
What we have learned about AI causal inference from two hypotheses
We’ve often been told that a full moon influences tide levels, but is it truly responsible for their elevation? The reality is more nuanced: while the full moon does coincide with higher tide periods called spring tides, it is not the moon phase that directly causes them. Instead, it’s the combined gravitational forces of both the moon and the sun when they align with the Earth. Interestingly, this effect can also be observed during a new moon phase. This case highlights the need to clearly differentiate between correlation and causation—a subtle yet significant challenge in data analysis.
Predictive AI operates by identifying data correlations to forecast future events. However, these predictions indicate possibilities without fully accounting for the underlying phenomena. This reality prompted several data teams at BBVA to engage in an exercise to examine the reasoning behind some of our projects, thereby gaining a clearer insight into the decisions made by the machine learning models we develop.
This is where causal inference plays a crucial role. Causal models enable us to derive conclusions from observational data, validate intricate hypotheses, and uncover relationships that conventional correlational methods do not identify.
This article examines the progression of AI towards causal understanding at BBVA through two hypotheses. We will demonstrate how these experiments enable us to address essential questions and establish a foundation for more informed and transparent decision-making.
Causal Inference: Our hypotheses
Hypothesis #1
Financial health tools cause an increase in clients’ savings
BBVA aims to enhance customers’ financial health by offering tools and recommendations for saving and better financial management. Evaluating their effectiveness requires understanding if these bank proposals genuinely influence customers’ financial habits or if the observed changes stem from other influences.
In terms of financial health, we have utilized advanced causality methods1 such as Propensity Score Matching and Double Machine Learning. These techniques enable us to compare clients who have used financial health tools with those who have not while controlling for other variables that may influence the outcome, such as income level, expenses, or age.
Propensity Score Matching (PSM) is a method for identifying pairs of similar individuals (in this case, customers) who differ only by one factor: whether they have utilized BBVA’s financial tools. This approach enables the formation of a “treated” group (those who use the tools) and a “control” group (those who do not), ensuring they are comparable and mitigating the selection bias that could skew the results.
On the other hand, Double Machine Learning is a more advanced technique that allows for the correction of potential biases when assigning treatment to clients. This method uses predictive models to estimate both the likelihood of receiving the treatment (in this case, using the financial tools) and the final outcome (such as the level of savings), enabling better isolation of the actual causal effect.
Thanks to these techniques, we could separate the impact of tool use on clients’ financial health from the influence of other factors, such as their income, expenses, and past savings. The results were remarkable: in Spain, users of the financial health tools saw an average savings increase of 11% more than non-users, while in Mexico, this difference was even more significant, reaching 20%.
Hypothesis #2
Personalized recommendations cause an increase in customer interaction with our products
BBVA has embraced a personalized approach to deliver products and services that align closely with our customers’ preferences. Although correlation-based personalization might appear beneficial, it doesn’t always ensure that the recommendations provided to customers are the best fit. This is where causal analysis becomes essential, providing a more reliable and precise method for assessing the real impact of our offerings recommendations.
We have employed causal inference models to assess how recommender systems influence user behavior, aiming to identify which products are most relevant to each customer and which personalization strategies result in higher conversion rates.
One major challenge in personalization is “attribution noise.” This refers to the difficulty in identifying whether a particular offer directly influences a customer’s purchasing decision or interest in a product or if other uncontrollable external factors are at play. To address this issue, BBVA has adopted a strategy utilizing meta-learners–machine learning models specifically developed to evaluate causal effects in settings with numerous variables.
Meta-learners enable the modeling of various scenarios in which different offers are presented to customers. Rather than simply observing the outcome of offering a product, these models allow us to discern whether presenting a specific offer leads to an increase in product purchases. This approach aids us in identifying which customers are more inclined to accept an offer and which are unlikely to do so, even if we present them with an advertisement.
These causal models have enabled us to precisely assess our system’s impact on personalizing commercial offers and enhance its performance. A key discovery is that if a customer is already highly likely to purchase a product, presenting them with an offer doesn’t significantly influence their decision. This insight allows us to develop new strategies that boost offer effectiveness, leading to a better customer experience.
Takeaways: What benefits does causal inference offer us?
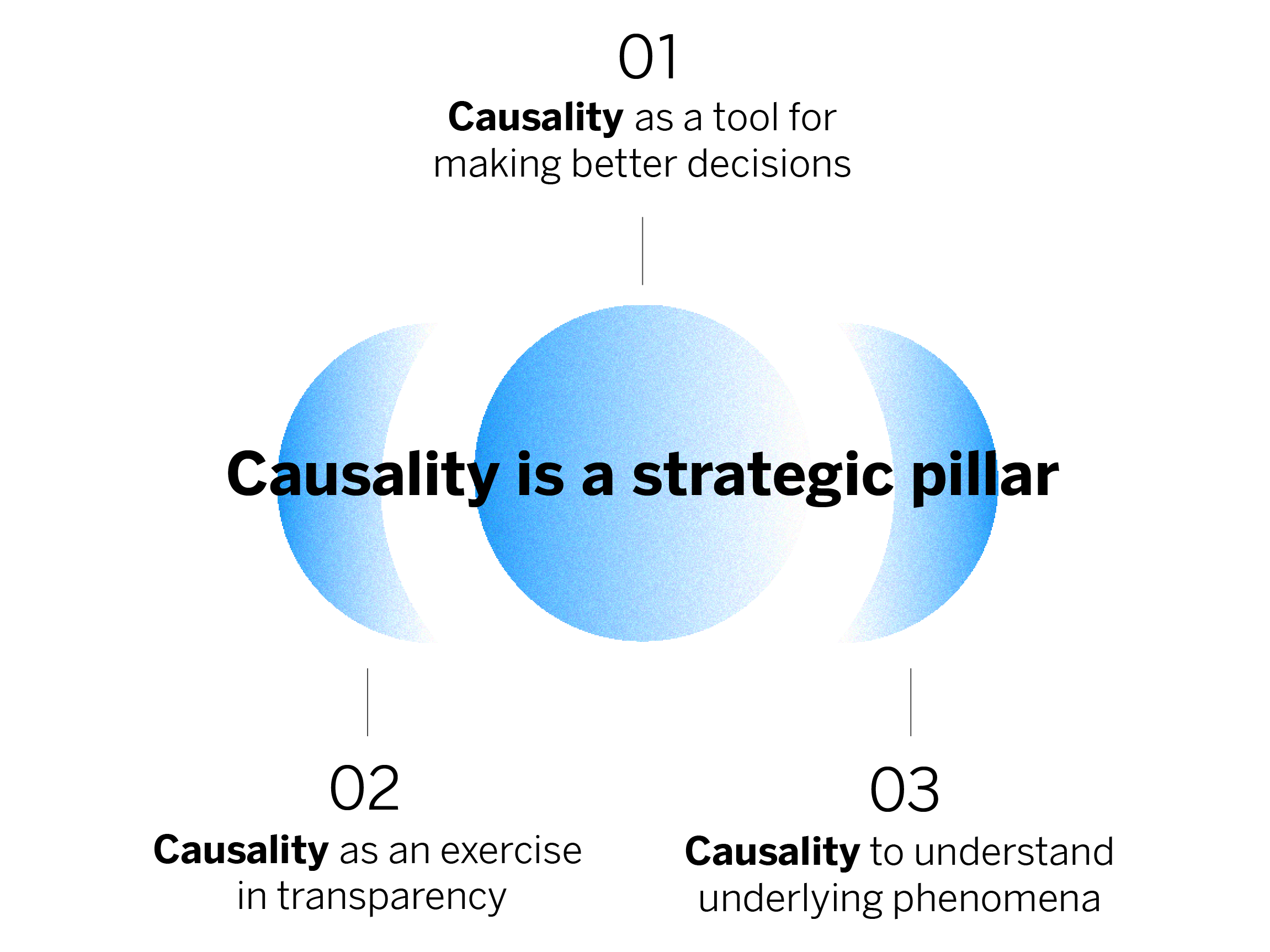
Causality is a strategic pillar due to its potential to transform decision-making at BBVA, enabling us to understand the underlying reasons behind each phenomenon. This approach signifies a cultural and technical shift and guides us towards the implementation of more informed strategies that align with the actual needs of our customers.
01

Causality as a tool for making better decisions
Causality applications enable us to make informed decisions and draw conclusions when random exploration is not feasible. This is crucial, especially in situations where A/B experiments are not possible.
02

Causality as an exercise in transparency
Causal inference aids in understanding the results produced by analytical models, validating that our actions are logical, and ensuring compliance with regulatory standards.
03

Causality as a way to understand underlying phenomena
Identifying causes instead of correlations enables us to understand phenomena from their origins. This scientific mindset, grounded in controlled experiments and long-term analysis, enhances our capacity to make evidence-based decisions.
Conclusions on causal inference
In both data science and life, simply observing patterns isn’t sufficient. The causal perspective helps us reveal the genuine drivers behind our customers’ engagement with the financial products we provide. By adopting this viewpoint, we steer clear of attributing the outcomes of our models to mere coincidences.
While the full moon itself doesn’t cause tides to rise, it serves as a visual cue that they will. Delving deeper into the underlying mechanisms and exploring actual causal connections enables us to create stronger solutions.
References
- Maestre, R., Muelas, D. (2024). “Assessing the Causal Effect of Digital Financial Management Tools on Financial Well-Being”. SSRN. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4895633↩︎