
Así incorporamos datos de navegación a nuestros modelos para mejorar su rendimiento
Una de las aplicaciones más extendidas de la inteligencia artificial es el desarrollo de modelos analíticos que nos permiten ofrecer experiencias más personalizadas, así como recomendar los productos y servicios que mejor se adapten a las necesidades de los clientes. A medida que mejoramos el rendimiento de nuestros modelos, nuestras propuestas se vuelven más relevantes y adecuadas para cada persona.
En este artículo partimos de una hipótesis: la navegación de los usuarios en la app de BBVA constituye una información valiosa que puede mejorar significativamente el rendimiento de nuestros modelos y, por lo tanto, sus predicciones.
Para aprovechar esta información, primero transformamos los datos de navegación en embeddings, que son representaciones vectoriales que codifican estos datos de manera que los modelos puedan procesarlos fácilmente. Luego, integramos estos embeddings en nuestros modelos, haciendo los ajustes necesarios según los requerimientos de cada caso de uso.
A lo largo de este artículo, exploraremos cómo aplicar los embeddings de navegación en un caso concreto: el desarrollo de modelos de propensión, que nos ayudan a predecir la probabilidad de que un cliente adquiera un producto o servicio.
¿Cómo creamos los embeddings de cliente?
Un equipo de AI Factory se ha dedicado recientemente a explorar cómo transformar la navegación de un usuario en representaciones vectoriales, esto es, en embeddings, que sean fácilmente integrables en los modelos predictivos de BBVA.
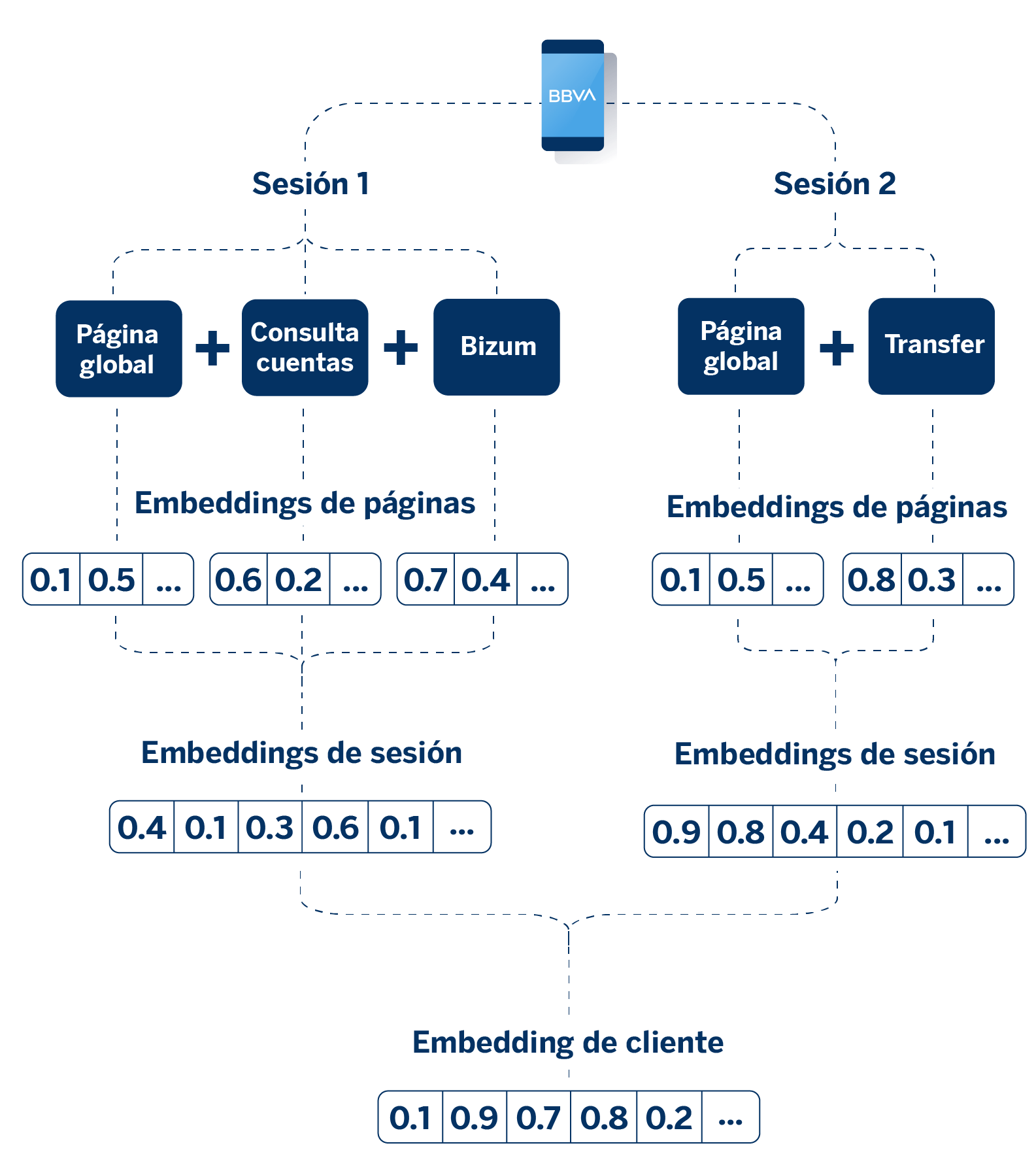
La navegación que realiza un usuario en la app de BBVA, es decir, su recorrido a través de las diferentes páginas, es una información que se puede convertir en una representación numérica. Esto se consigue a partir de un modelo matemático que captura las relaciones subyacentes entre los diferentes elementos de la navegación, de tal forma que el espacio matemático respete las relaciones existentes entre las páginas de la app.
Una vez que se tienen los embeddings de cada página visitada, estos pueden ser agregados de diversas formas (media, suma, transformaciones no lineales…) para representar interacciones más complejas. Por ejemplo, si un cliente navega por varias páginas durante su sesión, podemos agregar los vectores de esas páginas para crear un único embedding que represente toda una sesión de navegación. Este proceso de agregación nos permite condensar la información de múltiples interacciones en una representación única y coherente.
Siguiendo la misma lógica, cuando un usuario ha realizado varias sesiones de navegación, también es posible agregar los embeddings de todas estas sesiones para crear una representación única y completa de su comportamiento a lo largo del tiempo.
Aplicación a un caso de uso: Modelo de propensión de productos financieros
A continuación, haremos uso de los embeddings de navegación de cliente en un proyecto en concreto: el desarrollo de modelos de propensión. Estos modelos buscan predecir la probabilidad de que un cliente adquiera un producto o servicio, como un préstamo, una tarjeta de crédito o un seguro.
Para ello, parten de una serie de variables que describen el perfil, la situación financiera y el histórico del cliente. En este punto, la información de navegación en la app de BBVA puede ayudar a identificar preferencias e intereses del cliente.
Tradicionalmente, estas variables de navegación eran generadas mediante procesos ETL complejos a partir de hipótesis predefinidas. Ahora, al aplicar los embeddings de navegación, los modelos cuentan con nuevas variables que encapsulan información más completa y precisa de la navegación del cliente.
Esta información sobre la navegación que ofrecen los embeddings se puede utilizar en diferentes modelos y casos de uso, ahorrando tiempo y evitando procesos ad-hoc para cada nuevo proyecto.
Explicabilidad: el reto
La incorporación de embeddings plantea un desafío de explicabilidad. Al ser vectores en un espacio latente, no es sencillo desglosar qué significan exactamente cada una de sus dimensiones, dificultando la comprensión de los resultados del modelo por parte de la unidad de negocio.
Para abordarlo, se pueden aplicar técnicas de reducción de dimensionalidad y análisis de importancia de variables, o bien transformaciones intermedias (como veremos a continuación) que hagan más claras las etiquetas asociadas a cada grupo de interacciones. Con estas herramientas, es posible encontrar un equilibrio entre la potencia predictiva de los embeddings y la transparencia necesaria para la toma de decisiones.
Los requerimientos de explicabilidad en los modelos varían según el proyecto. En este caso, llevaremos a cabo varias de las operaciones mencionadas anteriormente, ya que necesitamos comprender qué información concreta recogen las variables en las que se basa el modelo para realizar sus predicciones.
Integrando embeddings al modelo de propensión: Workflow analítico
Aplicando el siguiente workflow analítico hemos conseguido mejorar el rendimiento del modelo de propensión mediante la incorporación de embeddings de navegación. A continuación, explicamos los pasos de este flujo de trabajo.
Modelo base: El punto de partida
Para empezar, es importante establecer un baseline o punto de referencia, el cual nos proporciona el modelo actual de propensión basado en variables tradicionales. En este modelo base, se utilizan 32 características o variables de entrada, una de las cuales es la cantidad de días que un cliente ha navegado en la aplicación. Esta variable se destaca como una de las más importantes, lo que nos lleva a la hipótesis de que las variables relacionadas con la navegación podrían tener un impacto significativo en la predicción.
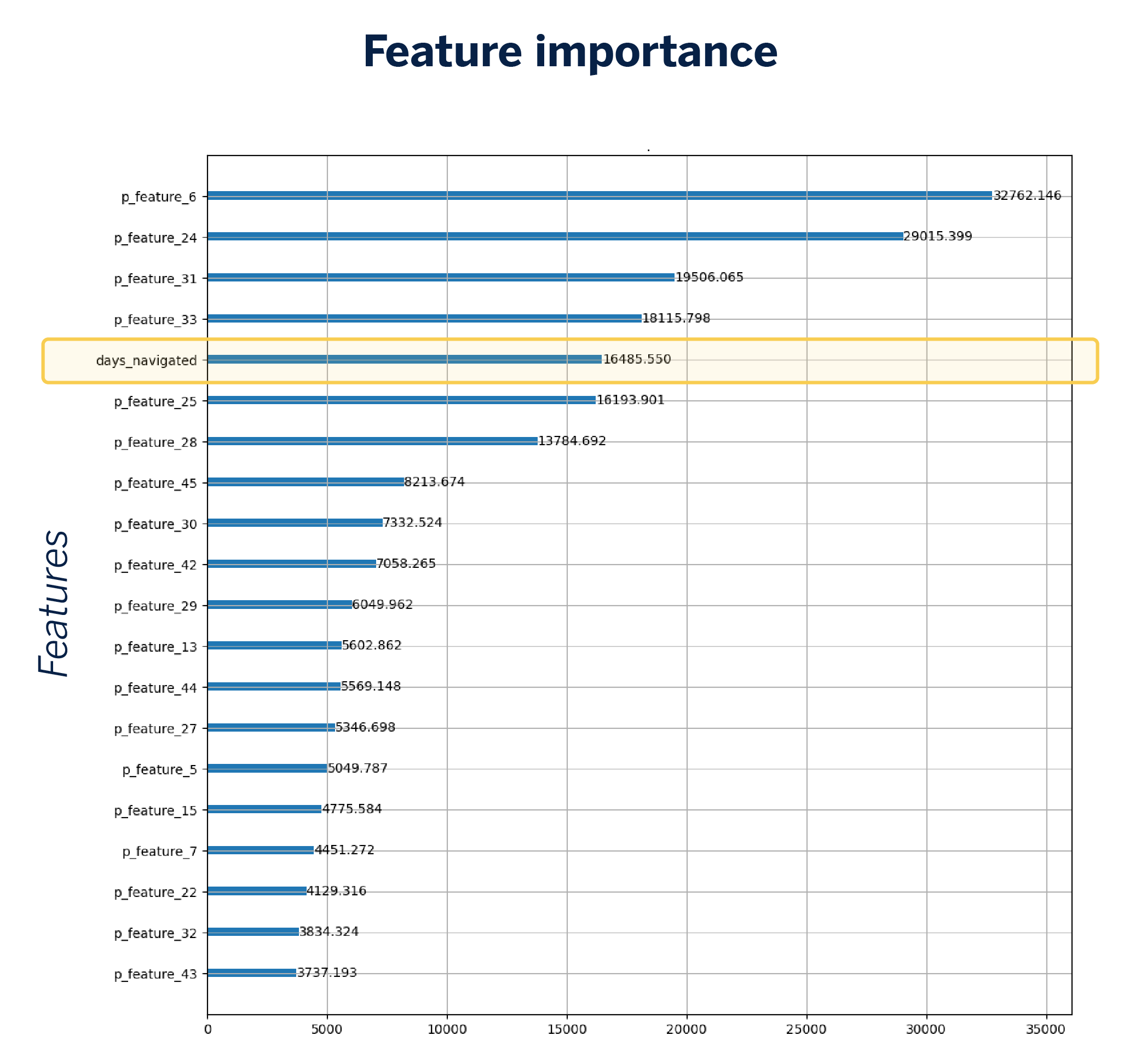
Introducción de embeddings de navegación: Potenciando el modelo existente
Lo primero que haremos es incluir en nuestro modelo la representación vectorial de la navegación del usuario, es decir, los embeddings que hemos calculado anteriormente, mientras mantenemos las variables de navegación tradicionales. Estos embeddings amplían el espacio de entrada, lo que da como resultado un aumento en el número de variables del modelo, pasando de 32 a 72.
Al introducir los embeddings, se observa un ligero aumento en el AUC, lo que indica que el modelo está mejorando en términos de rendimiento. A través de un gráfico de importancia de variables, es posible observar que ciertas dimensiones de los embeddings se posicionan como variables relevantes, lo que demuestra su capacidad para capturar patrones significativos en los datos de navegación.
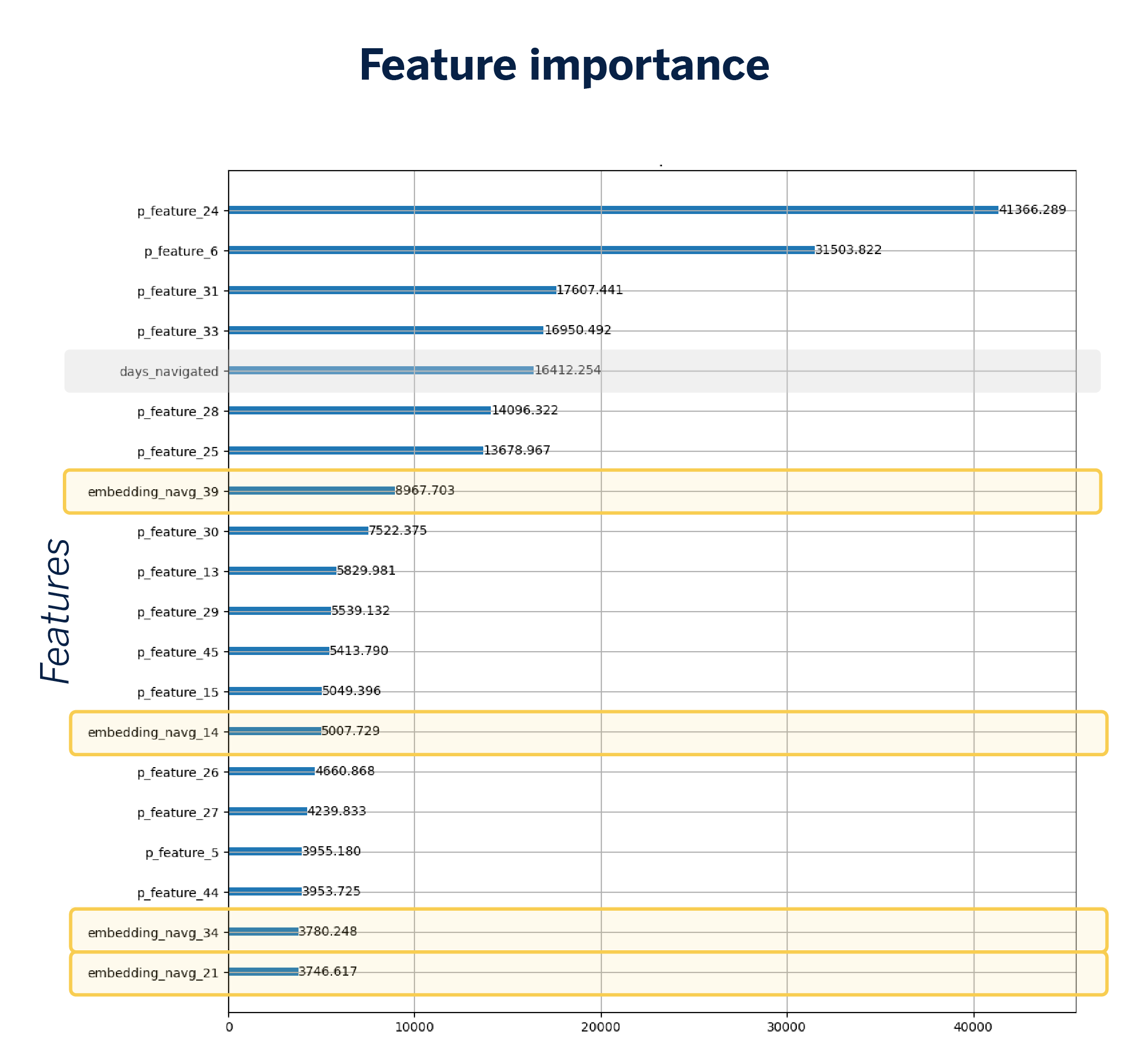
Sin embargo, en este punto surge el reto de la explicabilidad. Debido a que no sabemos qué representa cada dimensión del embedding, tampoco podremos explicar los resultados obtenidos a la unidad de negocio de forma satisfactoria.
NavTagging: Solucionando la explicabilidad
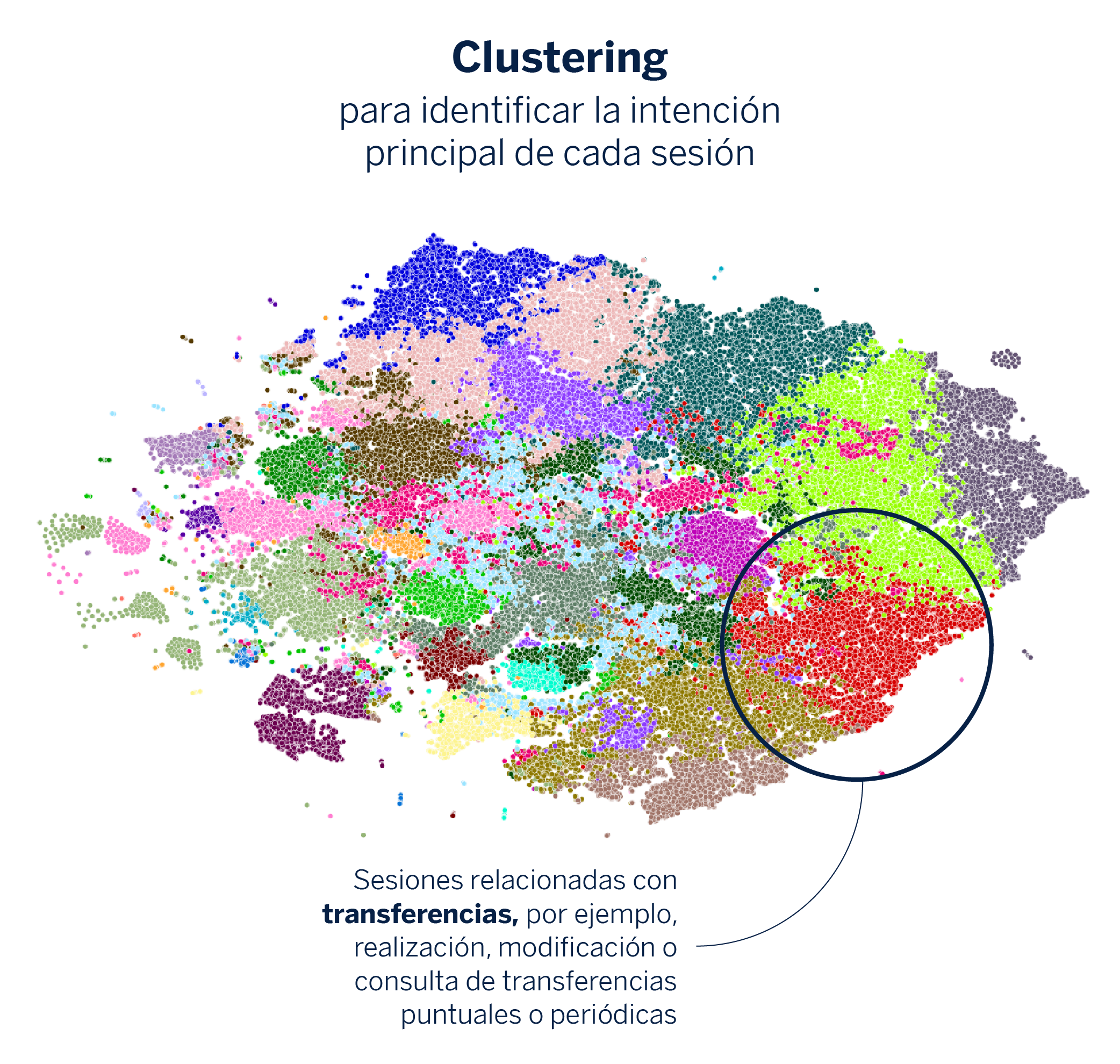
Para abordar el reto de la explicabilidad, se introduce el concepto de NavTagging, que consiste en etiquetar las sesiones de navegación de los clientes de manera que sean comprensibles.
Como hemos visto anteriormente, los embeddings que hemos generado encapsulan la información sobre el recorrido que hace un cliente por las páginas de la app durante una sesión. En este paso, lo que hacemos es agrupar los embeddings utilizando algoritmos de clustering, donde cada grupo o cluster representa una operativa similar. Este ejercicio nos permite detectar y diferenciar sesiones por su objetivo o finalidad principal, como hacer una transferencia o consultar el saldo de la cuenta.
Representación del cliente: De las sesiones a la caracterización
A continuación, representamos la información del conjunto de sesiones realizadas por un usuario como un vector. Pero ahora, este nuevo vector contiene la información de los clusters generados en el paso anterior, y además también incluye la información del número de veces que el cliente realizó cada tipo de sesión.
En este escenario, las dimensiones del vector se vuelven explicables porque las podemos asociar con una finalidad de sesión determinada, por ejemplo, hacer una transferencia o consultar el saldo.. Así, ya no estamos trabajando con un vector “opaco”, sino con una representación que podemos entender fácilmente.
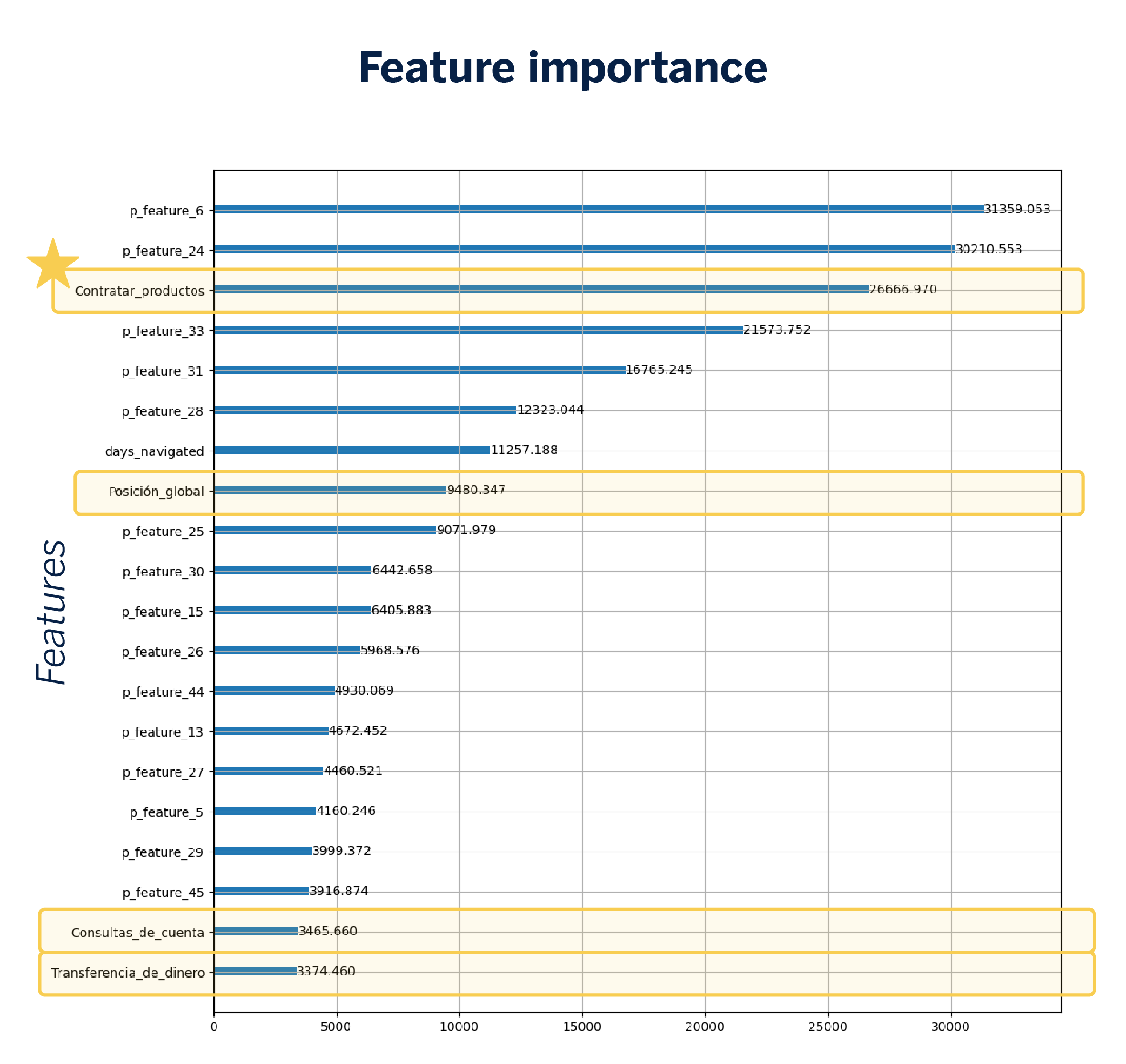
Este nuevo vector se integra en el modelo de propensión y podemos evaluar cómo influye en la predicción. Al hacer esto y retirar el embedding inicial (ya que su información está ahora contenida en el nuevo vector), el número de variables del modelo se sitúa en 70. Dado que cada dimensión del vector representa una etiqueta independiente, podemos seleccionar libremente qué variables incluir en el modelo.
Esta nueva representación permite que el modelo sea más preciso y, a su vez, más fácil de explicar, ya que las variables ahora son autoexplicativas y no requieren de un análisis complejo para comprender su impacto.
Conclusiones y aprendizajes
Al incorporar los embeddings y las etiquetas de navegación en el modelo, se observa un aumento en el AUC y una mejora en el rendimiento del modelo. Con la introducción de NavTagger, la interpretación de las variables se vuelve mucho más clara y coherente, ya que las dimensiones de los embeddings ahora se corresponden con intenciones concretas del cliente, lo que facilita la comprensión y la comunicación de los resultados a negocio. A continuación, una serie de aprendizajes:
01: La alta dimensionalidad puede ser un problema
Los embeddings ofrecen una compresión de información que permite representar datos complejos en un espacio vectorial que nos permite operar con ellos. Sin embargo, esta representación suele darse con alta dimensionalidad. Esto puede ser un desafío, ya que puede requerir grandes cantidades de recursos computacionales y dificultar la convergencia en determinados modelos.
02: La cualidad reutilizable y adaptable de los embeddings puede ayudarnos
Una vez que los embeddings son calculados y entrenados, se pueden aplicar fácilmente a otros proyectos o modelos sin necesidad de realizar cálculos repetidos. Además, los embeddings poseen una gran flexibilidad y potencial para ajustarse a diferentes contextos.
03: Persiste la necesidad de explicabilidad
Justificar los resultados obtenidos sigue siendo un reto, especialmente cuando se trabaja con espacios latentes donde cada dimensión es abstracta y no fácilmente interpretable. Este problema se puede mitigar con técnicas de reducción de dimensionalidad y clustering, como hemos visto en este ejercicio.