
Añadiendo Equidad a Precios Dinámicos con Reinforcement Learning
Maximizar las ganancias es una premisa que siempre ha estado presente en la mente de cada comerciante y vendedor desde los primeros días del comercio; o eso pensaban. En realidad, cada actor en busca de ganancias durante un intercambio de bienes o servicios tiende inconscientemente a agregar alguna medida de justicia al trato para cultivar la confianza de un cliente; el problema era que esta confianza no estaba siendo medida, pero ahora el Reinforcement Learning (o Aprendizaje por Refuerzo) puede ayudarnos a medirla.
Un balance entre ingresos y equidad
Un grupo de científicos de BBVA Data & Analytics acaba de publicar un artículo científico en el que explican cómo, mediante el uso de Reinforcement Learning, como añadir a las políticas de precios una medida específica de equidad, aumentando así la confianza en la forma en que el banco se relaciona con sus clientes. El algoritmo, que se ajusta en tiempo real a las condiciones de los clientes, no sólo considera la maximización del beneficio en sus cálculos, sino también una medida de equidad basada en el índice de Jain, en el que la política de fijación de precios se decide homogéneamente para un número heterogéneo de grupos dados.
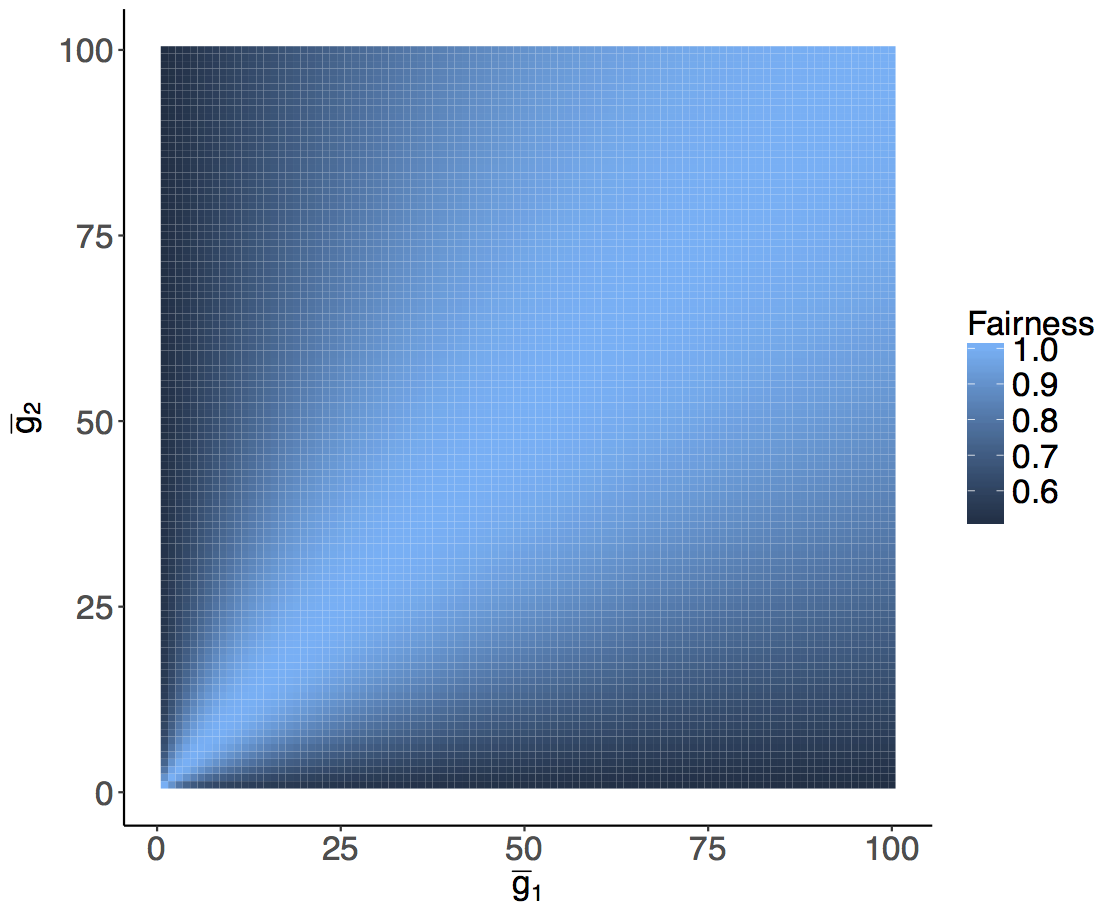
El algoritmo de RL considera dos expresiones, una que trata de maximizar los retornos en cada grupo de clientes y otra que trata de mantener la equidad al más alto nivel posible entre los grupos de compradores.
“Demostramos que RL proporciona dos características principales para conseguir la imparcialidad en la fijación dinámica de precios: por un lado, RL es capaz de aprender de la experiencia reciente, adaptando la política de precios a entornos de mercado complejos; por otro lado, integra la imparcialidad como parte fundamental del modelo”, dice uno de los principales científicos de datos detrás de esta investigación, Roberto Maestre.
Principios de Diseño de Equidad
Las políticas de precios injustas han demostrado ser una de las percepciones más negativas que los clientes pueden tener con respecto a los precios, y pueden resultar en pérdidas a largo plazo para una empresa. Esto es aún más relevante en un mundo en el que la información puede ser compartida rápidamente y la evidencia de diferencias en la fijación de precios dinámicos es evidente para los consumidores, pero -hasta ahora- el nivel de equidad en la política no se media.
A lo que RL nos ayuda, es a equilibrar en tiempo real la equidad y el beneficio en un entorno complejo y difuso de fluctuaciones de precios. RL es ideal para este tipo de problemas porque aprende por ensayo y error interactuando con el entorno, a diferencia de aprender con datos etiquetados, es decir, no es necesario un conocimiento previo sobre cómo funciona el medio ambiente.
“Con este nuevo algoritmo podemos tener transparencia en la fijación de precios y transmitir esta medida de imparcialidad al cliente, mejorando así la confianza en nuestros servicios”, afirma Maestre.
Los científicos de datos de BBVA Data & Analytics realizan un experimento en el que consideran diferentes comportamientos en función de una política de precios, algunos de los cuales son muy sensibles al cambio de precios -con una probabilidad muy baja de aceptación de ofertas a partir de un determinado umbral-, mientras que otros no muestran una respuesta significativa a los cambios de precios y otro en realidad aumenta su probabilidad de aceptación cuando los precios suben (al igual que el comportamiento de los compradores de artículos de lujo). Para lograr el máximo de ingresos y equidad, el modelo de RL tiene que recurrir a la maximización de los beneficios, manteniendo al mismo tiempo la diferencia de precios entre los grupos al mínimo. Este enfoque es además capaz de eliminar los sesgos en las políticas de precios, ya que consigue equidad a todos los grupos de clientes considerados por igual (por ejemplo: por género, raza, nivel de ingresos, etc.).
Transparencia y responsabilidad
A pesar de la simplicidad del entorno propuesto, el documento en sí mismo permite efectivamente abrir una rica discusión relacionada con lo que es justo en materia de precios, comenzando con una forma específica de medirlo. Además, este estudio nos permite comparar las políticas de precios conseguidas, en un entorno abierto como The Turing Box. Dado que estas plataformas permiten a cualquier profesional, no sólo a científicos de computación o investigadores en ML, estudiar la IA; nos beneficiamos de una valiosa retroalimentación.
Roberto Maestre presentará las conclusiones de su artículo científico durante la Conferencia sobre Sistemas de Inteligencia que tendrá lugar en Londres el próximo mes de septiembre.