
Una recapitulación de la conferencia AWS re:Invent 2021
⎋ Ver hilo en twitter
El pasado mes de diciembre tuvimos la oportunidad de asistir presencialmente al AWS re:Invent 2021 y conocer de primera mano las novedades anunciadas por Amazon Web Services, especialmente aquellas relacionadas con el aprendizaje automático.
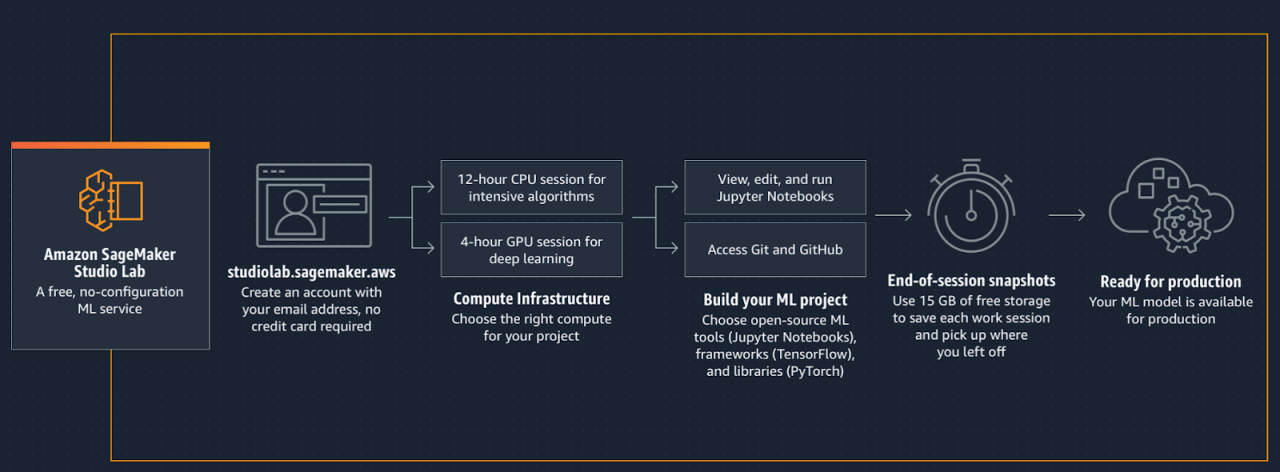
SageMaker Studio Lab
Es la versión simplificada y gratuita de SageMaker Studio. Es un entorno de desarrollo de aprendizaje automático que proporciona almacenamiento persistente (hasta 15 GB) y capacidad de cómputo (CPU y GPU, con 16 GB de RAM) de manera gratuita. Además, permite la integración con el resto de herramientas de AWS mediante los SDK de Python (tanto Sagemaker SDK como Boto3), por lo que permite prototipar de manera fácil y sin costo, para luego utilizar el resto de recursos de AWS cuando sea necesario. Por otra parte, también es una opción adicional para aprender y poner en práctica el aprendizaje automático, además de Google Colab y los notebooks de Kaggle. Recomendamos este post donde se realizan pruebas ingeniosas para comparar los tres entornos.
SageMaker Inference Recommender
Este nuevo servicio es capaz de ejecutar múltiples pruebas automáticamente relacionadas a la inferencia de modelos y recomendar al usuario: el tipo de instancia de cómputo, el número de instancias, valores de parámetros de configuración de los contenedores que alojan el código para inferencia, entre otras cosas. Esto permite tomar decisiones de forma objetiva y basada en evidencia, respecto al despliegue de modelos para optimizar costos, y también permite ahorrar tiempo valioso a los desarrolladores.
⎋ Anuncio
⎋ Ejemplos en repositorio
⎋ Vídeo

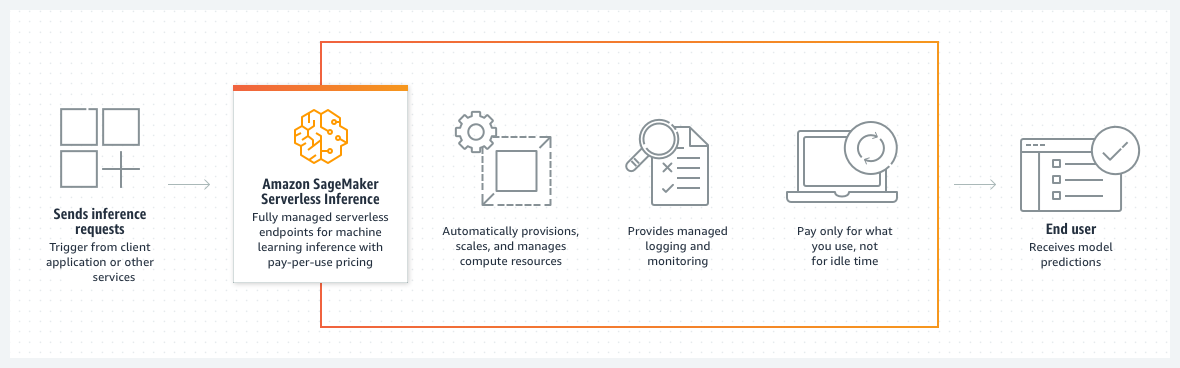
SageMaker Serverless Inference
Este nuevo servicio integra Lambda y SageMaker, y está diseñado para realizar inferencias en aplicaciones con tráfico intermitente o impredecible. Hasta antes de este servicio, las opciones de inferencia en SageMaker eran inferencia en tiempo real, inferencia en batch, e inferencia asíncrona. Ahora, la nueva opción Serverless Inference es capaz de encargarse automáticamente de aprovisionar y escalar la capacidad de cómputo basada en el volumen de solicitudes.
⎋ Anuncio
⎋ Ejemplos en repositorio
⎋ Vídeo
SageMaker Canvas
Esta es una herramienta visual y sin código, diseñada para que los analistas de negocio y otros perfiles menos técnicos sean capaces de construir y evaluar modelos, así como realizar predicciones sobre nuevos datos, a través de una interfaz de usuario intuitiva. Además, los modelos generados en Canvas pueden ser compartidos después con los científicos de datos y desarrolladores para tenerlos disponibles en SageMaker Studio.
SageMaker Ground Truth Plus
Este es un nuevo servicio de etiquetado para crear conjuntos de datos de alta calidad para utilizarlos en el entrenamiento de modelos de aprendizaje automático. Ground Truth Plus utiliza técnicas innovadoras de la comunidad científica, como el aprendizaje activo, el pre-etiquetado y la validación automática. Mientras que SageMaker Ground Truth ya existía desde 2019, permitiendo al usuario crear los flujos de trabajo de etiquetado de datos y administrar al personal encargado del etiquetado, SageMaker Ground Truth Plus crea y administra estos flujos de trabajo de manera automática sin necesidad de la intervención del usuario.
SageMaker Training Compiler
Esta nueva característica de SageMaker compila automáticamente el código de entrenamiento de modelos escrito en algún framework de aprendizaje automático basado en Python (TensorFlow o PyTorch) y genera kernels de GPU específicos para esos modelos. En otras palabras, SageMaker Training Compiler convierte los modelos desde su representación de lenguaje de alto nivel a instrucciones optimizadas para hardware, de modo que utilizarán menos memoria y menos cómputo y, por lo tanto, su entrenamiento será más rápido.
⎋ Anuncio
⎋ Ejemplos en repositorio
⎋ Vídeo
EMR on SageMaker Studio
Esta nueva característica integra EMR y SageMaker Studio. Antes de esta característica, los usuarios de SageMaker Studio tenían cierta capacidad para buscar clústeres de EMR ya creados y conectarse a ellos, siempre que estos clústeres se estuvieran ejecutando en la misma cuenta que la sesión de SageMaker Studio. Sin embargo, los usuarios no podían crear clústeres desde SageMaker Studio, sino que para hacer esto tenían que realizar la configuración manualmente desde EMR. Además, estar restringido a crear y administrar clústeres en una sola cuenta podría volverse prohibitivo en las organizaciones que trabajan con muchas cuentas de AWS. Ahora, con esta nueva característica, los usuarios de SageMaker Studio pueden administrar, crear, y conectarse a clústeres de Amazon EMR desde SageMaker Studio, además de conectarse y monitorizar trabajos de Spark que se ejecuten en estos clústeres.
⎋ Anuncio
⎋ Ejemplos en repositorio
Más allá de los anuncios
Además de los anuncios de las nuevas funcionalidades en SageMaker que tuvieron lugar en el evento, existen otras características que no son precisamente nuevas pero de las cuales tuvimos la oportunidad de conocer algo durante el evento a través de presentaciones, workshops, o charlas informales. Aquí comentamos un poco sobre algunos aspectos.
RStudio on SageMaker
Esta característica es resultado de la colaboración entre AWS y RStudio PBC y fue anunciada en noviembre de 2021. Como resultado de esta colaboración, ahora el entorno de desarrollo RStudio está disponible en SageMaker, sumándose a la opción del entorno SageMaker Studio, el cual está basado en el proyecto JupyterLab. Con esta adición, ahora los científicos de datos y los desarrolladores tienen la libertad de elegir entre lenguajes de programación e interfaces para cambiar entre RStudio y Amazon SageMaker Studio. Todo el trabajo desarrollado en cualquiera de los dos entornos (código, conjuntos de datos, repositorios y otros artefactos) se sincroniza a través del almacenamiento subyacente en Amazon EFS.
⎋ Anuncio de AWS
⎋ Anuncio de RStudio PBC
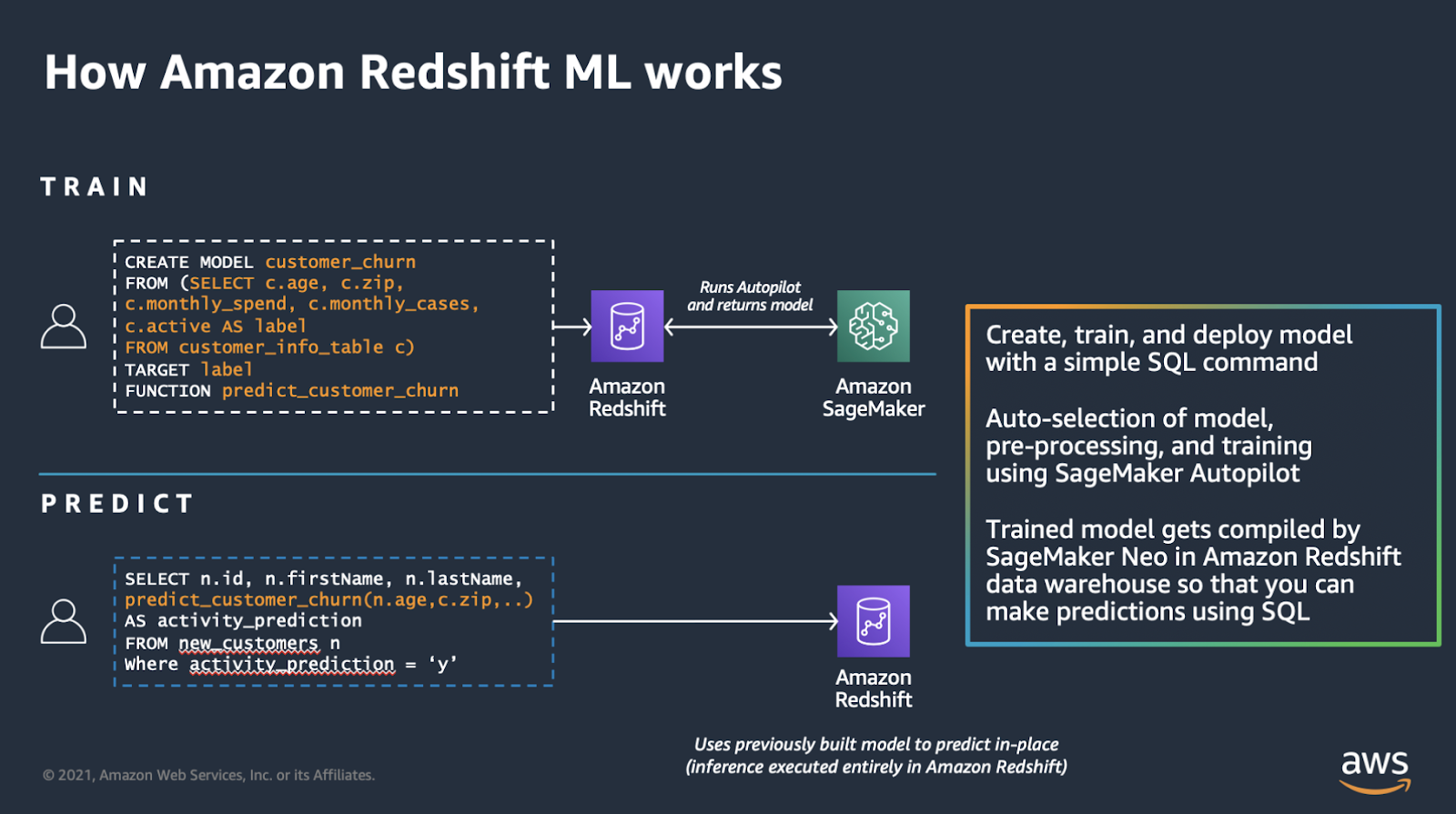
Redshift ML
Este servicio fue anunciado en diciembre de 2020 y es una integración entre Redshift y SageMaker. Básicamente se trata de hacer entrenamiento, evaluación, y despliegue de modelos desde Redshift mediante instrucciones SQL, utilizando SageMaker como backend.
AutoML en AWS
En AWS existen dos iniciativas relacionadas al aprendizaje automático automatizado (AutoML): SageMaker Autopilot y AutoGluon de AWS Labs (vídeo).
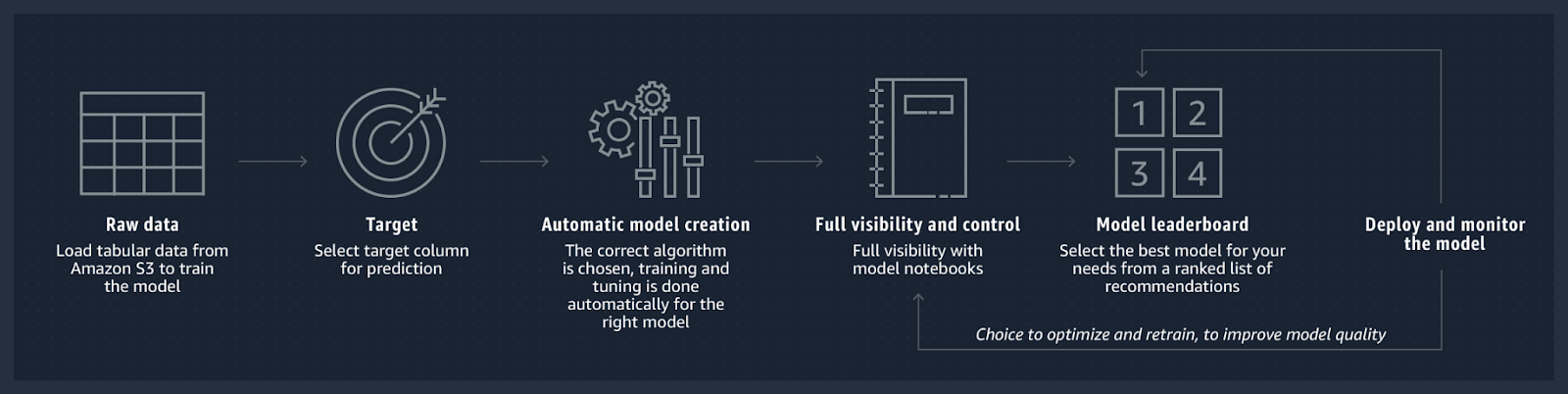
SageMaker Autopilot fue anunciado en diciembre de 2019 por lo que lleva ya algún tiempo en el mercado. Se refiere a la solución comercial de AWS para hacer aprendizaje automático automatizado (AutoML) y se puede utilizar de varias formas: en piloto automático (de ahí el nombre) o con varios grados de guía humana (sin código a través de Amazon SageMaker Studio, o con código usando alguno de los SDK de AWS).
Una característica destacable es que Autopilot crea tres informes automáticos en notebooks que describen el plan que se ha seguido: uno relacionado a la exploración de datos, otro relacionado a la definición de los modelos candidatos, y otro relacionado a las métricas de desempeño de los modelos finales. A través de estos informes, el usuario tiene acceso al código fuente completo para preprocesamiento y entrenamiento de los modelos, por lo que el usuario tiene la libertad de analizar cómo los modelos fueron construidos y también de hacer modificaciones para mejorar el desempeño. Es decir, a comparación de otras soluciones comerciales de AutoML disponibles en el mercado, Autopilot es una herramienta (en su mayoría) de caja blanca.
Autopilot tiene estrategias predefinidas para la selección de algoritmos dependiendo del tipo de problema, y en cuanto a cómo se hace la optimización de hyperparámetros, Autopilot utiliza estrategias basadas en búsquedas aleatorias y en optimización Bayesiana. Más información aquí. Es decir, Autopilot sigue estrategias que entran dentro del paradigma conocido como Combined Algorithm Selection and Hyperparameter optimization (“CASH”), el cual a grandes rasgos consiste en emplear estrategias para simultáneamente encontrar el mejor tipo de algoritmo y sus respectivos hyperparámetros óptimos.
⎋ Anuncio
⎋ Ejemplos en repositorio
⎋ Vídeo
AutoGluon es un proyecto de código abierto, orientado a investigación y también listo para producción, impulsado por AWS Labs y que fue publicado hacia finales de 2019. En palabras de uno de sus autores, AutoGluon automatiza el aprendizaje automático y el aprendizaje profundo para aplicaciones que involucran imágenes, texto y conjuntos de datos tabulares, y que simplifica el trabajo tanto para principiantes como para expertos en aprendizaje automático. Soporta tanto CPU como GPU para backend. AutoGluon es un proyecto amplio que contiene diversos módulos:
- Predicción tabular1
- Predicción de texto
- Predicción de imágenes
- Detección de objetos
- Tuning (de hyperparámetros, de argumentos de scripts de Python, y más)
- Búsqueda de arquitecturas neuronales
Una característica bastante innovadora y poderosa de AutoGluon es que introduce sus capacidades de predicción de texto y de predicción de imágenes dentro de su módulo de predicción tabular, permitiendo tener la opción de Tablas Multimodales (ejemplo y tutorial aquí). Esto es útil en casos de uso en donde se cuenta simultáneamente con datos tanto de tipo numérico, categórico, texto, e imágenes, o cualquier combinación de ellos.
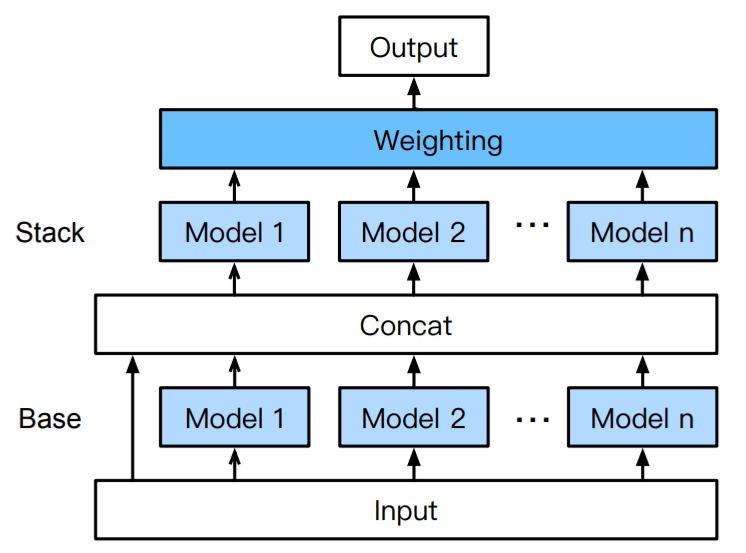
Hablando concretamente del módulo de predicción tabular y de su enfoque para hacer AutoML, AutoGluon toma una dirección alternativa al paradigma CASH (haciéndolo diferente tanto de SageMaker Autopilot como del resto de proyectos de código abierto como auto-sklearn y H2O AutoML) al seguir un enfoque de ensamblar y apilar modelos (de diferentes familias y de diferentes frameworks) en múltiples capas, inspirado en prácticas que se sabe que son efectivas en la comunidad de aprendizaje automático (por ejemplo, en competencias de Kaggle). A estas ideas, AutoGluon añade también otras técnicas:
- Una estrategia para reducir la varianza en las predicciones y reducir el riesgo de sobreajuste (ensemble bagging, también llamado cross-validated committees)2. Este proceso es altamente paralelizable y en AutoGluon está implementado haciendo uso de Ray.
- Una estrategia para combinar modelos de manera óptima en la última capa del ensamble 3.
- Una estrategia para destilar el modelo complejo del ensamble final en algún modelo individual más simple4 que imite el desempeño del modelo complejo y que sea más ligero (y por lo tanto tenga menor latencia en tiempo de inferencia).
⎋ Anuncio
⎋ Repositorio
⎋ Artículo en Amazon Science
⎋ Vídeo
Además, AutoGluon se puede utilizar tanto para entrenamiento como para despliegue en SageMaker:
⎋ Ejemplo AutoGluon en SageMaker
⎋ AutoGluon en AWS Marketplace
Por último, también destacar que AutoGluon puede integrarse con Nvidia Rapids, concretamente con cuML (característica anunciada en el Nvidia GTC 2021 como colaboración entre AWS Labs y Nvidia) para mayor aceleración para entrenamiento con GPUs: