuando los humanos confían excesivamente en las decisiones de las máquinas- puede introducir errores y perpetuar los sesgos inherentes a los datos de entrenamiento.
Además, estos modelos pueden utilizar criterios que no se ajusten a las necesidades específicas de un proyecto determinado. Por ello, es esencial garantizar que los modelos cumplen estándares éticos y funcionales, lo que puede lograrse mediante una metodología interna de anotación humana. Este sistema sienta las bases para desarrollar herramientas automatizadas que se ajusten a los criterios humanos y a los requisitos específicos de cada proyecto.
Sí, anotación humana, pero considera los retos
La anotación humana es recomendable para obtener resultados matizados y de alta calidad al evaluar modelos generativos. Sin embargo, debemos reconocer los retos a los que nos enfrentamos al abordar esta tarea.
En primer lugar, la subjetividad de los anotadores puede dar lugar a inconsistencias, sobre todo cuando entre ellos entienden de forma distinta la tarea en cuestión. Para mitigar este problema, debemos contar con directrices o guías exhaustivas con ejemplos concretos para que el proceso de anotación sea consistente.
En segundo lugar, la gestión de la escala de los conjuntos de datos es un reto importante en la anotación de datos. A menudo es necesario disponer de grandes conjuntos de datos bien anotados para poder actuar con eficacia. Sin embargo, esto hace que el proceso de anotación sea largo y exigente. En este sentido, es crucial encontrar un equilibrio entre coste y calidad.
Antes de iniciar el proceso de anotación es importante calcular el tamaño mínimo del conjunto de datos y establecer umbrales de acuerdo. Así se garantiza que el conjunto de datos sea manejable y cumpla las normas de calidad necesarias desde el principio.
¿Cómo afrontar tareas de anotación complejas? Nuestra metodología
Imagina que quieres crear un asistente conversacional (chatbot) y medir la precisión de sus respuestas. Pero, surge la pregunta: ¿qué significa una respuesta precisa? Para definir este criterio de forma objetiva y anotar como corresponde, te recomendamos una serie de pasos:
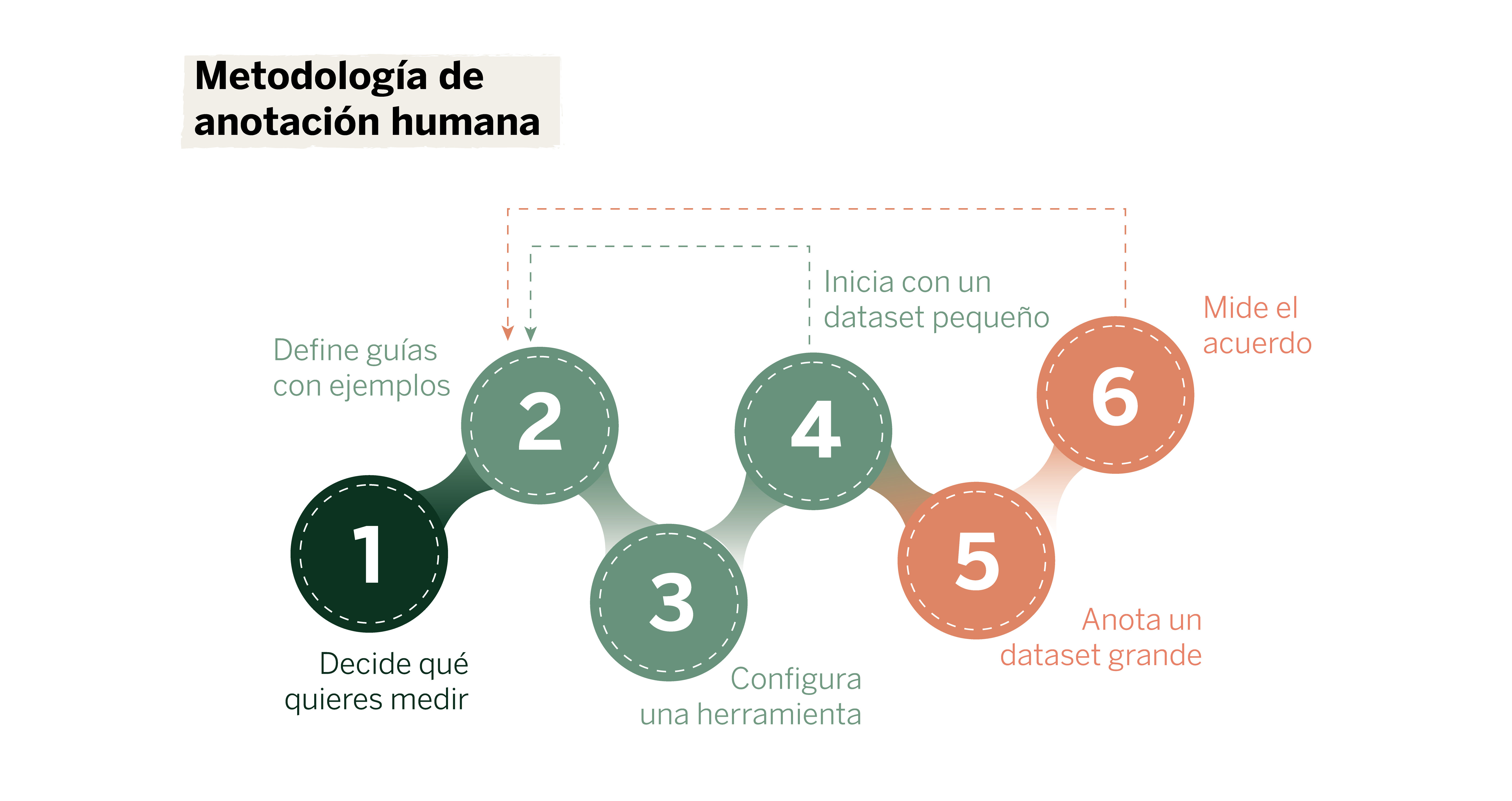
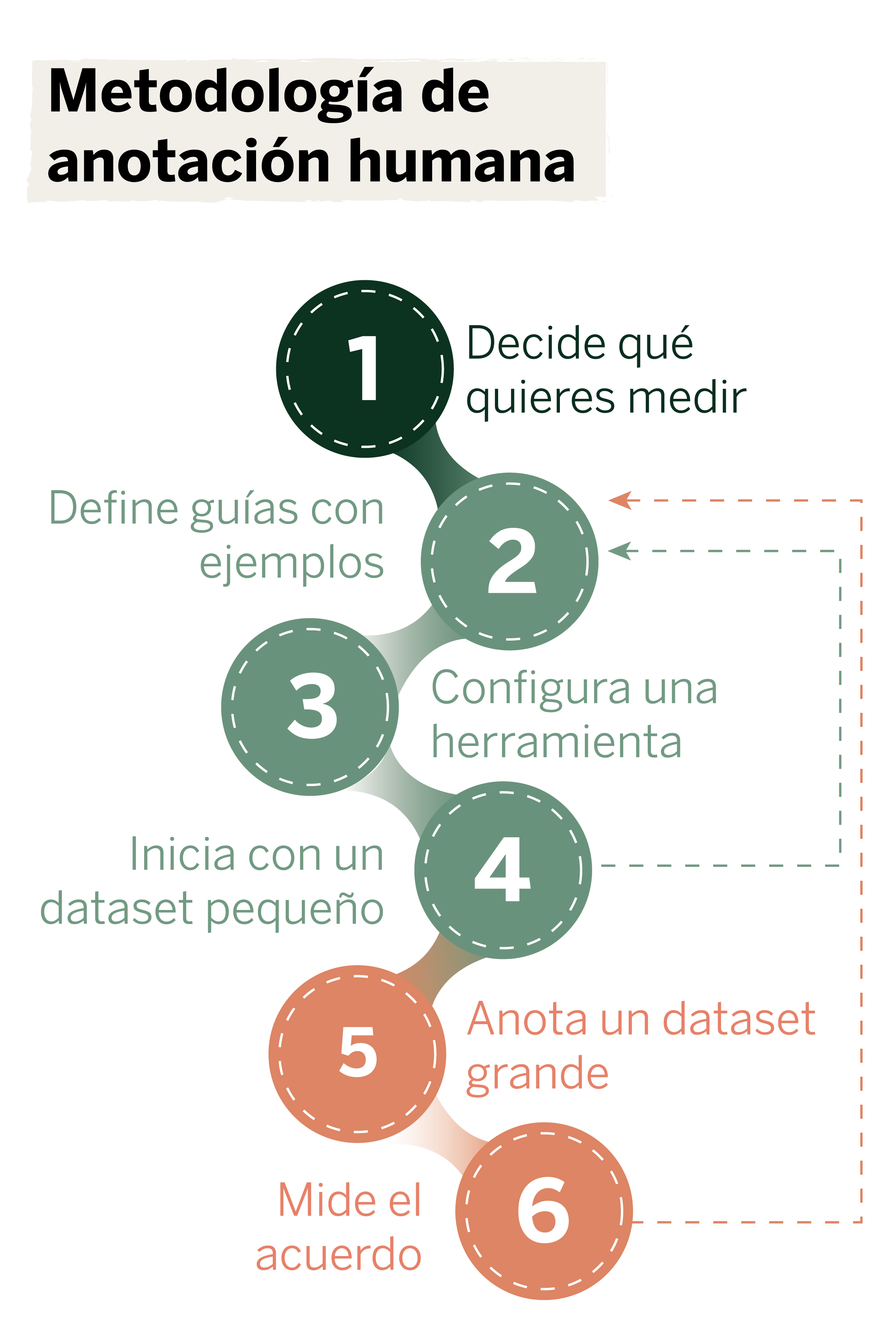
 Selecciona un grupo de personas y asigna roles
Selecciona un grupo de personas y asigna roles
Antes de embarcarte en un proyecto de anotación, decide quién será el propietario de la anotación (Annotation Owner). Debe ser la persona o el grupo que se beneficiará de la tarea de anotación, como puede serlo el equipo que desarrolla el chatbot. Esta persona será la responsable de evaluar y supervisar el sistema.
A continuación, elige un grupo de anotadores que se encargarán de la tarea de anotación manual. Es importante que estas personas conozcan el ámbito del proyecto. Por ejemplo, si el chatbot está pensado para atención al cliente, los anotadores deberán estar familiarizados con esos protocolos. Una vez definidas las guías de anotación, estos anotadores podrán tomar decisiones con conocimiento de causa.
 Decide cuidadosamente lo que quieres medir
Decide cuidadosamente lo que quieres medir
Antes de comenzar con el proceso de introducir datos, define claramente lo que quieres medir. Esto implica comprender a fondo los objetivos del proyecto y cómo contribuirán los datos anotados a alcanzarlos.
Pregúntate: ¿cuál es el objetivo principal del modelo? En este caso, podría ser proporcionar respuestas precisas y útiles a las consultas de los clientes. ¿Qué tipo de patrones o información hay que extraer de los datos? ¿Cómo se utilizarán los datos anotados para entrenar y evaluar el modelo? Definir claramente lo que se quiere medir garantiza que los esfuerzos de anotación se alineen con los objetivos del proyecto, evitando así la recopilación de datos innecesarios o irrelevantes.
 Define guías con ejemplos
Define guías con ejemplos
Las directrices de anotación deben ir acompañadas de ejemplos concretos que ilustren cómo aplicar los criterios en situaciones reales. Esto ayuda a los anotadores a comprender mejor las expectativas y a manejar casos ambiguos o complejos. Al definir las directrices para el chatbot:
- Incluye ejemplos de respuestas precisas (correctamente puntuadas) e imprecisas (incorrectamente puntuadas) del chatbot.
- Proporciona descripciones detalladas de cada ejemplo, explicando el porqué fue anotado de esa manera.
- Actualiza los ejemplos a medida que se identifiquen nuevos casos o se perfeccionen los criterios de anotación.
- Utiliza un lenguaje sencillo y directo en las directrices de anotación.
- Evita criterios complejos o subjetivos que puedan dar lugar a interpretaciones incoherentes.
- Asegúrate de que cada criterio de anotación sea medible y observable.
Los ejemplos claros y detallados ayudan a alinear la interpretación de los criterios entre todos los anotadores, lo que mejora la coherencia de las anotaciones.
 Configura una herramienta adecuada para el caso de uso
Configura una herramienta adecuada para el caso de uso
Utilizar la herramienta de anotación adecuada puede mejorar la eficiencia y la precisión del proyecto. Algunos ejemplos son Label Studio, Amazon SageMaker Ground Truth y otras plataformas de anotación. Investiga cuál es la más adecuada para la tarea y según tu presupuesto.
 Haz unas cuantas rondas con un pequeño conjunto de datos y perfecciona las guías
Haz unas cuantas rondas con un pequeño conjunto de datos y perfecciona las guías
Antes de comenzar a anotar un gran volumen de datos, empieza con un pequeño conjunto de datos, lo que te permitirá identificar y solucionar problemas en las guías y en el proceso de anotación. Para ello:
- Selecciona un conjunto de datos que sea representativo, pero de tamaño manejable.
- Realiza varias rondas de anotación, evaluando la coherencia y la precisión en cada ronda. Cada sesión debe realizarse con entre 5 y 10 ejemplos.
- Toma los ejemplos en los que hay desacuerdo, realiza una sesión con el equipo de anotadores y perfecciona las guías con las conclusiones del debate. Estos refinamientos pueden consistir en ejemplos específicos o instrucciones más detalladas.
El annotation owner debe participar activamente en todo el proceso de anotación, desde la fase inicial de definición hasta la realización de varias rondas. Esta implicación pasa por ser uno de los anotadores, participando en las primeras pruebas con un pequeño conjunto de datos.
 Anota el conjunto de datos completo
Anota el conjunto de datos completo
Una vez que las guías estén bien definidas y probadas con un conjunto de datos pequeño, es el momento de anotar el conjunto de datos completo. Asegúrate de:
- Dividir el conjunto de datos en lotes más pequeños y establece objetivos específicos para cada lote. Por ejemplo, si tu objetivo es anotar 200 muestras, divide los ejemplos en tres rondas de 50, 75 y 75 muestras y mide el grado de acuerdo en cada ronda.2
- Formar a los anotadores utilizando las directrices perfeccionadas y los ejemplos.
- Implantar un sistema de control de calidad para supervisar y revisar las anotaciones con regularidad.
- Proporcionar herramientas y recursos que hagan que el proceso de anotación sea más eficaz y preciso.
 Mide el grado de acuerdo y vuelve a las guías
Mide el grado de acuerdo y vuelve a las guías
Tras anotar el conjunto de datos, mide el nivel de acuerdo entre los anotadores (lo que se conoce como acuerdo inter-anotador). Esto puede hacerse utilizando métricas como el coeficiente Cohen Kappa o el porcentaje de acuerdo. Si el nivel de acuerdo es bajo:
- Revisa las directrices y los ejemplos proporcionados.
- Identifica las áreas de ambigüedad o confusión y aclara los criterios.
- Proporciona comentarios adicionales y formación a los anotadores.
Si es necesario, vuelva a las guías para perfeccionar los criterios antes de proceder con nuevas anotaciones. Este ciclo iterativo de evaluación y refinamiento es vital para garantizar que las anotaciones sean precisas y coherentes a lo largo del tiempo.
Siguiendo estos pasos, podrás definir y medir sistemáticamente la precisión de las respuestas de tu chatbot, asegurándote de que cumple los estándares de rendimiento previstos, además de servir de forma segura y eficaz a los usuarios.
Desarrollo de un una herramienta automatizada
Una vez que nos aseguremos de que la anotación humana funciona correctamente y exista un consenso claro sobre los criterios a seguir, es posible crear un evaluador automático basado en un gran modelo de lenguaje. Se puede desarrollar un LLM judge (un modelo de lenguaje que sirva como juez) proporcionándole las guías para los anotadores, un prompt (instrucción) específica y un conjunto de datos anotados manualmente. Cómo hacer esto de forma adecuada y eficiente es una línea de investigación activa con sus ventajas y limitaciones.3
El desempeño del LLM judge puede entonces compararse con los criterios humanos previamente definidos. Para esta comparación, el acuerdo entre anotadores humanos puede utilizarse como punto de referencia. Supongamos que el acuerdo entre el LLM y un humano es similar al acuerdo entre humanos. En ese caso, podemos considerar que hemos alcanzado un rendimiento de nivel humano con el LLM judge, lo que nos permitirá utilizarlo en el futuro para, por ejemplo, automatizar el proceso de evaluación.
Resumiendo
La anotación humana sigue siendo una tarea esencial en la evaluación de los modelos de IA generativa, pero conlleva mucho tiempo y puede resultar tediosa. Es importante abordarla de forma progresiva y sistemática, asegurándonos de que se cumplen criterios objetivos. Una vez establecida una base sólida con anotaciones humanas, podemos proceder a construir modelos de lenguaje que reflejen las decisiones matizadas tomadas por los anotadores humanos, manteniendo así la calidad y fiabilidad de las anotaciones.
En conclusión, la integración de los LLM para la anotación automática debe enfocarse como una herramienta complementaria que mejora la eficiencia en lugar de sustituir por completo la supervisión humana. Combinando los puntos fuertes de las capacidades humanas y de las máquinas, podemos conseguir modelos de IA más sólidos, eficientes y, en última instancia, más responsables.
Referencias
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … & Kiela, D. (2020). “Retrieval-augmented generation for knowledge-intensive nlp tasks.” Advances in Neural Information Processing Systems, 33, 9459-9474.↩︎
- Sim, Julius, and Chris C. Wright. “The kappa statistic in reliability studies: use, interpretation, and sample size requirements.” Physical therapy 85.3 (2005): 257-268.↩︎
- ZHENG, Lianmin, et al. “Judging llm-as-a-judge with mt-bench and chatbot arena.” Advances in Neural Information Processing Systems, 2024, vol. 36. ↩︎