Customer insights extraction with transformers and NLP
At BBVA, customer satisfaction is a foundational pillar in developing and evolving our products and services. To measure this satisfaction, we frequently use quantitative metrics like the Net Promoter Score (NPS), which assesses the likelihood that a customer will recommend us to others.
While these metrics offer a general overview, they fall short in explaining the underlying reasons for customer responses. This is why qualitative feedback, such as written comments, is essential for gaining a deeper understanding of the user experience. We at BBVA have developed an advanced solution, combining natural language processing (NLP) technologies with pre-trained transformer-based models to leverage the data collected from our app satisfaction questionnaires.
This solution enables the analysis of large volumes of comments and automatically identifies and groups key aspects or topics users mention.
This article explains how we developed a model for analyzing feedback in multiple languages using a pre-trained HuggingFace sentence-transformer. We fine-tuned the model using advanced techniques, enabling us to classify the messages we receive. This results in a practical application: a system that helps us effectively respond to customer feedback.
Challenges in extracting customer insights
When customers share their opinions about the BBVA app, we gain insights into what makes them satisfied or frustrated. We also learn if they are experiencing any issues with the app’s functionality or have any questions about our services.
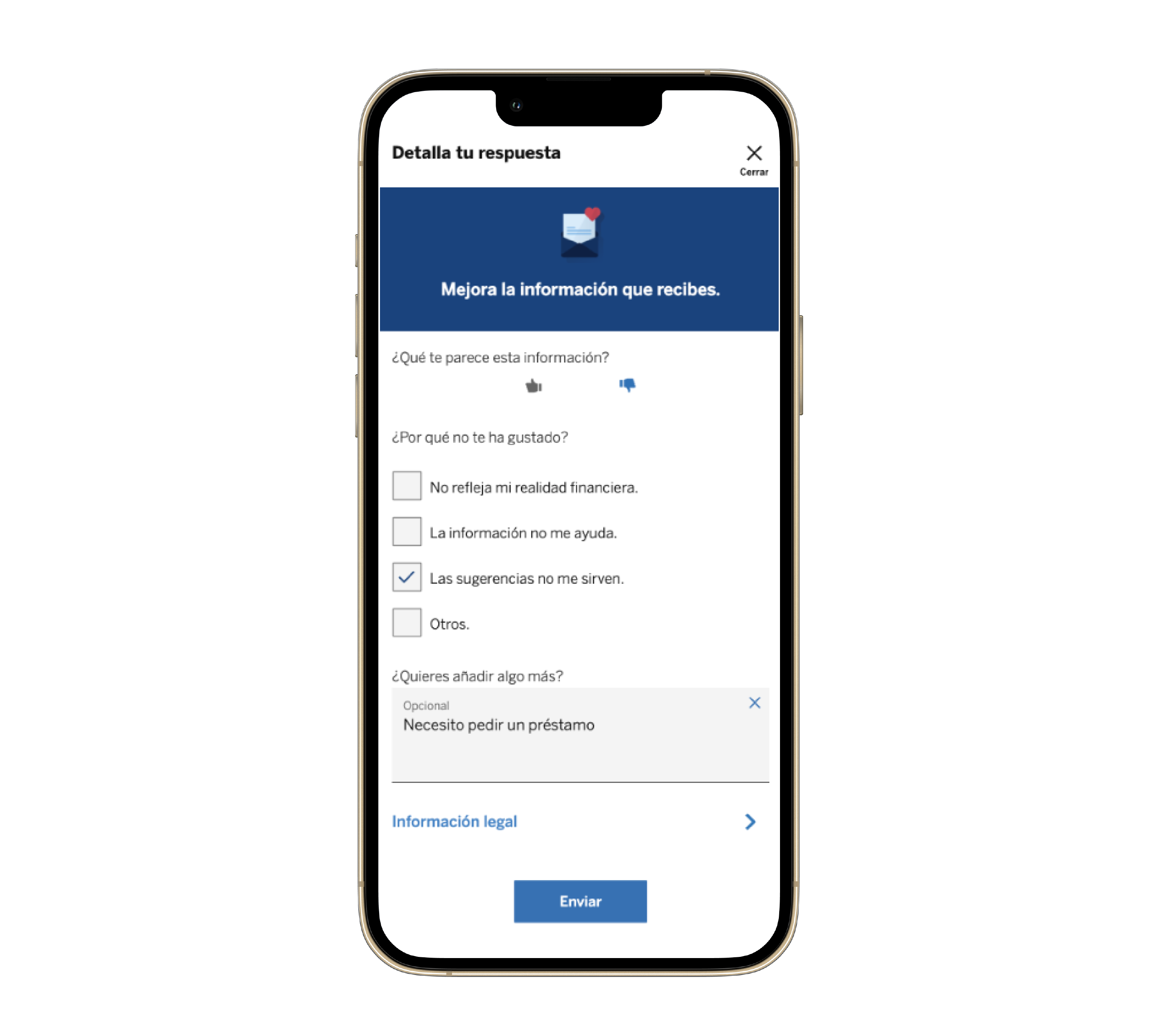
Analyzing qualitative feedback can be challenging. The comments differ significantly in length, tone, and content, making it hard to interpret them consistently. Some comments contain positive and negative opinions within the same message, making it difficult to determine the overall sentiment accurately.
In this sense, analyzing the sentiment of comments can be complicated, especially when they contain sarcasm or ambiguous expressions. For example, the phrase “How nice, they always take so long to respond!” can confuse algorithms if misinterpreted.
Another significant challenge we face is that comments come in various languages, each reflecting different cultural contexts. To analyze these comments accurately, we need models that preserve the nuances of each language. Additionally, only a small proportion of users leave written comments, which impacts the representativeness of the data.
Finally, models based on transformer architecture, like sentence-transformers, excel at understanding natural language. However, they require significant computational resources, which can pose challenges when dealing with large data volumes or limited hardware.
Methodology: How do we obtain customer insights
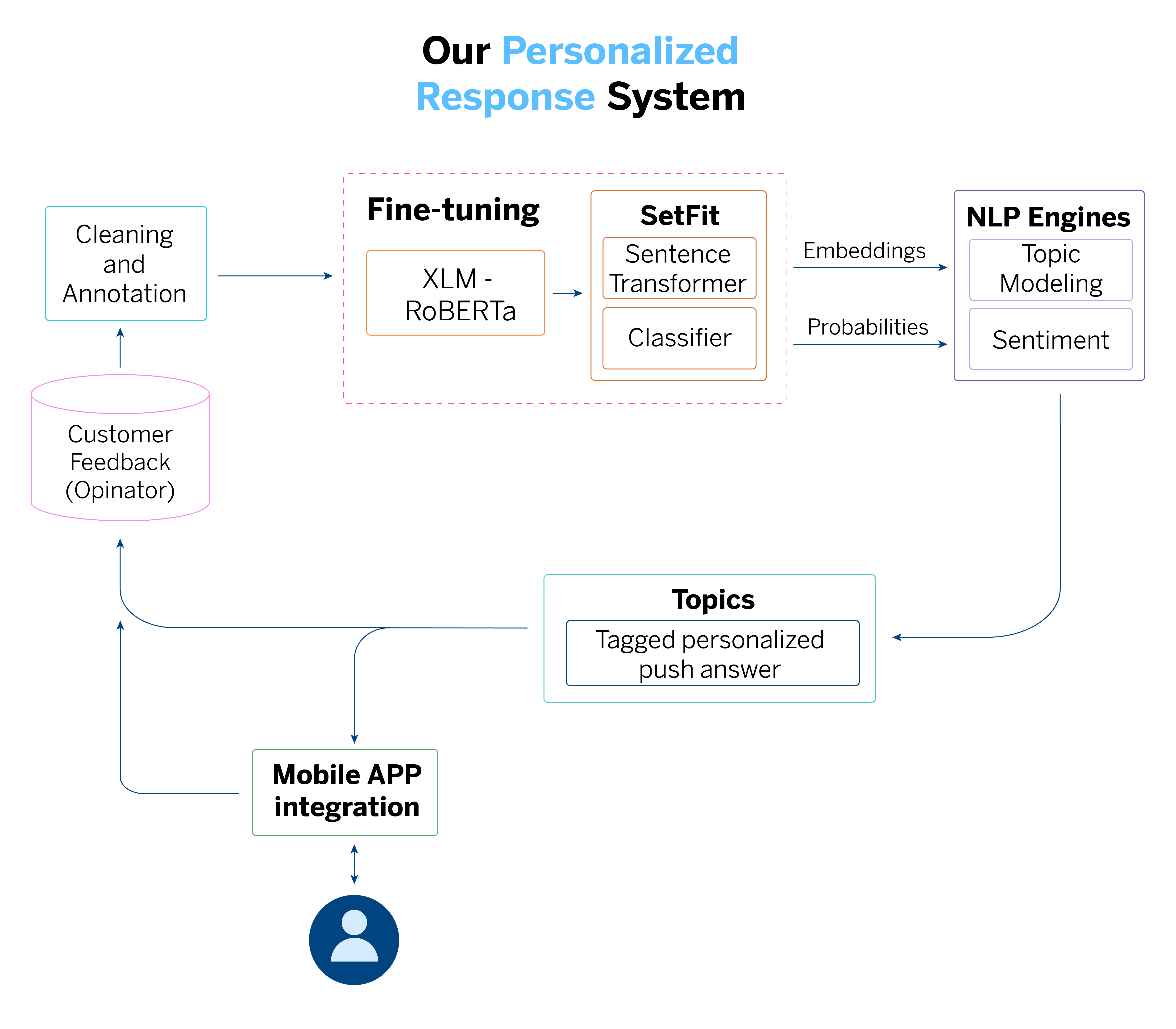
To tackle these challenges, we at BBVA have developed a pipeline integrating advanced NLP techniques with dimensionality reduction and clustering algorithms. This pipeline enables us to analyze comments comprehensively, organizing and clustering large volumes of text.
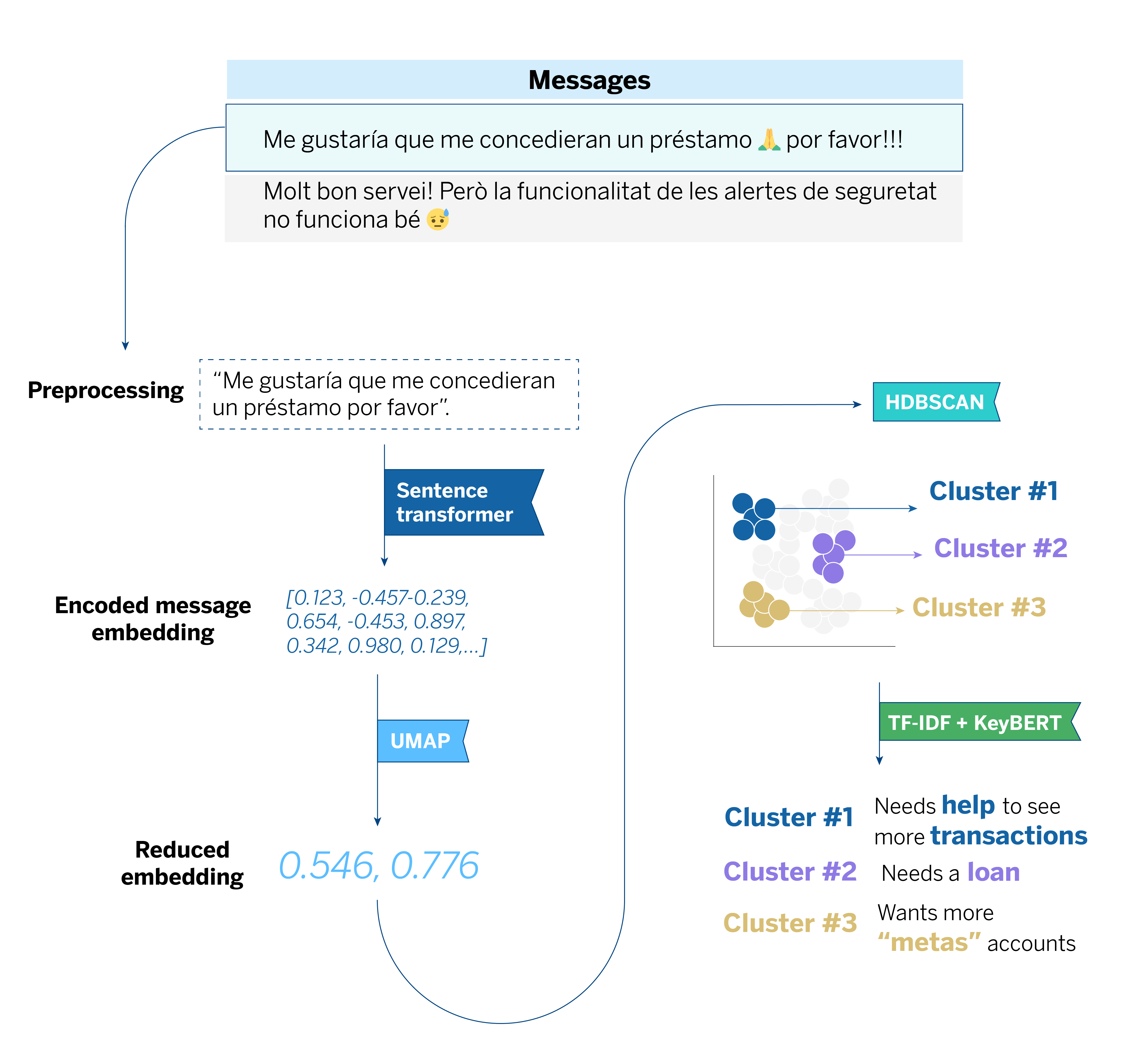
The process begins with collecting user comments through various questionnaires within the BBVA mobile application. Next, we preprocess these comments by removing unnecessary elements and irrelevant symbols to ensure that the models can interpret the text accurately. Since we receive comments in multiple languages, we utilize a sentence-transformer model based on XLM-RoBERTa, which can handle different languages without the need for translation.
Generation of embeddings and fine-tuning
After processing the data, we begin analyzing the comments. First, we convert them into numerical data using a technique called embeddings, which transforms words into numbers that algorithms can understand. We specifically use the sentence-transformer model because it effectively captures the meaning of sentences.
However, the pre-trained models we use are not tailored to the specific feedback we receive at BBVA. To address this, we conducted a fine-tuning process with the SetFit framework. This approach enables us to adjust the model using data from our domain without requiring GPUs.
Dimensionality reduction and clustering
After transforming the comments into embeddings, we apply a nonlinear dimensionality reduction technique called UMAP. This technique allows us to simplify the data by compressing the embedding vectors into a lower-dimensional space, effectively preserving both the local and global structures of the data.
This sets the stage for the next step, which involves clustering the comments based on similarity using a density-based clustering algorithm called HDBSCAN. Unlike other clustering algorithms, HDBSCAN does not require the number of clusters to be specified in advance; instead, it automatically determines the clusters based on the density of the data. Additionally, HDBSCAN can identify comments that do not belong to any group, categorizing them as “noise.” This feature allows us to effectively manage irrelevant or noisy data.
Keyword extraction and topic labeling
After forming groups of comments with HDBSCAN based on their similarities, the next step is to analyze each of these groups, or “clusters,” to understand their content. We utilize KeyBERT and TF-IDF to achieve this, which help us identify the keywords that best represent each topic.
KeyBERT uses embeddings generated by our model, previously adjusted with SetFit, to extract relevant keywords from each cluster. In contrast, TF-IDF helps us weigh the importance of words based on their frequency within the cluster compared to their presence in the complete set of comments. For instance, if a group of comments highlights issues with app performance, these tools effectively identify the problem, enabling us to respond quickly and prioritize necessary improvements.
Results and impact
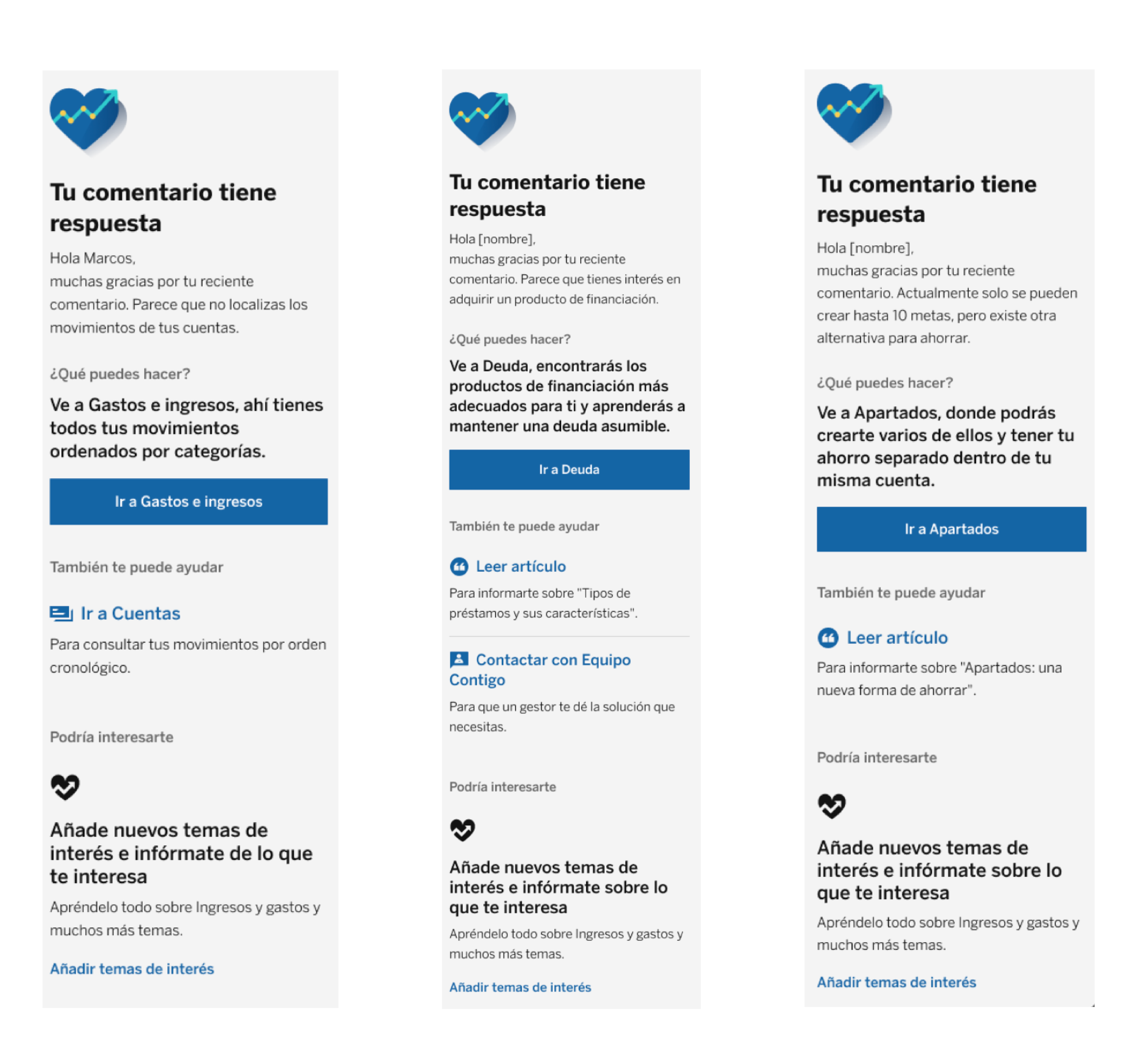
This process enables us to categorize the comments we receive and address recurring topics in our users’ messages. While this methodology can be applied to various projects and areas within the bank, its first practical application is generating push notifications through the BBVA app. These notifications are sent to customers who have provided feedback, specifically in the financial health section.
The system automatically identifies comments related to specific issues, such as problems viewing bank transactions. Customers experiencing these issues receive a notification that explains how to access their transactions and outlines the steps they can take to view past transactions. Additionally, we address requests for more “Metas” accounts by informing customers about similar functionalities, such as “Apartados”.
Push notifications have a delivery latency of one day (D+1), meaning customers receive a personalized response within 24 hours of their comment. This system enhances our responsiveness and establishes a feedback loop, allowing us to assess customer reactions to the notifications and continuously improve the process.
Conclusions on qualitative customer insights extraction
Customer opinions provide valuable insights that traditional metrics miss, uncovering the reasons behind their perceptions.
This approach, which utilizes advanced natural language processing models, enables us to unveil underlying patterns and themes in comments, helping us make sense of a large volume of data that would be challenging to analyze manually. This methodology allows us to transition from a broad overview to a deeper understanding of users’ emotions, expectations, and frustrations.
This way, we can make faster decisions that align with our customers’ real needs and respond to them accurately.
The value of this process lies in its capacity to transform chaotic and fragmented feedback into a structured, actionable source of knowledge. This represents a turning point in how we listen to our customers and respond to their expectations.