
Explicando a humanos la fiabilidad de los algoritmos
En 2018, coincidiendo con la celebración de la copa del mundo de fútbol, una empresa se aventuró a pronosticar la probabilidad que tendría cada equipo de convertirse en campeón (el informe original no está disponible pero sigue pudiendo leerse algún artículo en medios que cubrieron la historia). Encabezaba la lista Alemania, con un 24% de probabilidad. En cuanto Alemania fue eliminada, este pronóstico se tomó como equivocación y la anécdota circuló por las redes sociales.
El problema no estaba tanto en el modelo, del que no se desvelaron detalles, aunque se hablaba de una metodología de simulación, seguramente muy fiable, ya que se conocen modelos robustos de pronósticos deportivos (con ocasión del mundial, en BBVA AI Factory también hicimos una visualización de datos de jugadores y equipos). Tampoco encontramos el problema en la redacción del informe, que nunca llegaba a concluir que sólo podía ganar Alemania.
Lo que sí que fue un problema es la interpretación del resultado que le dieron algunos medios y el público general, ya que muchos interpretaron ‘gana Alemania’ con unos números que no lo afirmaban: la probabilidad estaba tan fragmentada, que si para Alemania era de un 24%, había un 76% de que ganase cualquier otro equipo, ¿no?
Los humanos tendemos a simplificar: el wet bias
Este fenómeno, por el que a los humanos no se nos da bien evaluar escenarios basados en probabilidades, es bien conocido por los meteorólogos. En 2002 fue desvelado un fenómeno bautizado como el sesgo húmedo (“wet bias”): la observación de que los servicios de meteorología en algunos medios estadounidenses solían inflar deliberadamente la probabilidad de precipitación, para que fuese mucho mayor a la que realmente habían calculado. En su conocido libro “The Signal and the Noise”, el estadístico y divulgador de datos Nate Silver profundiza en el fenómeno y llega a atribuirlo a que los meteorólogos creen que la población, cada vez que ve una probabilidad de lluvia demasiado pequeña (digamos un 5%), lo interpreta directamente como “no va a llover” (y, consecuentemente, se lleva una decepción el 5% de las veces).

Ello hace entrever que los humanos tendemos a simplificar la información para tomar decisiones. Y es que ese 5% de probabilidad de lluvia, o el 24% de probabilidad de que Alemania ganase el mundial, no hay que transformarlo en una decisión de blanco o negro, sino tomarlo como información para analizar escenarios. El propio Nate Silver, en su post “The media has a probability problem” o en su última charla en Spark Summit 2020, analiza esta limitación que tenemos las personas para construir escenarios dadas unas probabilidades, ilustrándolo con ejemplos de pronóstico de huracanes o las elecciones en EEUU de 2016. Como argumenta Kiko Llaneras en su artículo “En defensa de la estadística”, toda predicción tiene que caer del lado improbable alguna vez.
Diseñando algoritmos correctamente desde el principio
Quienes trabajamos con Machine Learning en el diseño de productos pensados para ser usados por personas creemos que no debemos reproducir ese mismo error de tomar los resultados de pronósticos como absolutos. Nos corresponde entender bien qué nivel de confianza tiene un sistema de Machine Learning respecto al resultado que ofrece, y transmitirlo adecuadamente a los receptores de la información.
Por ejemplo, si queremos diseñar un algoritmo de pronóstico de los gastos que tendrá un cliente, para informarle a través de la app de BBVA, nos interesa poder analizar cómo de seguro está el algoritmo en cada pronóstico, y quizás descartar los casos donde no tengamos alta seguridad.
Sorprendentemente, muchos algoritmos de pronóstico están diseñados de manera que pueden inducir a un error de interpretación similar al que describíamos en el caso del mundial. Esto es porque la estimación que proporciona un modelo de pronóstico (por ejemplo, el gasto del siguiente mes), y que toma información observada en el pasado (gasto en los meses anteriores) resulta en forma de un único valor. Y ya hemos comentado lo que puede suceder si reducimos todo sólo al valor más probable. Sería más interesante que el sistema fuese capaz de proporcionar un rango (el gasto estará entre 100 y 200 euros), y “atreverse” a reducir el rango cuando está muy seguro (por ejemplo si se detectan gastos fijos recurrentes) o ampliarlo si no lo está (por ejemplo si estamos en un período más impredecible como el vacacional), caso por caso.
En BBVA AI Factory hemos trabajado en una línea de investigación, junto con la Universidad de Barcelona, para tratar de desarrollar ese tipo de algoritmos, usando técnicas de pronóstico con redes neuronales. Esta línea ya la habíamos comentado en otros posts y ha dado como resultado publicaciones, incluyendo una en la prestigiosa conferencia NeurIPS 20191.
Gracias a esta labor de investigación, ahora tenemos algoritmos capaces de hacer pronósticos que resultan en un rango de incertidumbre, o una función matemática de distribución, en lugar de un solo valor, lo cual nos da información más completa.
¿Podemos confiar en las cajas negras? (Spoiler: Sí, con ciertos trucos)
Sin embargo, nos hemos encontrado un obstáculo más: muchas veces, los equipos de ciencia de datos utilizamos modelos que no hemos creado nosotros: modelos de otros, de librerías de código o APIs externas, o de paquetes de software. Si tenemos un sistema de pronósticos que ya está en marcha (por ejemplo, estimación de gastos del siguiente mes, o estimación de saldo de los próximos días), y por alguna buena razón no lo podemos sustituir, ¿podemos diseñar otro algoritmo que estime cómo de seguro está el primero, sin tener que sustituirlo o llegar a modificarlo?
La respuesta es afirmativa y ha sido descrita en nuestro reciente artículo, “Building Uncertainty Models on Top of Black-Box predictive APIs”, publicado en IEEE Access y firmado por los autores de BBVA AI Factory y de la Universidad de Barcelona Axel Brando, Damià Torres, José A. Rodríguez Serrano y Jordi Vitrià. En él, describimos un algoritmo de red neuronal que transforma el pronóstico dado por cualquier sistema ya existente en un rango de incertidumbre. Distinguimos dos casos: el primero, donde conocemos los detalles del sistema que queremos mejorar. Pero también tratamos el caso donde el sistema que queremos mejorar sea lo que llamamos una caja negra, es decir, un sistema que usamos para generar pronósticos pero que no podemos modificar y que no sabemos cómo ha sido construido. Un caso que se da frecuentemente en la realidad, por ejemplo, al usar software de un proveedor.
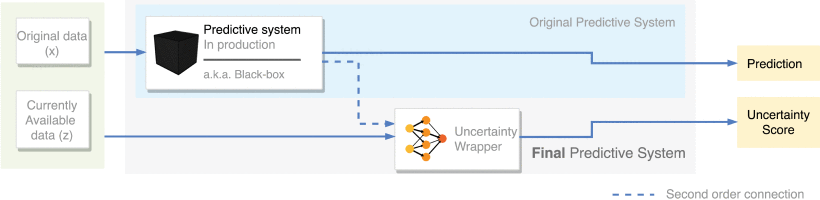
Esto abre la posibilidad de usar cualquier sistema de pronóstico disponible, que trabaje dando estimaciones puntuales y, sin tener que modificarlo, “aumentarlo” con la capacidad de proporcionar un rango de incertidumbre, como se indica esquemáticamente en la figura anterior. Hemos verificado el sistema en casos de pronóstico bancario y en casos de predicción de consumo eléctrico. Dejamos el enlace al artículo por si otros investigadores, científicos de datos o cualquier persona interesada pueda consultar los detalles.
El reto: traducir la fiabilidad a lenguaje humano
Con este trabajo, hemos cubierto el reto de diseñar un sistema de pronóstico que proporcione más información. Pero sigue sin resolver la pregunta fundamental que hacíamos al inicio: si construimos productos basados en Machine Learning, ¿cómo transferir al usuario final esa información de una manera que entienda que es una estimación útil, pero que podría tener errores?
Esto sigue siendo un tema abierto. Recientemente, una presentación de Apple sobre diseño de productos con machine learning arrojaba algo de luz sobre este aspecto: sugerían comunicar la información incierta en términos de alguna cantidad que apele al usuario. Mejor decir “si esperas a reservar, podrías ahorrar 100 euros”, que “la probabilidad de que el precio baje es de 35%”. La última fórmula (la más utilizada generalmente) podría originar los mismos problemas de interpretación que se produjeron con el caso de Alemania en el mundial. Si los humanos no somos animales de mentalidad estadística, quizás el reto sea traducir la probabilidad a lenguaje humano.