
Una búsqueda aleatoria en el NeurIPS 2019
La conferencia se celebró en Vancouver, Canadá, durante la semana del 8 al 14 de diciembre, y estuvo repleta de tutoriales, workshops, demostraciones, presentaciones orales y sesiones de póster. En este artículo resumimos algunos aspectos relevantes del evento.
Algunos números
Con aproximadamente 13.000 personas registradas, este fue la edición del NeurIPS más grande hasta la fecha. Hubo un número récord de 6743 artículos enviados (49% más respecto de la edición del año anterior), examinados y comentados por un total de 4543 revisores, y de los cuales resultaron 1428 artículos aceptados (es decir, una tasa de aceptación de 21,6%). Hubo 9 tutoriales y 51 workshops con tópicos muy variados, tales como: reinforcement learning, bayesian machine learning, imitation learning, federated learning, algoritmos de optimización, representación de grafos, biología computacional, teoría de juegos, privacidad y justicia en los algoritmos de aprendizaje, etc.
Además, hubo un total de 79 meetups oficiales de NeurIPS en más de 35 países en 6 continentes. Estos meetups son eventos locales en los que se discute contenido de la conferencia en vivo; la mayoría de estos se realizaron en África (28) y en Europa (21). Para una descripción más detallada de los números que envolvieron a esta edición del NeurIPS recomendamos este post.
Presencia industrial
Tal como se discute en este excelente post con algunas estadísticas sobre los artículos aceptados al NeurIPS 2019, es notable la gran presencia de autores con afiliación a grandes compañías tecnológicas. Por ejemplo, en el Top 5 de instituciones con mayor número de artículos aceptados, aparecen Google (por medio de Google AI, Google Research o DeepMind) y Microsoft Research junto con el MIT, Stanford University, y Carnegie Mellon University. En el Top 20 también podemos notar presencia industrial con Facebook AI Research, IBM Research y Amazon. A continuación presentamos una lista con los sitios de cada una de las compañías con mayor presencia en el evento, en donde enlazan los artículos, tutoriales y workshops en los que intervinieron.
- Google AI
- Microsoft Research
- Facebook AI Research
- IBM Research
- Amazon
- Intel AI
- Nvidia Research
- Apple
Como es de esperar, la mayor parte de la investigación de estas compañías sigue estando orientada hacia comprensión del lenguaje, traducción entre idiomas, reconocimiento de voz, percepción de visual y de audio, etc. Notamos que una gran parte de la investigación ha estado orientada al diseño de nuevas variantes de modelos de lenguaje basados en BERT y herramientas para entender las representaciones que producen 1 2 3 4. Para una descripción más detallada de varios artículos relacionados con BERT y Transformers en NeurIPS 2019, recomendamos este post.
Adicionalmente, pudimos apreciar que existe mucha investigación de estas compañías con o sin colaboración de instituciones académicas, orientada hacia los campos de multi-agent reinforcement learning 5 6 7, motivados por los datos que pueden obtenerse por la interacción de múltiples agentes en escenarios reales en internet, y multi-armed bandits 8 9 10, destacando particularmente la presencia de trabajos sobre contextual bandits 11 12, motivados por aplicaciones relacionadas con personalización y optimización web.
Por otra parte, aunque la presencia industrial cada vez mayor en esta conferencia es enriquecedora, también es verdad que debido a los eventos extraoficiales y exclusivos que las compañías organizan, puede llegar a percibirse una sensación de que los objetivos científicos de la conferencia y de inclusión se ven mermados.
Tendencias
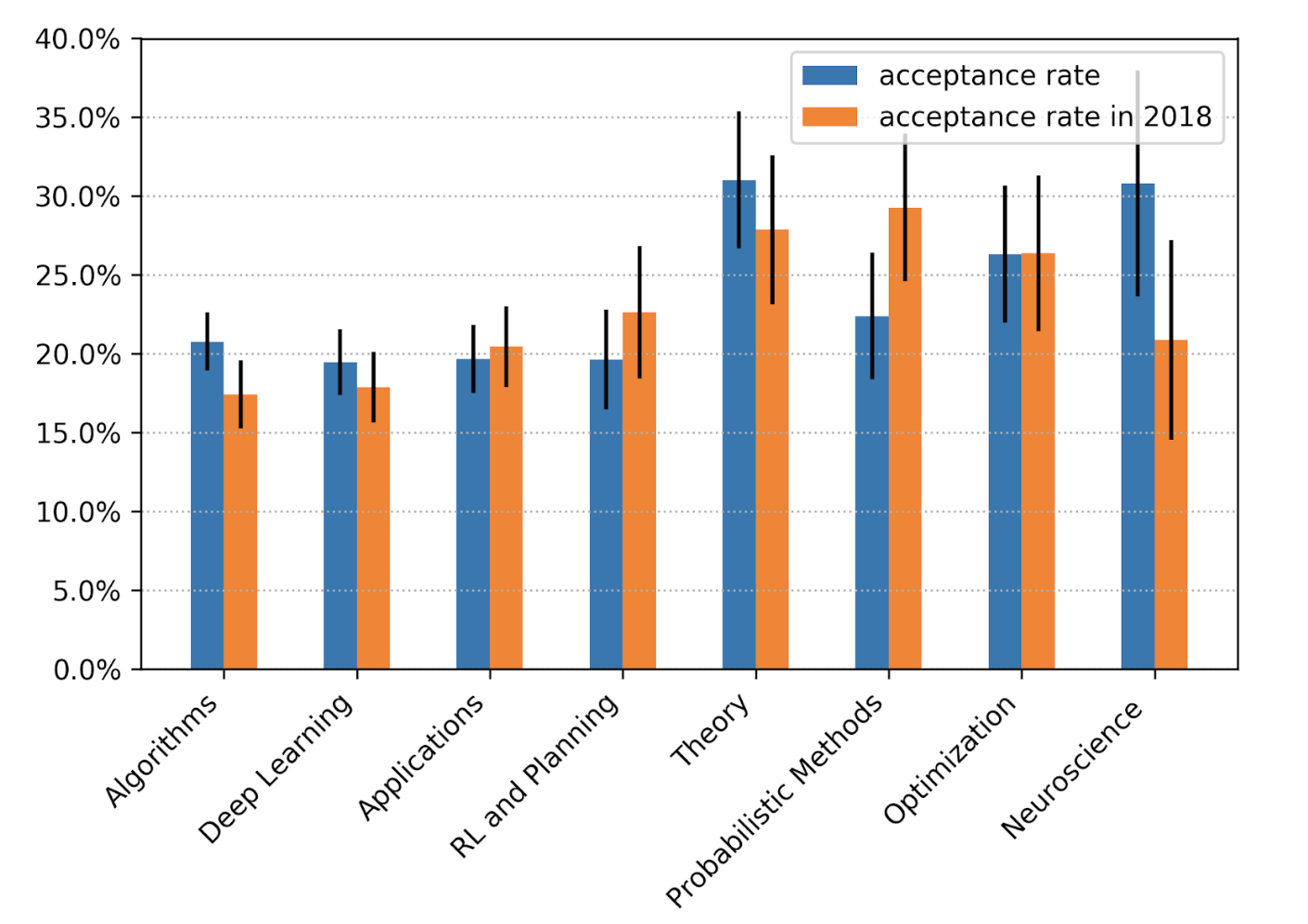
Según el análisis del program chair de esta edición del NeurIPS, Hugo Larochelle, la categoría que obtuvo mayor aumento en su tasa de aceptación respecto de la edición anterior es la de neurociencia.
Por otra parte, mirando el análisis de las palabras clave de los artículos aceptados de 2019 en comparación con aquellos aceptados en 2018, descrito en este excelente post por Chip Huyen, podemos hacernos una idea de qué tópicos han ganado o han perdido presencia respecto del año pasado.
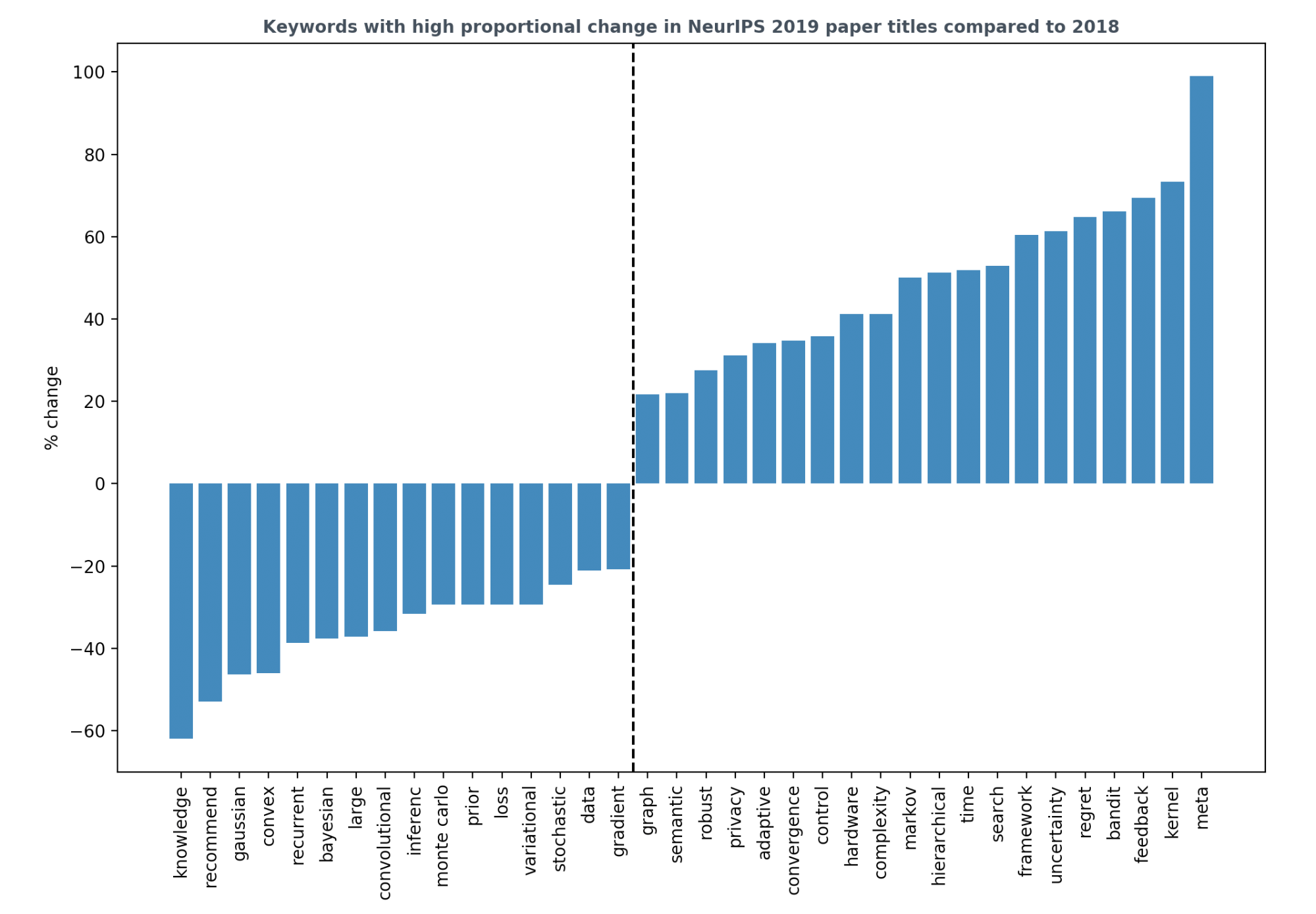
Como principales observaciones tenemos:
- Reinforcement learning está ganando mucho terreno. En particular, los algoritmos basados en multi-armed bandits y contextual bandits. Esto se ve en palabras como: bandit, feedback, regret, y control.
- Las redes neuronales recurrentes y convolucionales parecen perder terreno. Al menos en el caso de las recurrentes, es de esperar que esto se deba a que desde el NeurIPS 2017, todo lo que necesitamos son mecanismos de atención.
- Las palabras hardware y privacy ganan terreno, reflejando el hecho de que hay más trabajos relacionados con el diseño de algoritmos que toman en cuenta las arquitecturas de hardware, o cuestiones relacionadas con la privacidad.
- Palabras como convergence, complexity y time también ganan terreno, reflejando la creciente investigación en la teoría relacionada con deep learning.
- La investigación relacionada con la representación de grafos también va en aumento, mientras que los métodos basados en Kernels parecen estar experimentando un resurgimiento, tal como evidencian los cambios porcentuales positivos de las palabras graph y kernel.
- Como dato curioso, mientras el peso del término bayesian baja, el de uncertainty sube. Lo anterior podría deberse a que, si bien en 2018 hubieron muchos trabajos relacionados con principios bayesianos no relacionados con deep learning (p.ej. bayesian optimization, bayesian regression, etc.), en 2019 ha habido una mayor tendencia a incorporar incertidumbre, y en general, elementos probabilísticos a los modelos de deep learning.
- Meta es la palabra con mayor cambio porcentual positivo, reflejando el aumento de popularidad de los algoritmos de meta-learning en sus diversas variantes (p.ej. graph meta-learning, meta-architecture search, meta-reinforcement learning, meta-inverse reinforcement learning, etc).
Artículos ganadores de reconocimientos
En esta edición del NeurIPS hubo una nueva categoría llamada Outstanding New Directions Paper Award. De acuerdo al comité organizador, este premio se otorga para resaltar aquel trabajo que se distingue por establecer líneas de futura investigación, y el artículo ganador fue Uniform Convergence may be Unable to Explain Generalization in Deep Learning. A grandes rasgos, este artículo explica tanto teórica como empíricamente que la teoría de convergencia uniforme no puede explicar por sí sola la habilidad de los algoritmos de deep learning para generalizar, por lo que hace un llamado al desarrollo de técnicas que no dependan de esa herramienta teórica para explicar la habilidad de generalización.
Por otra parte, el Test of Time Award -un premio otorgado a un trabajo presentado en el NeurIPS hace diez años y que ha mostrado tener un impacto duradero en su respectivo campo- fue otorgado a Dual Averaging Method for Regularized Stochastic Learning and Online Optimization, en el cual, a muy grandes rasgos, Lin Xiao propuso un nuevo algoritmo para resolver problemas de optimización convexa en línea que explota la estructura de regularización L1 y que goza de garantías teóricas.
Para ver la lista completa de los artículos acreedores a reconocimientos puede consultarse este post escrito por el comité organizador, y para una discusión un poco más detallada de algunos de los artículos galardonados recomendamos este post.
Tutoriales
Los tutoriales son sesiones de un par de horas de duración que buscan exponer investigación reciente en algún tópico en particular por algún investigador líder en su campo. Tuvimos la oportunidad de asistir a dos de ellos:
- Deep Learning with Bayesian Principles. Emtiyaz Khan enumeró conceptos de deep learning y de bayesian learning para establecer similitudes y diferencias entre ambos. Dentro de las principales diferencias, sostuvo que mientras el deep learning utiliza un enfoque más empírico, utilizar principios bayesianos fuerza a establecer hipótesis desde el inicio. En este sentido, el trabajo de Khan se centra en reducir la brecha que existe entre ambos. Durante el tutorial, mostró cómo a partir de principios bayesianos es posible desarrollar un marco teórico donde los algoritmos de aprendizaje más utilizados en la comunidad de deep learning (SGD, RMSprop, Adam, etc.) surgen como casos particulares. En nuestra opinión, el material presentado en este tutorial es exquisito y resulta impresionante ver cómo dichas técnicas de optimización pueden ser deducidas de una forma elegante a través de principios probabilísticos.
- Reinforcement Learning: Past, Present, and Future Perspectives. Katja Hofmann presentó una visión general bastante completa y un repaso histórico a los avances más significativos en el campo de reinforcement learning. Además, como conclusión, Katja señaló oportunidades futuras tanto en investigación como en aplicaciones reales, con énfasis en el campo de multi-agent reinforcement learning, especialmente en entornos colaborativos. Consideramos que este tutorial presenta un excelente material para aquellos que quieran iniciarse en el estudio de reinforcement learning y para quienes quieran estar al tanto sobre líneas de investigación presentes y futuras en este campo.
Workshops
Los workshops son sesiones de varias horas de duración que son organizados como parte de la conferencia, que se componen de charlas y sesiones de póster, y que buscan promover el conocimiento y la colaboración en áreas emergentes. Tuvimos la oportunidad de estar presentes principalmente en los siguientes:
- Deep Reinforcement Learning: Este workshop fue de los más concurridos y reunió a investigadores trabajando en la intersección de reinforcement learning y deep learning. Las sesiones de pósters fueron muy abundantes y enriquecedoras, y como era de esperar, hubo bastante presencia de investigadores de DeepMind, Google Research y del BAIR. Recomendamos esta plática de Oriol Vinyals sobre avances recientes en DeepMind con StarCraft II utilizando herramientas de multi-agent reinforcement learning.
- Beyond First Order Methods in ML: Este workshop partió de la premisa de que los métodos de optimización de segundo y mayor orden están infravalorados en las aplicaciones a problemas de machine learning. Durante el workshop, se discutieron tópicos sobre métodos de segundo orden, métodos adaptativos basados en gradiente, técnicas de regularización, etc. En particular, recomendamos esta plática de Stephen Wright, figura prominente en la comunidad de optimización, sobre algoritmos de optimización suave y no convexa.
Otros workshops que atendimos parcialmente y de los cuales recomendamos revisar el material fueron Bayesian Deep Learning y The Optimization Foundations of Reinforcement Learning.
Sesiones de póster

En este apartado presentamos una pequeña selección de artículos que vimos durante las sesiones de póster y nos parece valioso compartir:
- Multilabel reductions: what is my loss optimising?: Este trabajo describe las elecciones populares de funciones objetivo para abordar problemas de multi-label classification y argumenta que, aunque éstas han mostrado tener éxito empírico, poco se sabe sobre cómo se relacionan con las dos métricas más populares para esos tipos de problemas: precision@k y recall@k. El artículo busca llenar ese vacío y proporciona una justificación formal a cada una de las formas de elegir la función objetivo.
- PyTorch: An Imperative Style, High-Performance Deep Learning Library: Es el nuevo artículo de PyTorch por excelencia. En él, los autores detallan los principios que impulsaron la implementación de PyTorch y cómo éstos se reflejan en su arquitectura.
- rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch: Presenta el proyecto rlpyt, que incluye implementaciones en PyTorch de los algoritmos más comunes utilizados en deep reinforcement learning. Además, es compatible con la interfaz de ambientes de OpenAI Gym.
- The PlayStation Reinforcement Learning Environment (PSXLE): Presenta el proyecto PSXLE, un emulador de PlayStation modificado y diseñado para utilizarse como un nuevo entorno para evaluar algoritmos de reinforcement learning. También es compatible con la interfaz de OpenAI Gym.
- Competitive Gradient Descent: Este trabajo aborda cierta clase de aplicaciones de Gradient Descent desde el punto de vista de optimización competitiva y presenta un nuevo algoritmo para obtener la solución que corresponde al equilibrio de Nash en un juego de dos jugadores. Este trabajo es interesante porque está relacionado con problemas que surgen en reinforcement learning o en deep learning (p.ej. en GAN’s, con la red generadora y la red discriminadora en un juego competitivo).
Conclusiones
En pocas palabras, el NeurIPS 2019 fue un evento masivo y enriquecedor, al mismo tiempo que abrumador. La gran cantidad de personas hace desafiante algunos aspectos de la conferencia, por ejemplo, la interacción efectiva con los autores de los artículos en las sesiones de póster. Debido a la gran cantidad de trabajos y de tópicos, encontrar el balance ideal entre exploración y explotación tanto en las pláticas de los workshops como en las sesiones de póster eventualmente se hace imposible y una búsqueda aleatoria parece ser la mejor estrategia; sin embargo, aún así, hemos descubierto trabajos y líneas de investigación que han servido para crecimiento intelectual e inspiración.
Referencias
- Emily Reif, Ann Yuan, Martin Wattenberg, Fernanda B. Viegas, Andy Coenen, Adam Pearce, Been Kim ↩︎
- Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee ↩︎
- Wei-Cheng Chang, Hsiang-Fu Yu, Kai Zhong, Yiming Yang, Inderjit Dhillon ↩︎
- Benjamin Hoover, Hendrik Strobelt, Sebastian Gehrmann ↩︎
- Nicolas Carion, Nicolas Usunier, Gabriel Synnaeve, Alessandro Lazaric ↩︎
- Alexander Peysakhovich, Christian Kroer, Adam Lerer ↩︎
- Sai Qian Zhang, Qi Zhang, Jieyu Lin ↩︎
- Yogev Bar-On, Yishay Mansour ↩︎
- Soumya Basu, Rajat Sen, Sujay Sanghavi, Sanjay Shakkottai ↩︎
- Sumeet Katariya, Ardhendu Tripathy, Robert Nowak ↩︎
- Santiago Balseiro, Negin Golrezaei, Mohammad Mahdian, Vahab Mirrokni, Jon Schneider ↩︎
- Dylan J. Foster, Akshay Krishnamurthy, Haipeng Luo ↩︎