
Aplicando Transfer Learning a modelos de lenguaje natural
Dentro de la Inteligencia Artificial, el Procesamiento de Lenguaje Natural (NLP por sus siglas en inglés) ha sido uno de los campos clave desde los orígenes. Al fin y al cabo, el lenguaje es una de las cosas más ligadas a la inteligencia humana. En los últimos años este campo ha sufrido una nueva revolución semejante a la que hace 20 años supuso la introducción de las técnicas estadísticas y de aprendizaje automático (Machine Learning). Esta revolución la abanderan nuevos modelos basados en redes neuronales profundas que facilitan la codificación de la información lingüística y la posibilidad de reutilización en diversas aplicaciones. Con la aparición en 2018 de modelos de lenguaje auto-supervisados como BERT (Google), entrenados sobre una ingente cantidad de texto, se inicia una época en la que la Transferencia de Aprendizaje (Transfer Learning) empieza a ser una realidad práctica para NLP, tal y como lo ha sido para el campo de la Visión Artificial desde 2013.
El concepto de Transferencia de Aprendizaje se basa en la idea de reutilizar el conocimiento adquirido realizando una tarea para abordar nuevas tareas que son similares. En realidad, es una práctica que los humanos llevamos a cabo constantemente en nuestro día a día. Aunque afrontamos nuevos retos, nuestra experiencia nos permite abordar los problemas desde un estadío más avanzado.
La mayoría de algoritmos de aprendizaje automático (Machine Learning), en particular si son supervisados, solo pueden resolver la tarea para la que han sido entrenados mediante ejemplos. Si lo llevamos al mundo culinario, el algoritmo sería como un cocinero súper especializado, entrenado para realizar una única receta. Pedirle una receta diferente a este algoritmo puede tener consecuencias no deseadas, como realizar predicciones incorrectas o incorporar sesgos.
El objetivo de utilizar Transferencia de Aprendizaje es que nuestro cocinero -que es el mejor cocinando ravioli carbonara- sea capaz de aplicar lo aprendido para alcanzar un éxito razonable cocinando unos spaguetti a la boloñesa. Aunque la salsa sea diferente, puede reutilizar el conocimiento adquirido a la hora de cocer la pasta (figura 1).

Este mismo concepto de reutilización de conocimiento, aplicado al desarrollo de modelos de Procesamiento de Lenguaje Natural (NLP), es el que hemos explorado en una colaboración con Vicomtech, un Centro de Investigación del País Vasco especializado en técnicas de interacción humano-máquina basadas en inteligencia artificial. En concreto, el objetivo de este trabajo conjunto ha sido conocer las aplicaciones que tiene la Transferencia de Aprendizaje y valorar los resultados que ofrecen estas técnicas, pues vemos que pueden ser aplicables en las interacciones en lenguaje natural entre clientes y gestores de BBVA. Después de todo, el propósito que perseguimos con este trabajo no es otro que mejorar la forma en la que nos relacionamos con nuestros clientes.
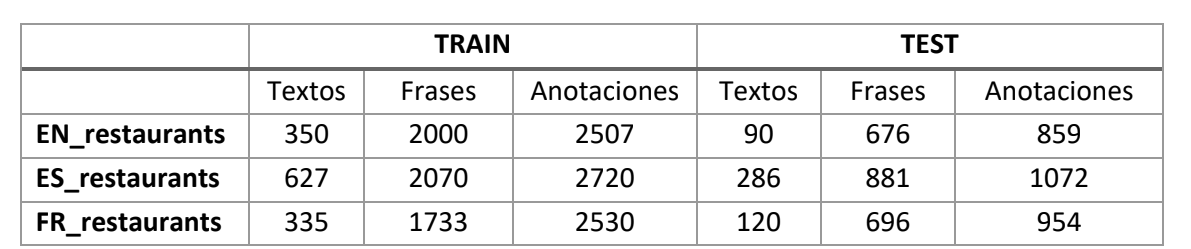
Una de las tareas que hemos abordado ha consistido en el procesamiento de información textual en diferentes idiomas. Para ello, hemos utilizado conjuntos de datos de dominio público. Es el caso de un dataset de opiniones de restaurantes, generado para la competición académica Semeval 2016, que incluye reseñas en inglés, español, francés, ruso, turco, árabe y chino. El objetivo ha sido identificar los diferentes aspectos o características que se mencionan (comida, ambiente o servicio al cliente, entre otros), en inglés, español y francés. En la siguiente tabla se muestra el volumen de datos de los distintos idiomas.
Con este ejercicio queríamos validar si las técnicas de Transferencia de Aprendizaje basadas en el uso de modelos BERT eran apropiadas para adaptar un clasificador multiclase que detectase los aspectos en diferentes idiomas. Frente a este enfoque, existen alternativas basadas en la traducción del texto para adaptarla a un único idioma. Esto lo podemos hacer traduciendo la información que utilizaremos para entrenar el modelo, por un lado, o bien traduciendo directamente las conversaciones de los clientes que queremos clasificar. Sin embargo, estas alternativas también encierran problemas e ineficiencias.
Recuperando el ejemplo culinario que comentábamos al inicio de este artículo, en nuestro caso podríamos considerar que el texto del que disponemos son los ingredientes de la receta. Estos “datasets” de información son diferentes de un idioma a otro (de igual modo que los ingredientes varían según la receta). Por otro lado, la capacidad adquirida por el modelo para clasificar los textos es un conocimiento que podemos reutilizar en varios idiomas; del mismo modo que reutilizamos el conocimiento sobre cómo cocer la pasta en recetas diferentes.
En este experimento hemos partido de un modelo pre-entrenado BERT multilingüe de dominio público, y hemos realizado un ajuste fino (fine tuning) sobre el dataset de restaurantes. En la siguiente figura se muestra el procedimiento (figura 2).
Los resultados obtenidos adaptando este modelo, entrenado con dato genérico, al dataset de reseñas en cada idioma, fueron similares a los reportados en 2016 para la tarea en inglés, francés y español por modelos más especializados. Esto es consistente con los resultados de diferentes trabajos de investigación sobre la capacidad de este tipo de modelos de alcanzar muy buenos resultados.
Una vez ajustado un clasificador para texto en inglés, el proceso de Transferencia de Aprendizaje entre idiomas lo llevamos a cabo realizando una segunda etapa de fine tuning con el dataset del segundo idioma (figura 3).
Para medir la efectividad del proceso comparamos el comportamiento de este clasificador con el comportamiento resultante de realizar una única etapa de ajuste fino partiendo del modelo base multilingüe.
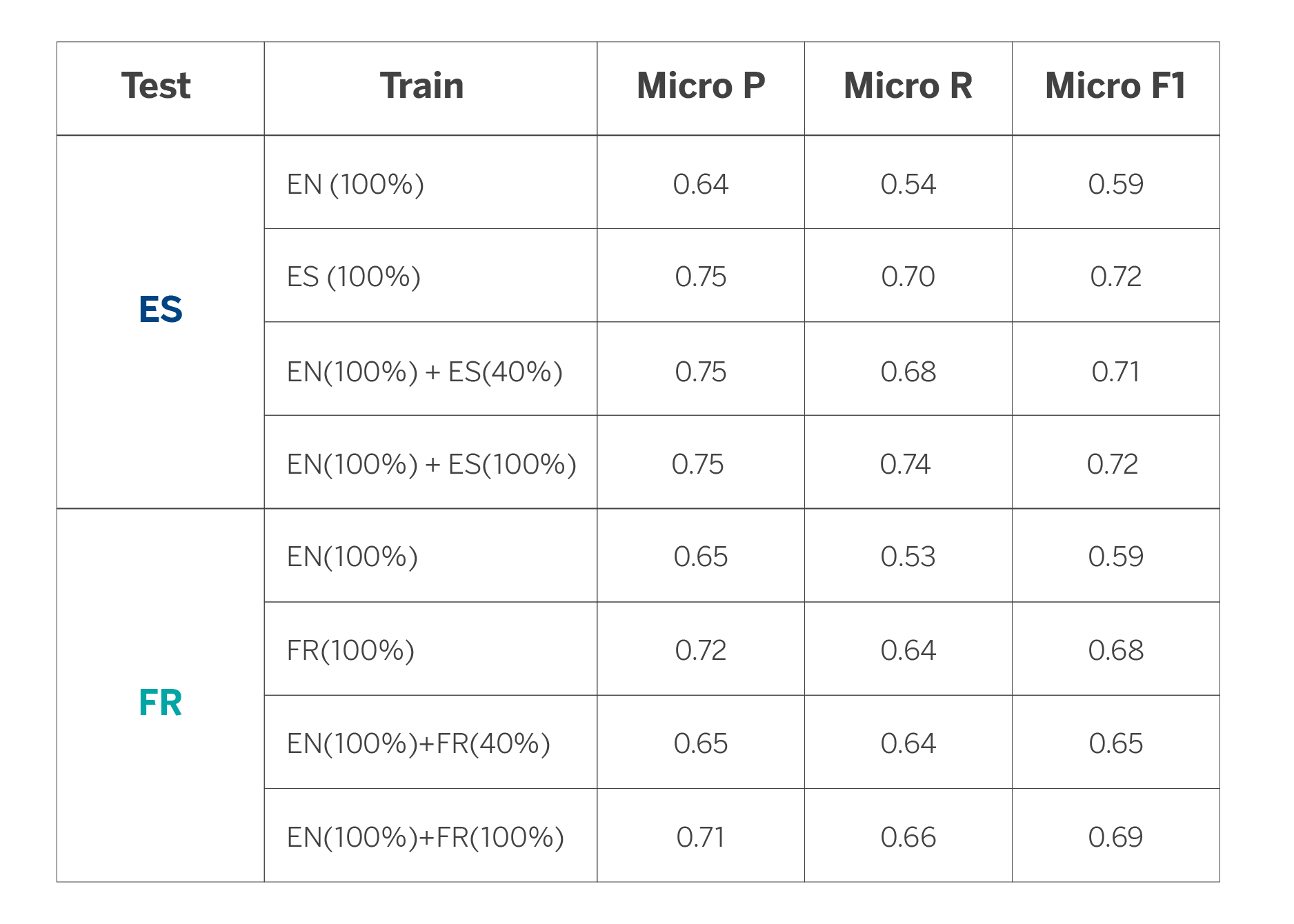
Los resultados nos indican (ver tabla 2) que, partiendo del modelo en inglés y utilizando menos datos del idioma de destino (español o francés, en este caso) podemos alcanzar resultados similares a los que obtenemos al adaptar un modelo para cada idioma. Por ejemplo, en el caso del español, alcanzamos un desempeño muy similar si partimos del modelo en inglés y añadimos sólo el 40% de dato en español. Por otro lado, en el caso del francés, los resultados se empiezan a igualar al utilizar el modelo en inglés y el 80% del dato en francés. Por último, si utilizamos todos los datos disponibles, los resultados mejoran de forma moderada si los comparamos con los resultados que alcanzamos al entrenar solo con los datos de cada idioma. En cambio, la mejora es notable respecto a usar el modelo en inglés para el resto de idiomas. Es importante tener en cuenta que estos resultados van a depender de la tarea concreta en la que se aplican.
Los diferentes resultados obtenidos con este experimento son muy esperanzadores desde el punto de vista de aplicación en problemas reales, ya que nos estarían indicando que los modelos son capaces de utilizar el conocimiento adquirido en un idioma para extrapolarlo a otro, obteniendo la misma calidad con menos dato etiquetado. De hecho, uno de los principales obstáculos al desarrollar cualquier funcionalidad de NLP en un entorno industrial es disponer de una gran cantidad de datos de calidad, y tener que desarrollarlo para cada uno de los idiomas. Por lo tanto, requerir de menos dato etiquetado siempre es una gran ventaja a la hora de desarrollar las funcionalidades.
El conocimiento obtenido a raíz de esta colaboración con Vicomtech nos va a permitir, de esta forma, construir de forma más ágil funcionalidades de ayuda al gestor en su relación con el cliente, permitiendo reducir el ciclo de desarrollo de un caso de uso en un idioma o canal distinto a aquel en el que originalmente se implementó.