¿Cómo analizamos el feedback de los clientes con transformers y NLP?
En BBVA, la satisfacción del cliente es uno de los pilares fundamentales en la evolución de nuestros productos y servicios. Para medir esta satisfacción, muchas veces nos basamos en métricas cuantitativas como el Net Promoter Score (NPS), que mide la probabilidad de que un cliente nos recomiende a otras personas.
Aunque estas métricas ofrecen una visión general, no explican el “porqué” detrás de las respuestas de los clientes. Es aquí donde el feedback cualitativo, en forma de comentarios escritos, resulta fundamental para tener una visión más profunda y rica de la experiencia del usuario. Para aprovechar estos datos que obtenemos a través de los cuestionarios de satisfacción de nuestra app, en BBVA hemos desarrollado una solución avanzada que combina tecnologías de procesamiento del lenguaje natural (NLP, por sus siglas en inglés, Natural Language Processing) y modelos pre-entrenados basados en transformers.
Esta solución nos permite analizar grandes volúmenes de comentarios, además de identificar y agrupar automáticamente los aspectos o temáticas clave que mencionan los usuarios.
En este artículo, explicaremos cómo implementamos un modelo para el análisis de feedback en múltiples idiomas a partir de un sentence-transformer pre-entrenado de HuggingFace, el cual ajustamos mediante técnicas de fine-tuning. Así conseguimos clasificar los mensajes que recibimos, y se traduce en una aplicación práctica: un sistema que nos permite dar respuesta a los comentarios de los clientes.
Retos en la extracción de insights de los clientes
Cuando un cliente nos comparte su opinión acerca de la app de BBVA, obtenemos detalles sobre lo que le genera satisfacción o frustración y, más allá de esto, si está teniendo algún problema con alguna funcionalidad de la app, o alguna duda respecto a nuestros servicios.
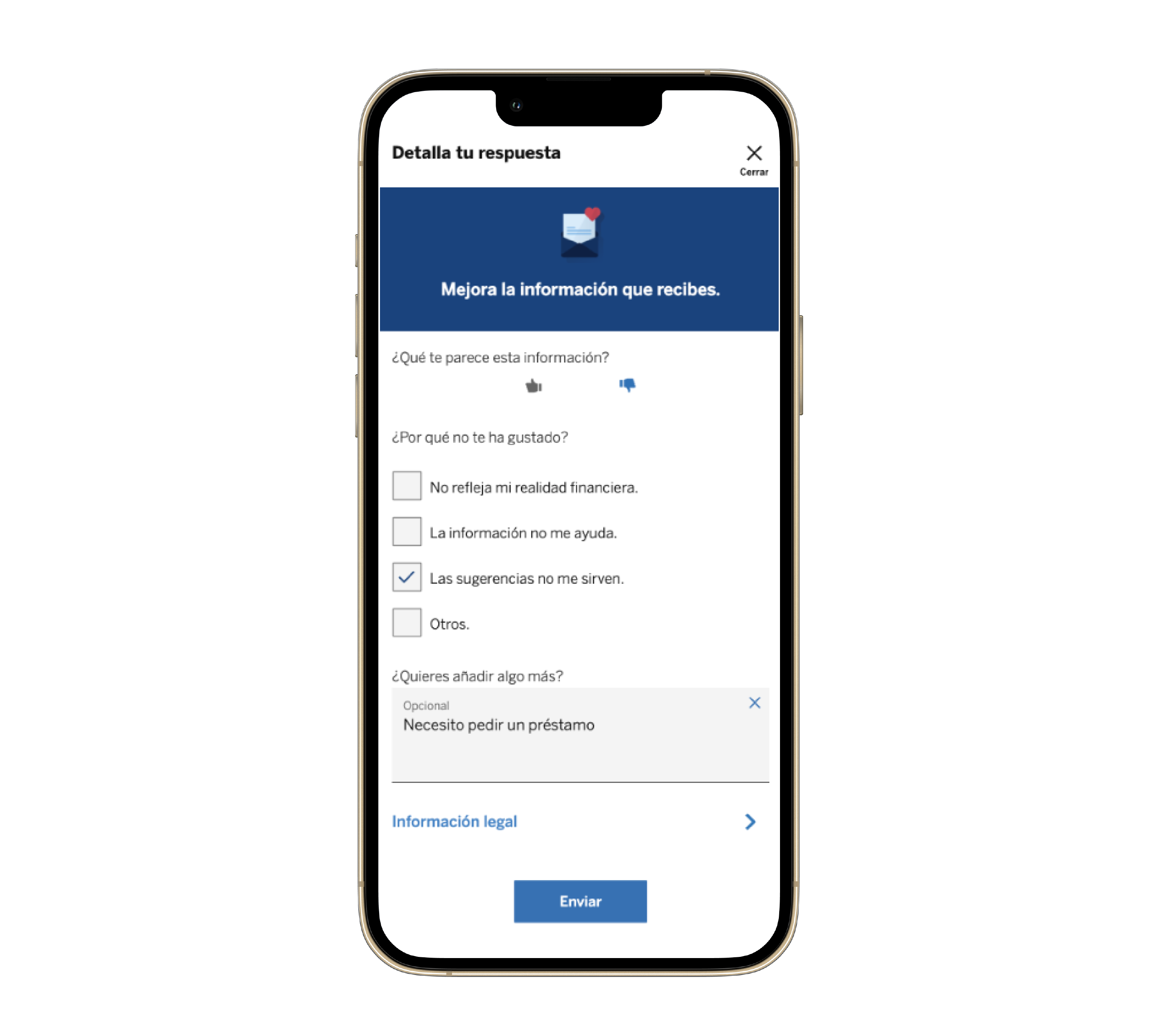
Analizar este tipo de feedback cualitativo, sin embargo, no es una tarea fácil. Los comentarios varían enormemente en longitud, tono y contenido, lo que complica su análisis coherente. Algunos combinan tanto opiniones positivas como negativas en un mismo mensaje, dificultando una clasificación precisa del sentimiento general.
En este sentido, analizar el sentimiento de los comentarios también puede ser complicado cuando incluyen sarcasmo o expresiones ambiguas, como: “¡Qué bien, siempre tardan en responder!”. Este tipo de frases pueden confundir a los algoritmos si no se interpretan correctamente.
Otro reto importante es que recibimos comentarios en diferentes idiomas y, por ende, de diferentes contextos culturales. Para analizar estos comentarios correctamente, necesitamos modelos que mantengan la precisión sin perder los matices de cada lengua. Además, solo una pequeña parte de los usuarios dejan comentarios escritos, lo que incide en la representatividad de los datos.
Finalmente, los modelos basados en arquitectura transformer como los sentence-transformers, aunque son muy buenos para entender el lenguaje natural, requieren muchos recursos computacionales, lo que puede ser un reto cuando se manejan grandes volúmenes de datos o se tiene hardware limitado.
Metodología
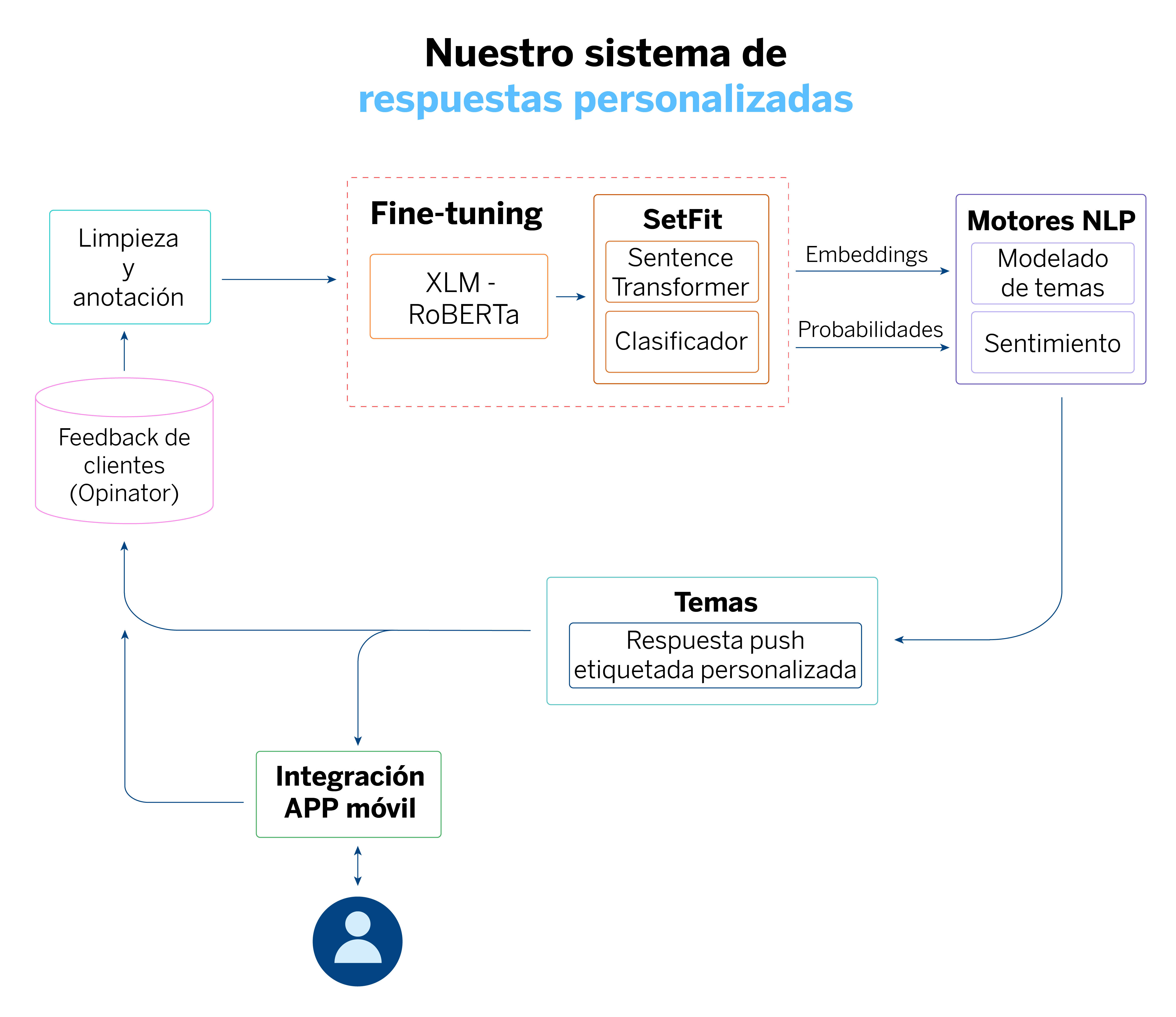
Para abordar estos desafíos, en BBVA hemos implementado un pipeline que combina técnicas avanzadas de NLP con algoritmos de reducción de dimensionalidad y clustering. Este pipeline nos permite analizar los comentarios en profundidad, estructurando y agrupando grandes volúmenes de texto.
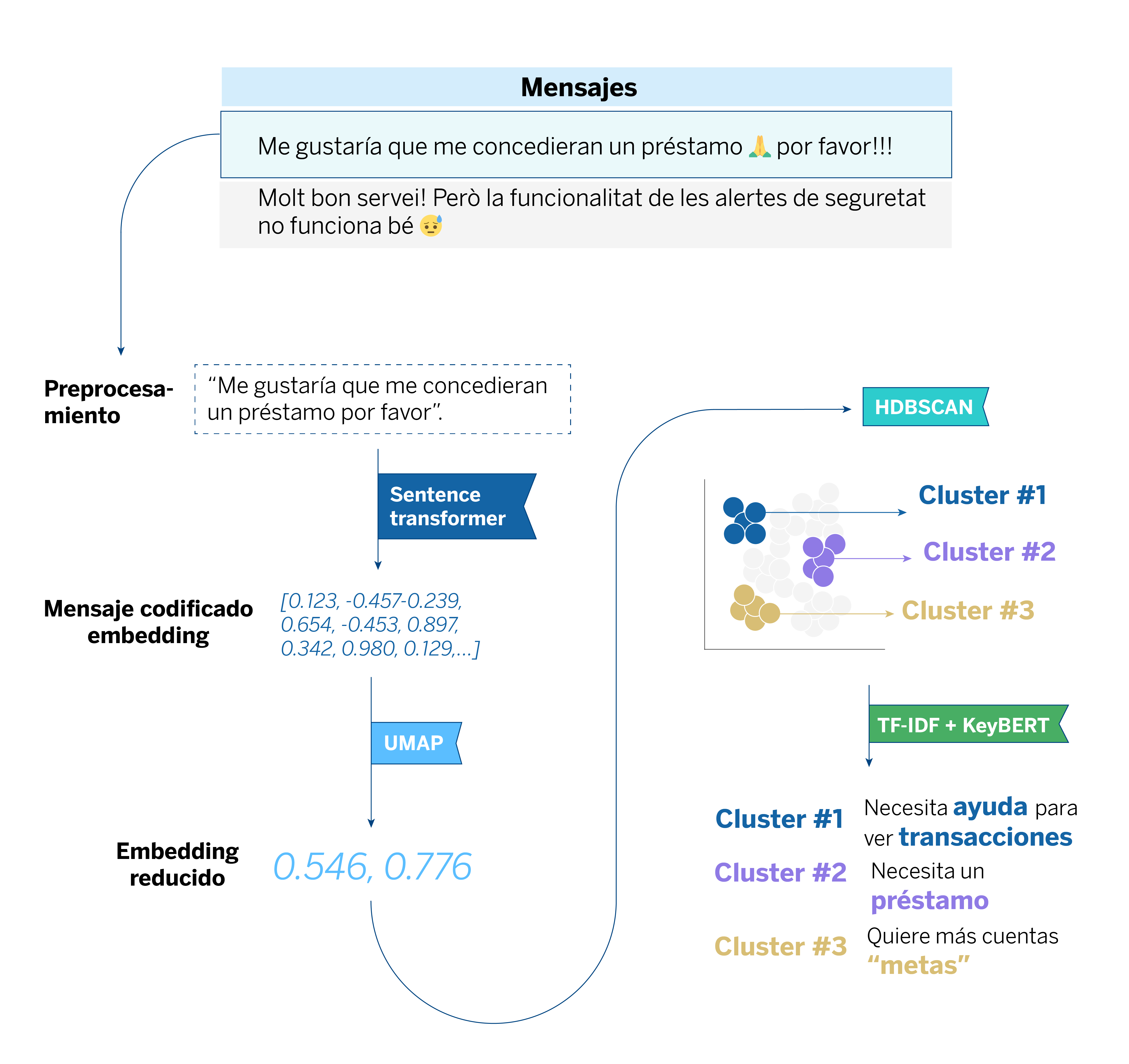
Todo comienza con la recopilación de los comentarios de los usuarios a través de diferentes cuestionarios dentro de la aplicación móvil de BBVA. Luego, pasamos al preprocesamiento de estos comentarios, eliminando elementos innecesarios y símbolos irrelevantes para que los modelos puedan entender el texto correctamente. Dado que recibimos comentarios en varios idiomas, utilizamos el modelo sentence-transformer basado en XLM-RoBERTa, que puede procesar diferentes lenguas sin necesidad de traducir los comentarios.
Generación de embeddings y fine-tuning
Una vez el dato está procesado, pasamos a analizar los comentarios. Primero los convertimos en datos numéricos mediante una técnica llamada embeddings, que básicamente transforma las palabras en números que los algoritmos pueden entender. Aquí destaca el modelo sentence-transformer, el cual empleamos por su excelente capacidad para capturar el significado de las frases.
Sin embargo, los modelos pre-entrenados no están optimizados para los comentarios específicos que recibimos en BBVA. Por eso, realizamos un proceso de fine-tuning con el framework SetFit, que nos permite ajustar el modelo con datos de nuestro dominio sin necesidad de disponer de GPUs.
Reducción de dimensionalidad y clustering
Una vez que hemos transformado los comentarios en embeddings, utilizamos una técnica de reducción de dimensionalidad no lineal: UMAP. Así, podemos reducir la complejidad de los datos al comprimir los vectores de embeddings en un espacio de menor dimensionalidad. Al reducir la dimensionalidad, preservamos la estructura local y global de los datos.
Esto facilita el siguiente paso, que es agrupar los comentarios en función de su similitud utilizando un algoritmo de clustering basado en densidad, HDBSCAN. A diferencia de otros algoritmos, HDBSCAN no requiere especificar el número de grupos de antemano, sino que los identifica automáticamente basándose en la densidad de los datos. Además, HDBSCAN puede identificar comentarios que no encajan en ningún grupo, tratándolos como “ruido”, lo que nos permite manejar datos irrelevantes o ruidosos de manera efectiva.
Extracción de palabras clave y etiquetado de temas
Una vez que tenemos los grupos de comentarios formados por HDBSCAN según la similitud entre ellos, el siguiente paso es entender de qué trata cada uno de estos grupos o clusters. Para esto, utilizamos KeyBERT y TF-IDF, que nos ayudan a identificar las palabras clave que mejor describen cada tema.
KeyBERT se basa en los embeddings generados por nuestro modelo, ajustado previamente con SetFit, para extraer palabras clave relevantes dentro de cada cluster. Por otro lado, TF-IDF nos permite ponderar la importancia de las palabras según su frecuencia dentro del grupo frente a su presencia en el conjunto de comentarios completo. Por ejemplo, si un grupo de comentarios se centra en problemas con el rendimiento de la app, estas herramientas nos lo señalan de manera clara, permitiéndonos tomar medidas rápidamente y priorizar las mejoras necesarias.
Resultados e impacto
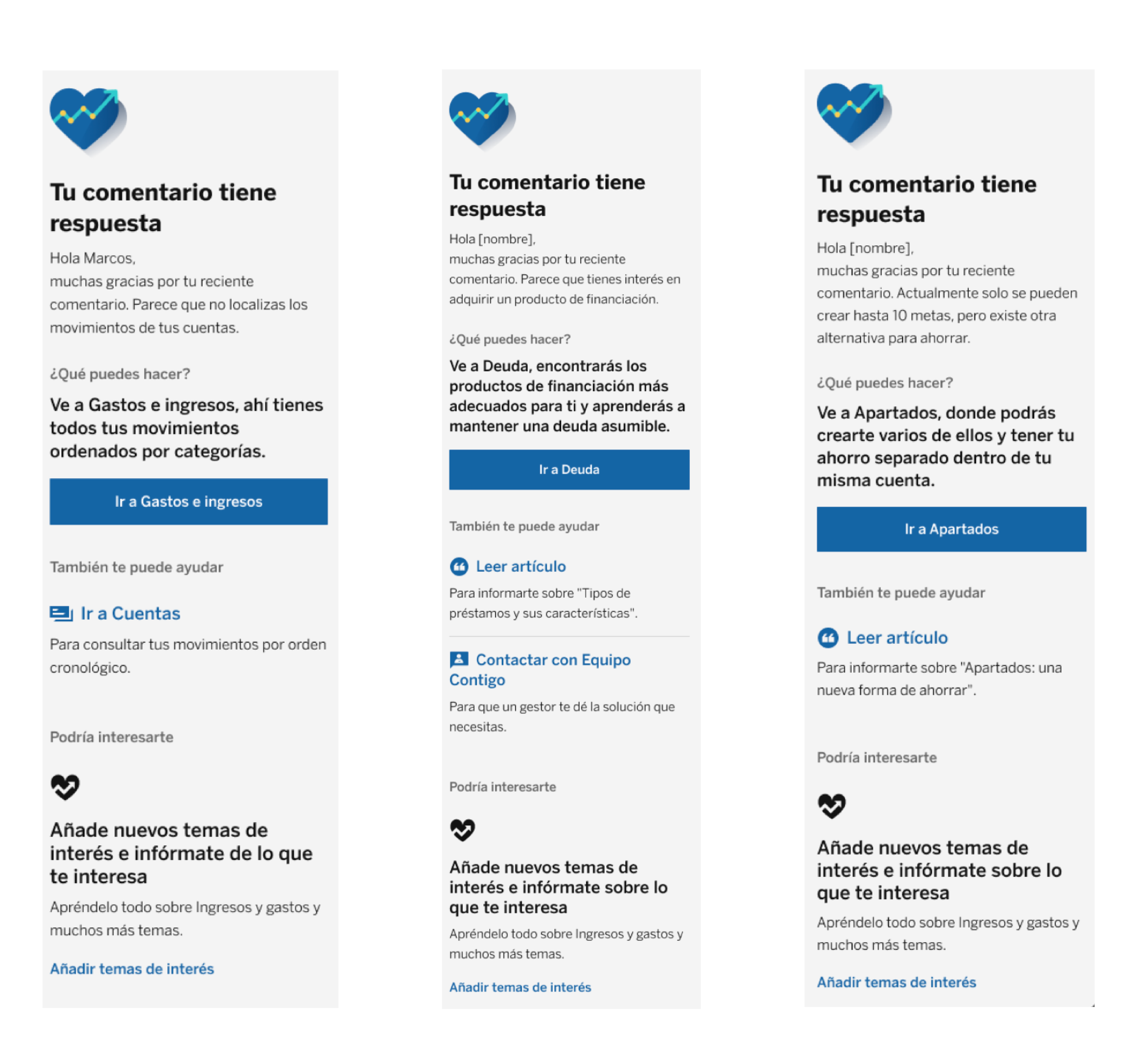
Este proceso nos permite clasificar los tipos de comentarios que recibimos y tomar acción frente a temas que son recurrentes en los mensajes de nuestros usuarios. Si bien esta metodología puede extrapolarse a diferentes proyectos y áreas del banco, la primera aplicación en la que efectivamente se aplica es en la generación de notificaciones push a través de la app de BBVA. Estas notificaciones tienen como destinatarios a aquellos clientes que nos han dejado comentarios en la app, específicamente en el área de salud financiera.
El sistema identifica automáticamente comentarios relacionados con temas como, por ejemplo, problemas para ver movimientos bancarios. A estos clientes se les envía una notificación explicando cómo acceder a sus movimientos y qué pasos pueden seguir para ver movimientos anteriores. Otro tema al que podemos dar respuesta tiene que ver con las solicitudes de más cuentas “metas”, en cuyo caso notificamos al cliente sobre la existencia de funcionalidades similares, como los “apartados”.
Estas notificaciones push tienen una latencia de D+1, lo que significa que el cliente recibe una respuesta personalizada dentro de las 24 horas posteriores a su comentario. Este sistema agiliza nuestra capacidad de respuesta; además, crea un feedback loop en el que evaluamos la reacción del cliente ante la notificación para mejorar continuamente el proceso.
Conclusiones
Las opiniones escritas por los clientes contienen una riqueza de información que las métricas tradicionales no pueden capturar, revelando el porqué detrás de sus percepciones.
Este enfoque basado en modelos avanzados de procesamiento de lenguaje natural nos permite desentrañar patrones y temas latentes en los comentarios, aportando claridad a una cantidad de datos que de otra manera sería imposible de procesar manualmente. A través de esta metodología, podemos pasar de una visión general a una comprensión profunda de las emociones, expectativas y frustraciones de los usuarios.
Lo más importante es que este proceso nos habilita para tomar decisiones más rápidas y alineadas con las necesidades reales de los clientes, así como darles respuesta de manera precisa.
El valor de este proceso radica en su capacidad para convertir el feedback desordenado y fragmentado en una fuente de conocimiento estructurada y accionable. Esto marca un antes y un después en la forma en que escuchamos a nuestros clientes y respondemos a sus expectativas.