
Explicabilidad algorítmica: ¿cómo la aplicamos en BBVA AI Factory?
Etimológicamente, la palabra “explicar” proviene del latín “explicare”, la cual está formada por la partícula ex (sacar, mover del interior hacia el exterior) y plicare (hacer pliegues). Semánticamente su significado hace alusión a desenrollar algo plegado para que quede visible y patente. Esto es lo que en AI Factory hacemos con los modelos de aprendizaje automático: desentrañarlos para mirar dentro de ellos y, así, desenredar su complejidad para arrojar luces sobre su funcionamiento.
La inteligencia artificial explicable (XAI, por sus siglas en inglés, eXplainable AI) ha adquirido relevancia en los últimos tiempos por servir como puente entre las decisiones algorítmicas y los encargados de su desarrollo. El objetivo general de la implementación de técnicas de explicabilidad es, por un lado, comprender la lógica detrás de los modelos de aprendizaje automático y, por otro, traducir a lenguaje humano el funcionamiento de los algoritmos.
Casos de uso: diferentes aplicaciones de la explicabilidad
Para nosotros es crucial garantizar la transparencia en el uso de sistemas de aprendizaje automático. Por ello, el uso de técnicas de explicabilidad está ampliamente extendido entre los equipos de AI Factory, incluso hemos desarrollado un paquete dentro de nuestra librería de ciencia de datos, Mercury, que está disponible para todos. En un artículo anterior contamos toda la información sobre mercury-explainability. Hoy hacemos un recorrido por diversos casos de uso en los que se aplica la explicabilidad.
Explicabilidad para traducir las decisiones algorítmicas en lenguaje de negocio
Uno de los objetivos que perseguimos al aplicar técnicas de explicabilidad es hacer comprensibles las decisiones que sugieren los algoritmos tanto por los stakeholders como por los usuarios finales. Cada vez que creamos y entrenamos un modelo de aprendizaje automático, es fundamental explicar al área de negocio el porqué toma una decisión u otra.
Un ejemplo claro de esto ocurre cuando creamos algoritmos que personalizan la experiencia de los clientes en la aplicación móvil del banco. La personalización implica que el entorno de la aplicación se ajustará a la situación financiera y movimientos transaccionales de cada cliente. A partir de los datos de un usuario, el modelo decidirá qué aviso, acción o sugerencia se ajusta mejor a cada usuario, por lo que habrá una correlación entre el cliente y lo que muestra la interfaz de la aplicación móvil.
Dicha correlación tiene en cuenta variables individuales que afectarán en mayor o en menor medida a la predicción. En esta línea, la explicabilidad se aplica de dos maneras: por un lado, para entender cómo aprende el modelo cuando se entrena y, por otro lado, para extraer el peso de las variables y en qué medida afectan a la predicción.
La primera aplicación de la explicabilidad tiene en cuenta los feature importance scores, los cuales determinan la importancia relativa de cada variable en un conjunto de datos. El resultado que ofrece permite conocer cuáles son las features o características que más influyen durante el aprendizaje del modelo. Esto es especialmente útil cuando se quieren explicar los datos con los que se entrena el modelo.
La mayoría de los modelos utilizados en AI Factory contienen inherentemente los feature importance scores. En el caso en el que se utilicen modelos que no los disponibilicen, existen métodos agnósticos para obtenerlas independientemente del modelo que utilicemos. Un ejemplo es el método de Permutation Feature Importance, basado en los cambios que sufre el error de predicción cuando existe un cambio en el orden de las features que utiliza el modelo.
La segunda aplicación tiene que ver con SHAP (SHapley Additive exPlanations), un conjunto de técnicas de explicabilidad que asignan un valor de relevancia o contribución de cada feature a una predicción. SHAP se basa en el cálculo de los shapley values, un método de teoría de juegos cooperativos, donde cada feature o un conjunto de ellos tiene rol de jugador. De esta forma, sabemos cómo se reparte la predicción (recompensa del juego) entre los diferentes features (jugadores)1.
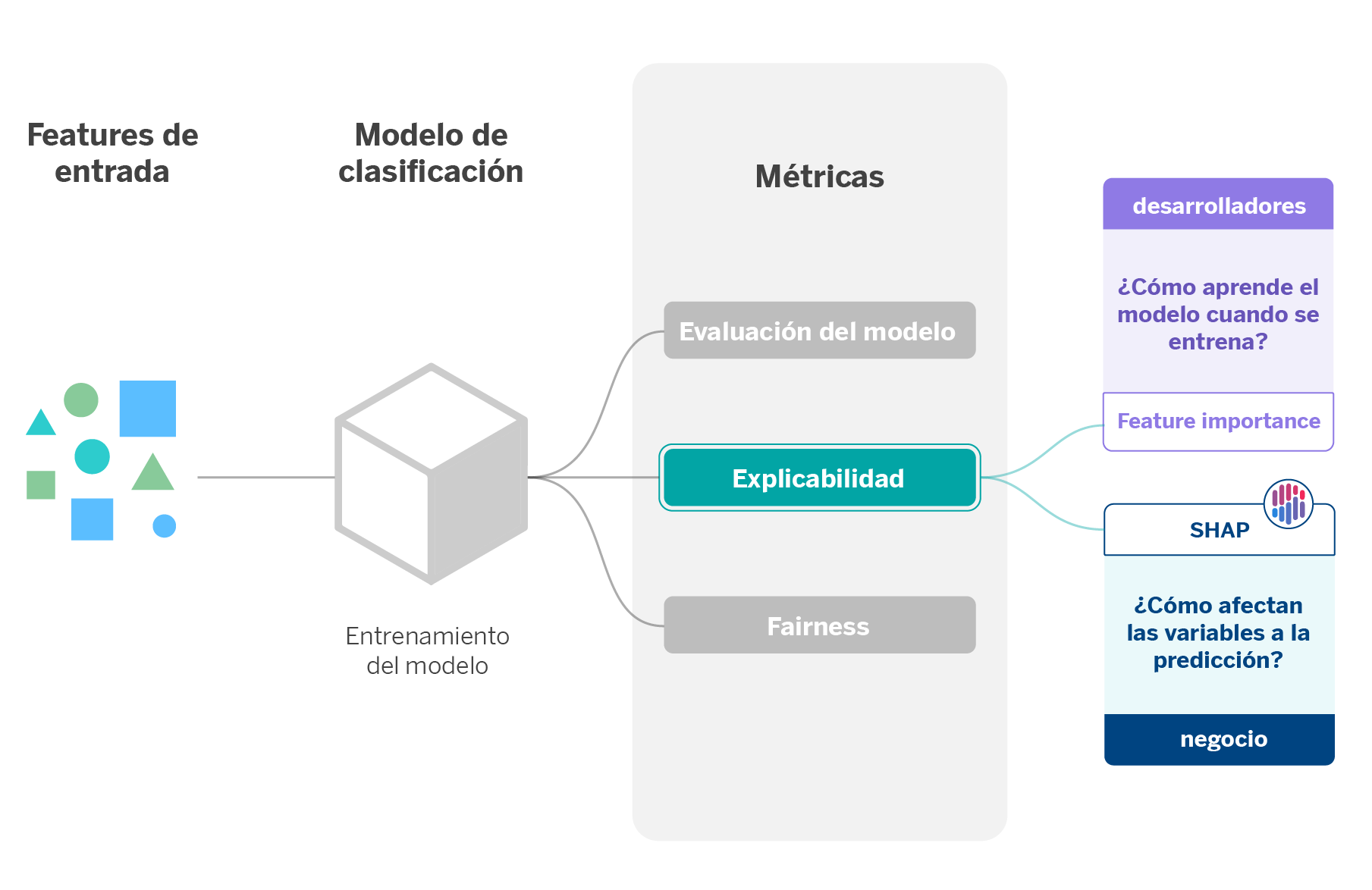
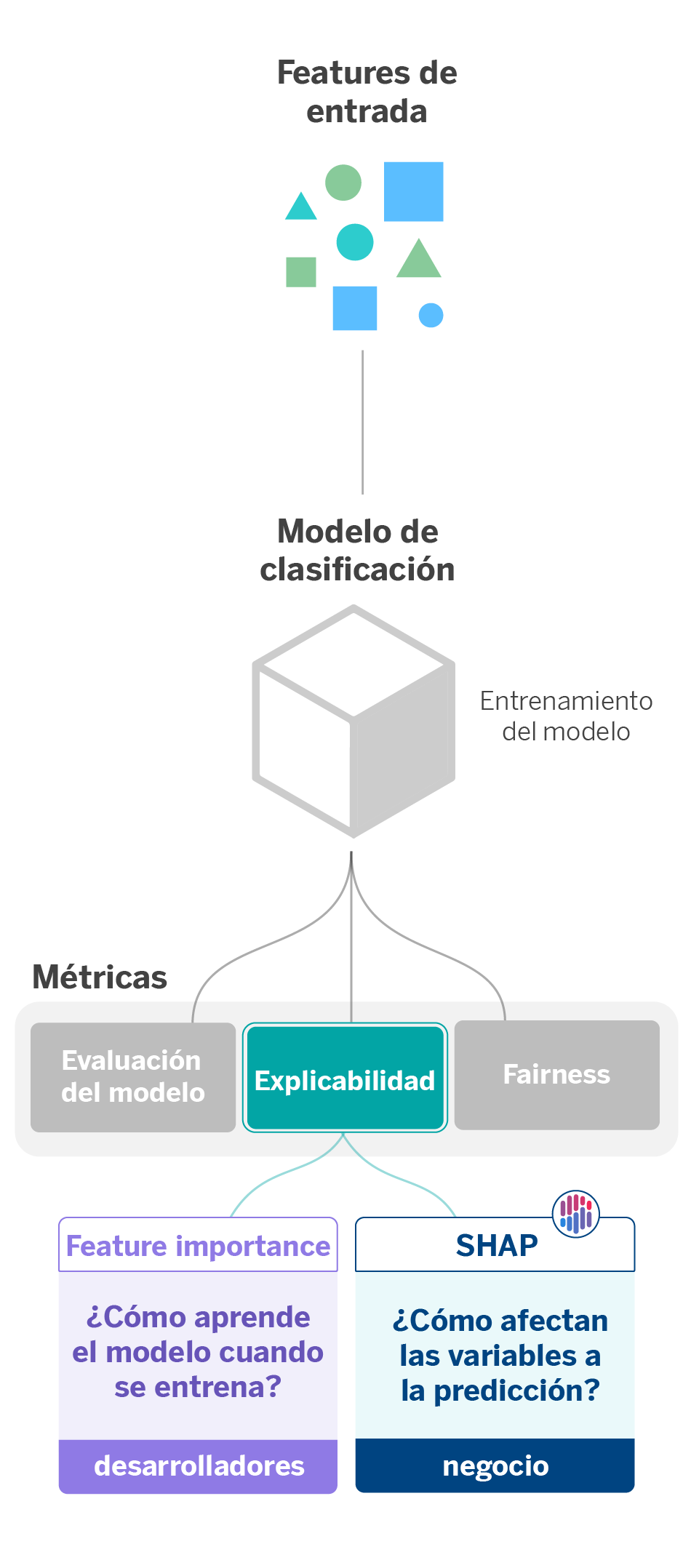
Entre los beneficios de SHAP destacamos las alternativas que ofrece, las cuales nos ayudan a obtener explicabilidad de nuestros modelos como si se tratasen de una caja negra (KernelSHAP) o en el caso de que estos sean modelos basados en árboles (TreeSHAP).
En este caso concreto utilizamos SHAP para explicar a negocio cómo las variables influyen en la predicción de cada clase del modelo de personalización, denotando cuáles afectan más y en qué medida. Así, se puede justificar el porqué de una decisión u otra para un cliente u otro.

Explicabilidad para interpretar problemas no supervisados
Cuando desarrollamos modelos de aprendizaje automático, existen dos paradigmas: los modelos supervisados y los no supervisados. El aprendizaje supervisado parte de un conjunto de datos de entrenamiento que buscan enseñar al modelo qué salida u output debería generar para un caso concreto. Por otro lado, en el aprendizaje no supervisado los datos no están etiquetados previamente, por lo que no hay un conocimiento a priori sobre ellos. Por ello, la salida del modelo es una decisión que toma el algoritmo a partir de los patrones comunes y diferenciales que encuentra en los datos.
Una de las ventajas principales de los modelos no supervisados es que evitan los sesgos que pueden darse al etiquetar manualmente los datos. Así, estos modelos exploran todo el universo de correlaciones existentes entre las variables para entrenarse de manera automática. Sin embargo, resulta fundamental explicar el porqué de las decisiones que toma el algoritmo para así validar su funcionamiento y fiabilidad.
Una aplicación de este enfoque explicable ocurre cuando realizamos segmentación de clientes. Dada la inmensa cantidad de datos con los que trabajamos, en AI Factory abordamos esta tarea haciendo uso de modelos de clustering.
Los clustering son técnicas de aprendizaje no supervisado que agrupan las observaciones de un conjunto de datos a partir de rasgos en común. En nuestro caso, lo aplicamos para clasificar al universo de colectivos de clientes para diferenciarlos entre ellos. Algunos factores que facilitan la creación de los clústeres son la edad, la ocupación y datos transaccionales.
Visualmente, los clústeres pueden estar bien diferenciados entre sí, pero siempre existirán muestras que puedan encajar en otros clústeres por su distribución. Para detectar anomalías en los clústeres –evitando las reglas manuales ya existentes– y así poder afinar el universo que cada uno comprende, aplicamos un algoritmo de detección de anomalías. Se trata de una técnica de inteligencia artificial de tipo árbol sencilla y rápida de aplicar, pero no del todo interpretable. Cuando la aplicamos, nos surgen dudas como: ¿por qué el algoritmo considera anómala una determinada observación? ¿Cómo puede interpretarse el resultado? ¿El modelo considera algunas variables más relevantes que otras?
Las salidas de los modelos de detección de anomalías son puntuaciones mediante las cuales el modelo ordena el grado de anomalía que detecta para cada una de las observaciones. Para interpretar dichos resultados a nivel local hacemos uso de SHAP, que, como hemos visto, otorga pesos a cada una de las variables o features que intervienen en la creación de los modelos. Dichos pesos, los shapley values, permiten comprender mejor cómo funciona el modelo y qué parámetros contribuyen en mayor o menor medida al resultado.
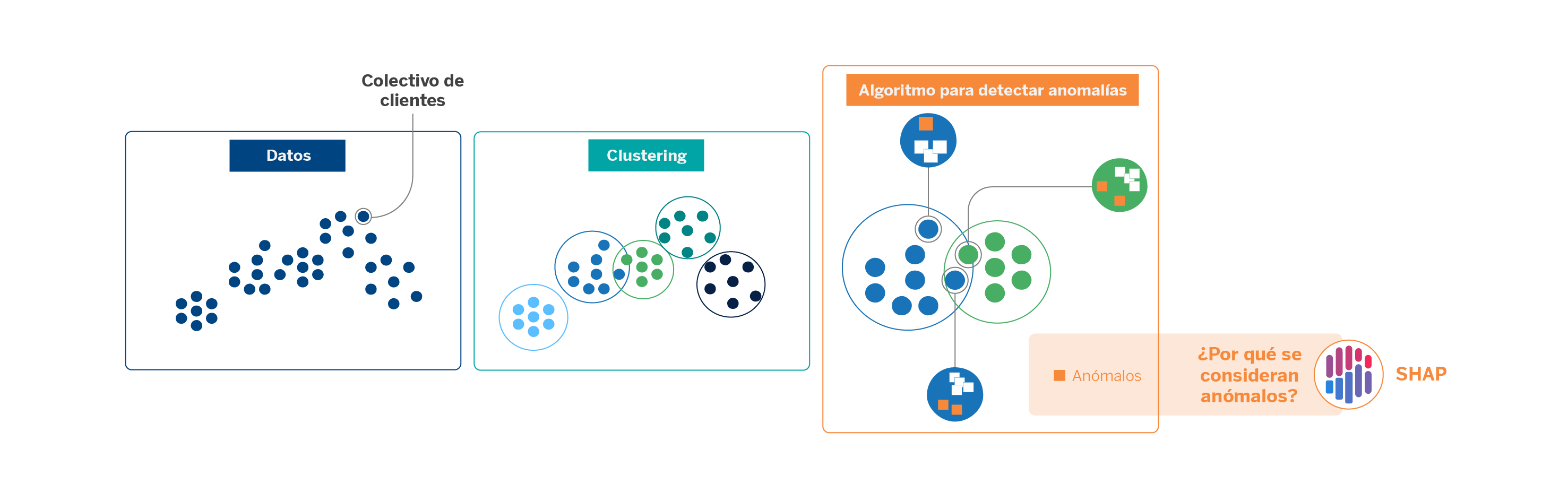
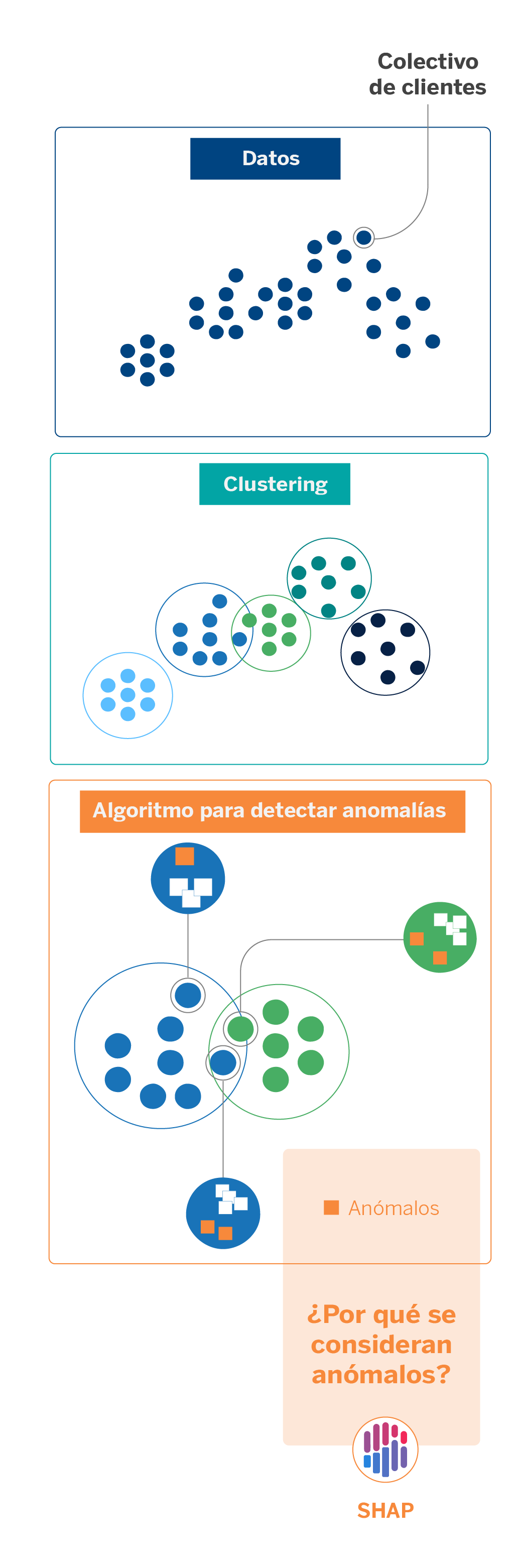
En este sentido, el uso de técnicas de explicabilidad nos ayuda a validar modelos que, por su naturaleza no supervisada, suelen ofrecer buenos resultados pero poco interpretables. Así, podemos paliar la incertidumbre de algoritmos entendidos como “caja negra” y garantizar la transparencia, auditabilidad y trazabilidad de los resultados que ofrecen.
Explicabilidad para mejorar los modelos
En AI Factory también aplicamos métodos de explicabilidad para depurar modelos. Si conseguimos saber qué variables influyen más en las decisiones que toma el modelo, seremos capaces de optimizarlo para obtener mejores métricas.
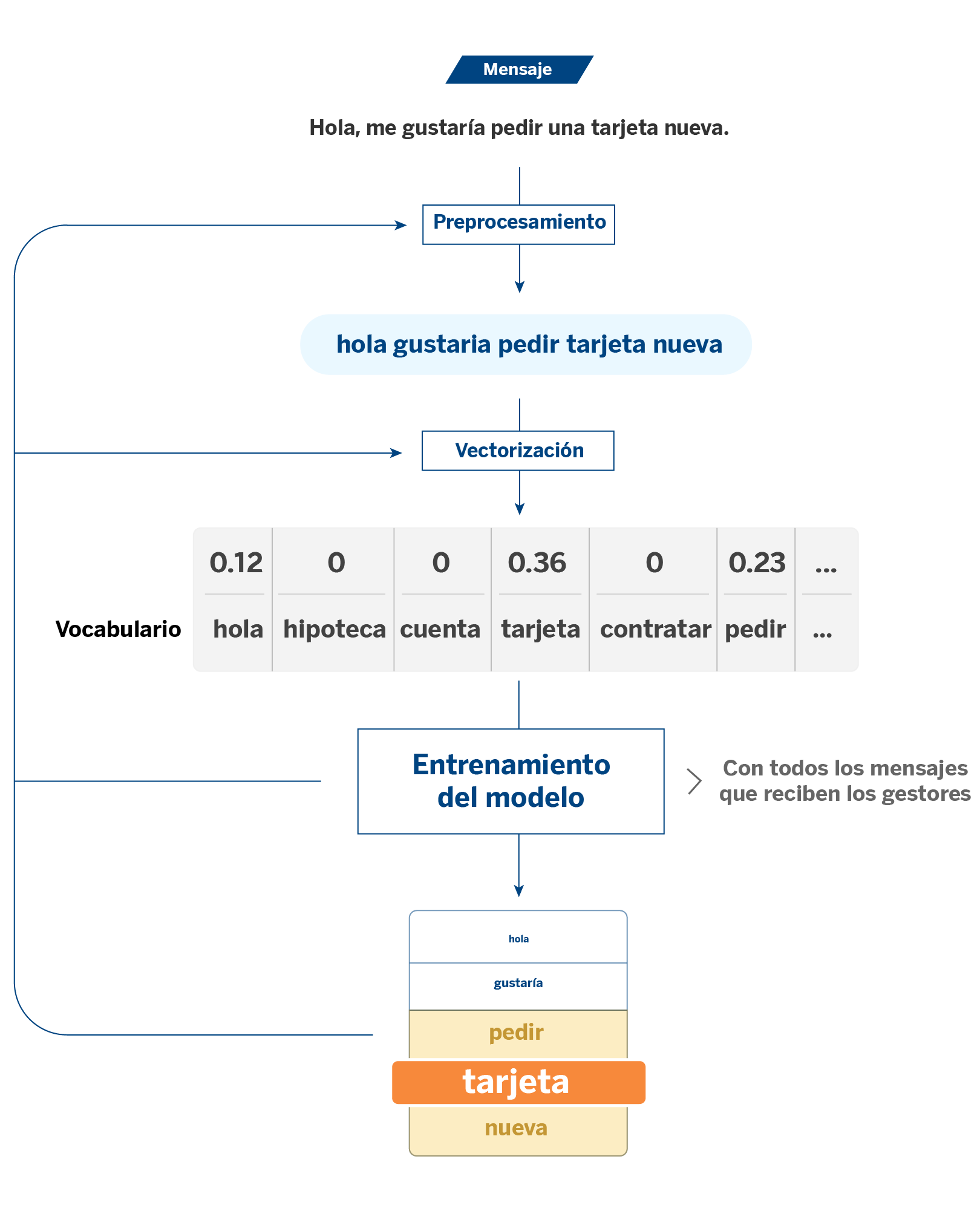
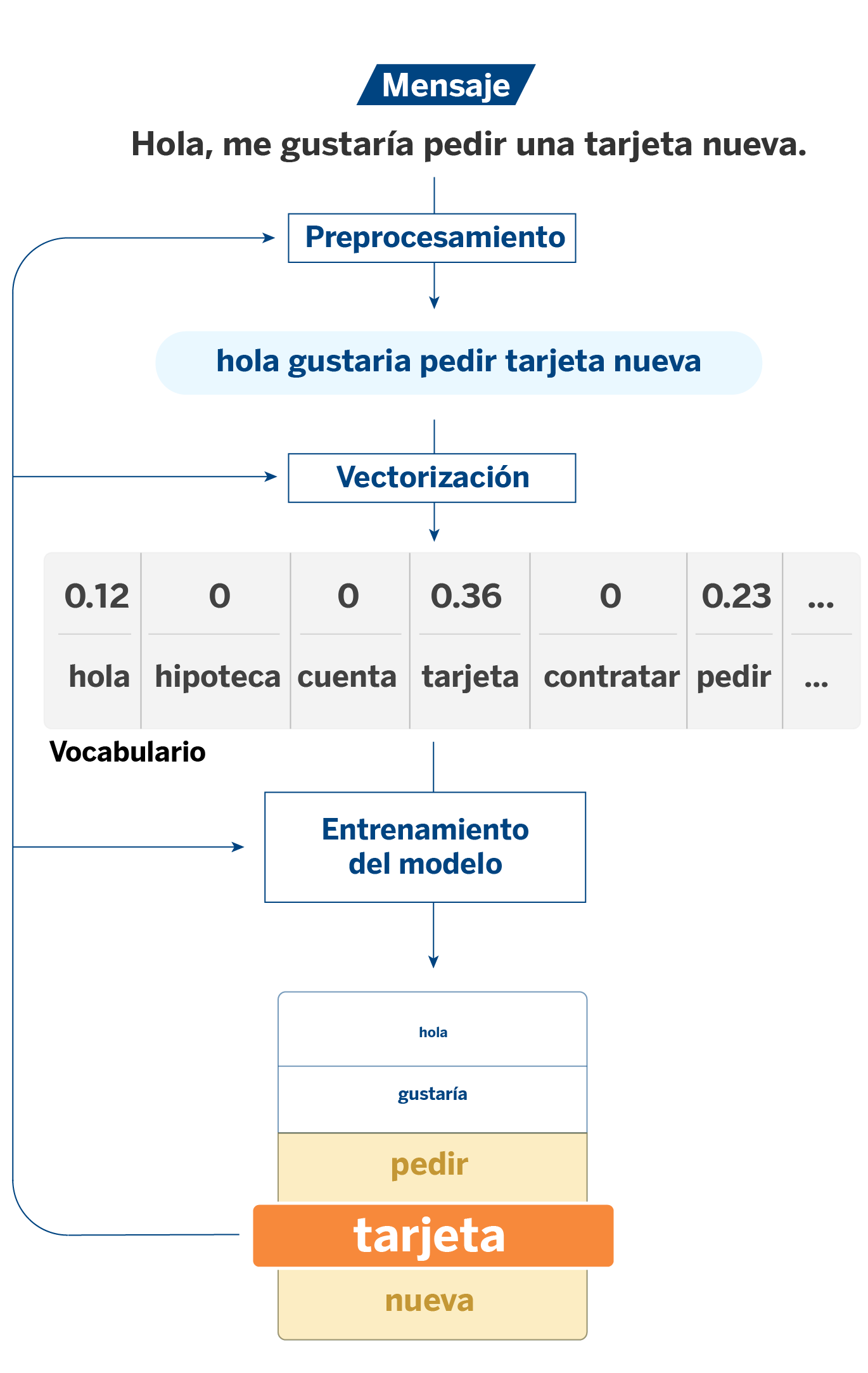
Para explicarlo, partiremos de un caso de uso con modelos de PLN (procesamiento del lenguaje natural). Cuando un gestor del banco tiene una conversación con un cliente, un sistema etiqueta la temática de la consulta. De esta manera podemos cuantificar la recurrencia de ciertos temas sobre otros, lo que nos permite tener una visión más amplia de las necesidades de los clientes.
En este caso las features de los modelos van a ser las palabras o tokens que constituyen los textos. Los tokens son el resultado de un proceso de vectorización: en los algoritmos clásicos de NLP es necesario transformar los textos en variables numéricas de forma que puedan ser procesadas por los modelos. Es sobre estos tokens donde entra en juego la explicabilidad.
A partir del análisis del feature importance y los coeficientes de los modelos, la explicabilidad nos sirve para medir la importancia que tienen los tokens en la asignación de las distintas etiquetas. Este proceso nos permite, entre otras cosas, comparar lo que dicen los datos de partida con el resultado que ofrece el modelo; es decir, comprobar que existe coherencia entre los coeficientes que arroja el modelo con los datos con los que se ha entrenado.
Por ejemplo, frente a un mensaje de un cliente que contiene la palabra “tarjeta”, habrá una probabilidad alta de tratarse de un mensaje sobre tarjetas. Este sería el caso más intuitivo. Ahora bien, podemos encontrarnos con sucesos inesperados, y es aquí donde un análisis más exhaustivo nos puede ayudar a entender lo que está pasando: ¿Por qué aparecen tokens inesperados con peso en la asignación de determinadas etiquetas? ¿Tienen sentido o se trata de ruido que está confundiendo al modelo?
Unos de los modelos que utilizamos para clasificar las conversaciones es la regresión logística. En este caso, para medir la importancia de los tokens, nos fijaremos en el valor de sus coeficientes en el modelo. Los coeficientes toman valores de -∞ a +∞. Cuanto mayor sea el valor absoluto de un coeficiente, mayor peso tendrá este token en el modelo a la hora de clasificarlo o no en una determinada categoría.
Además de entender cuáles son los tokens que más contribuyen en cada categoría, el análisis de los coeficientes también nos permite identificar fuentes de ruido en el vocabulario con el que se entrena el modelo. Por ejemplo, si hay varias palabras que siempre aparecen juntas en conversaciones de una determinada categoría y unas contribuyen positiva y otras negativamente, entonces el modelo se puede confundir entre ellas. Aquí podrían considerarse distintas soluciones: valorar estas palabras como un único token o directamente eliminarlo para evitar estas confusiones, entre otras alternativas.
Otra manera en la que estudiamos la explicabilidad en la regresión logística es el análisis del log of odds frente al signo de los coeficientes. El log of odds es una métrica que compara la probabilidad de que un token aparezca en una conversación de una determinada categoría frente a que aparezca en otras categorías. El log of odds debería ser coherente y estar alineado con los coeficientes de la regresión. Aquí, el análisis de discrepancias nos permite identificar casos como el anterior, incluso sin tener conocimiento de cómo son exactamente las conversaciones de una determinada categoría.
Todo este proceso, sumado a otros que tratan el vocabulario como la lematización, el stemming o el filtrado de tokens con demasiada o muy poca frecuencia, entre otras técnicas, nos ayudan a optimizar el vocabulario que utilizamos para entrenar el modelo. Este es nuestro fin ulterior: contar con una batería de palabras que nos permita afinar el clasificador de conversaciones y entender en base en qué está tomando las decisiones. En otras palabras, la explicabilidad, además de ayudarnos a entender el modelo, nos ayuda a mejorarlo.
Explicabilidad para descubrir patrones
Hasta ahora hemos contado cómo la explicabilidad nos ayuda a entender y mejorar nuestros modelos. Además de esto, las técnicas de explicabilidad pueden aplicarse para descubrir patrones en los datos que no son evidentes a simple vista. Es decir, la explicabilidad se convierte en una herramienta para llevar a cabo ejercicios de experimentación con datos.
Como hemos visto, en BBVA AI Factory dedicamos gran parte de nuestros esfuerzos a la personalización de nuestra interacción con el cliente, con el objetivo de amoldarnos a sus necesidades. Cada mejora que implementamos en la aplicación móvil de BBVA está sujeta a un A/B Testing, la técnica que utilizamos para realizar experimentos. Los tests A/B nos ayudan a comprobar si las nuevas funcionalidades que incluimos en la app son de mayor utilidad o no.
En el proceso de análisis de un experimento, la explicabilidad de modelos nos ayuda a descubrir qué características propias de los clientes influyen más en el uso de la nueva funcionalidad. Como resultado, podríamos observar que ciertas funcionalidades tienen una mejor adopción por parte de clientes que disponen de mayor capital en cuentas de ahorro, por ejemplo.
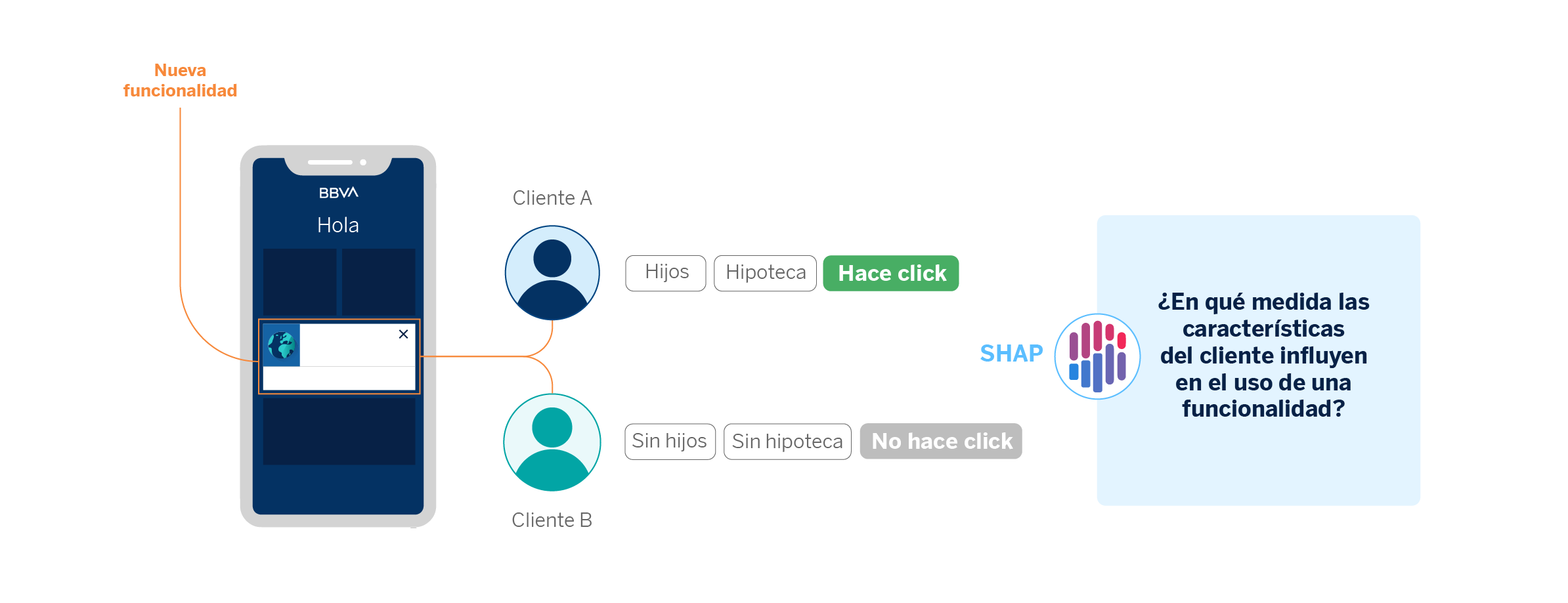
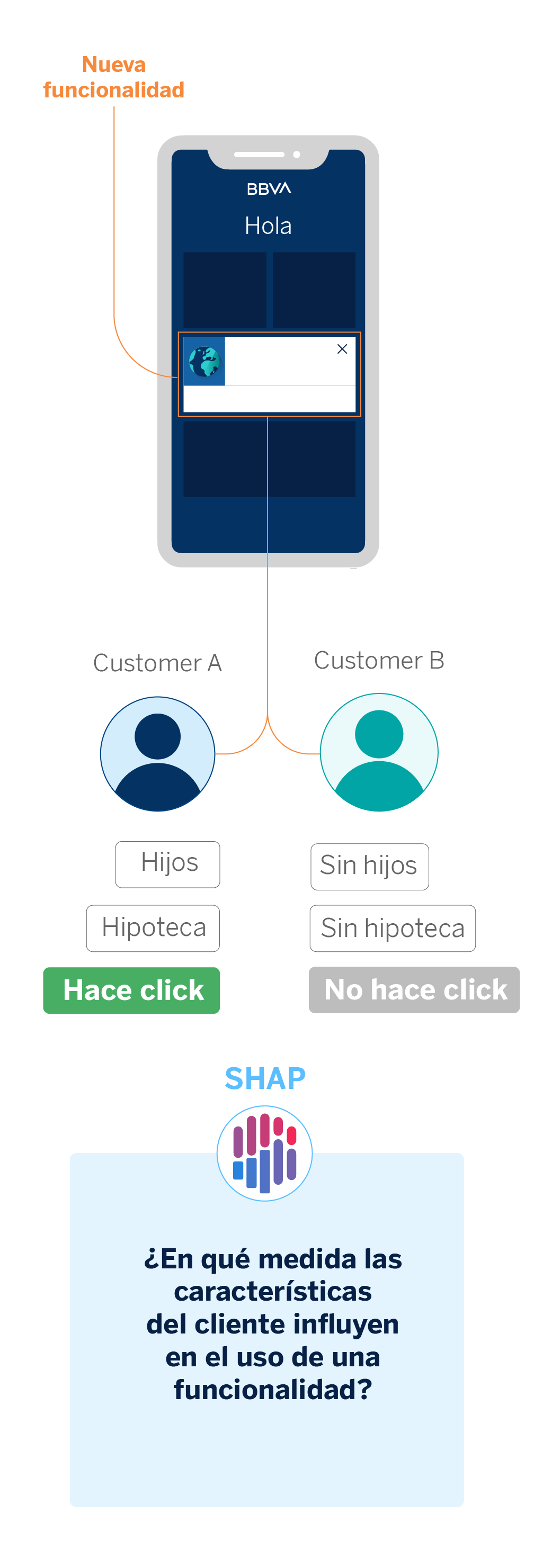
Tanto este caso de uso como el caso aplicado a los mensajes entre gestor y cliente, nos ayudan a explicar qué comportamientos o características del cliente llevan a que nuestros modelos asignen sus interacciones en una u otra categoría. En el caso de los mensajes de los gestores, nos fijamos en qué palabras hacen que un mensaje sea categorizado en una temática determinada. En el caso de la experimentación, en qué atributos del cliente podrían explicar que use o no una determinada funcionalidad.
Conclusiones
Formular preguntas es algo inherente al ser humano, y algo que nos diferencia de las máquinas. En esta era caracterizada por la revolución tecnológica que implica la inteligencia artificial es crucial hacernos preguntas para obtener respuestas. Sólo así podremos entender cómo funcionan estos sistemas. No sólo para nosotros que los utilizamos, también para todos sus consumidores.
Estos casos de uso ponen de manifiesto algunas de las muchas preguntas que tanto científicos de datos como usuarios y stakeholders se hacen sobre los modelos de inteligencia artificial, y cuáles son los métodos que se aplican para responderlas. Desenrollar algo plegado como es la opacidad de los sistemas de aprendizaje automático es crucial para conocer y mejorar la fiabilidad de los modelos.
Notas
- Para diferenciarlo de técnicas como la Permutation Feature Importance, es importante señalar que SHAP se basa en el impacto de los features en las predicciones mientras que el anterior método se basa en el empeoramiento de las métricas del modelo de aprendizaje máquina para obtener la importancia de las variables. ↩︎